标签:split 用户 local 默认 ica blink app mac 选择
今天想记录下如何在windows环境下远程提交代码到spark集群上面运行。
spark集群搭建环境使Linux系统,但说实在,Linux系统因为是虚拟机的缘故运行IDE并不是很舒服,想要对python进行舒适的编程操作还不是一件容易事,所以今天记录下如何在Windows下进行spark编程。
需要按照集群方式安装,同时虚拟机需要保证能和Windows互联互通(能ping通),这样才能有最基本的环境。
具体操作按照教程按照集群版的的spark即可,注意的是slave文件内写上虚拟机地址或域名。如果成功安装将可以在Windows里显示如下界面。
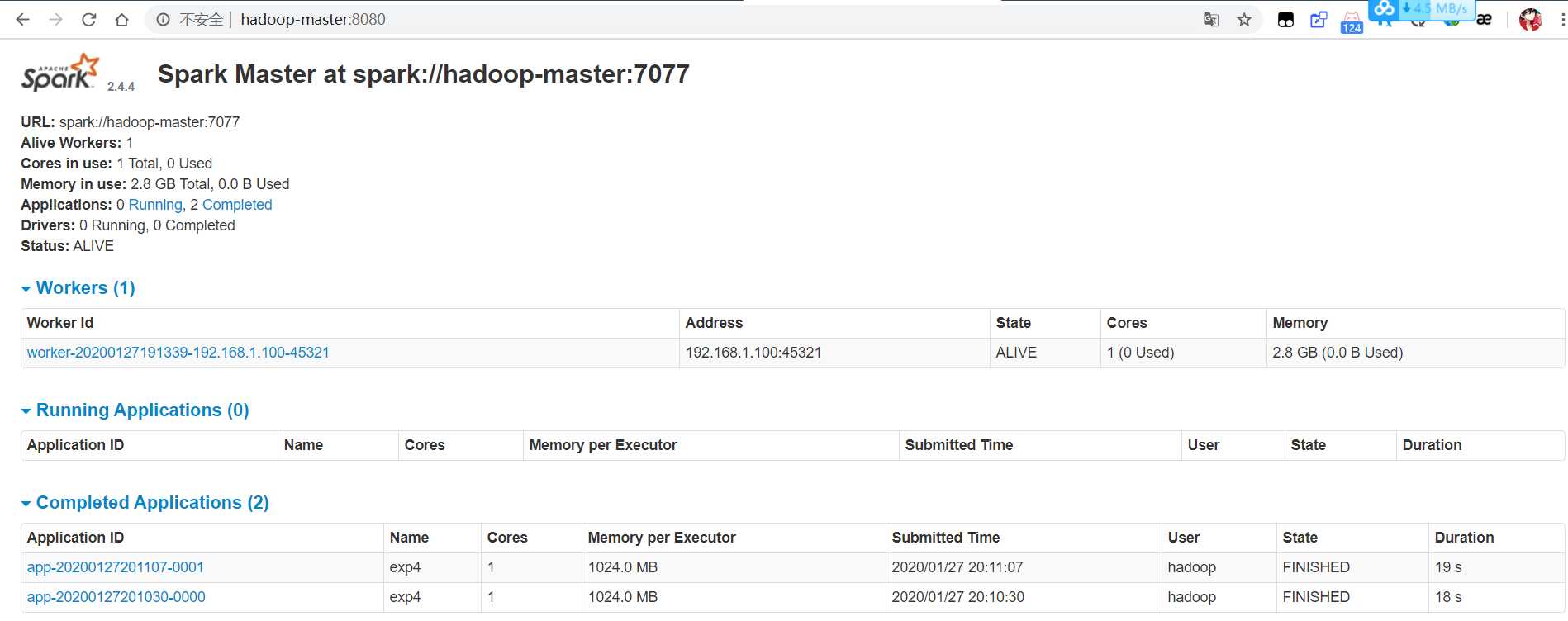
成功安装完成后就是安装py4j。
Ubuntu环境下——
apt install pip3 pip3 install py4j

首先我们需要配置PyCharm通服务器的代码同步,打开Tools | Deployment | Configuration
点击左边的“+”添加一个部署配置,输入名字,类型选SFTP

配置Connection。修改好host和用户名、密码就行,其余用默认配置。
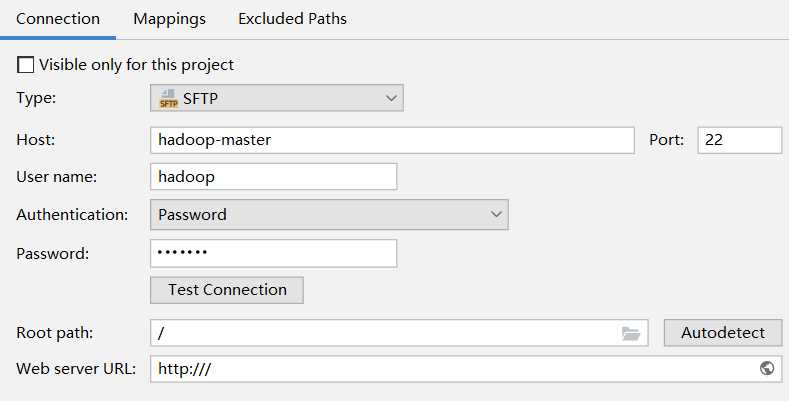
配置Mapping。我选用默认配置,让上传同步的代码放在临时文件夹中。
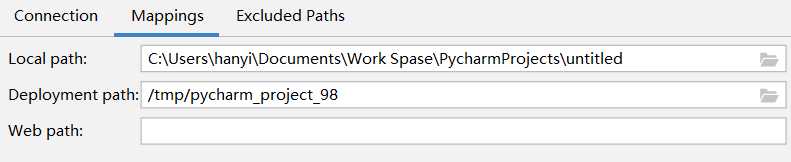
测试连接成功后就可以了。配置完成会在下方控制台显示传输信息。
打开File | Settings | Project: untitled | Project Interpreter,右侧点击Add。

选择SHH。
选择已有环境。
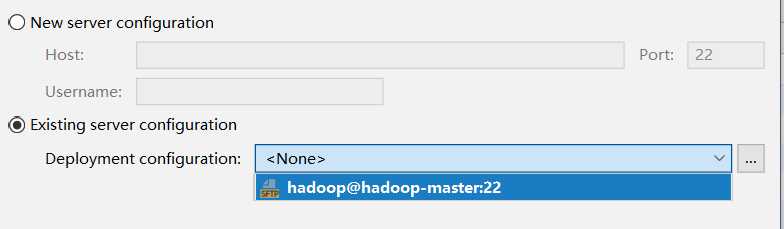
选择虚拟机中的python环境。
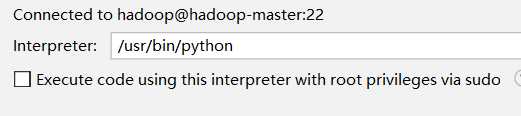
点击Finish后等待pycharm同步即可。
新建个py文件,右上角编辑启动配置。
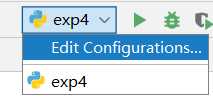
修改环境变量。

添加如下配置。
PYTHONPATH=/usr/local/spark/python;SPARK_HOME =/usr/local/spark/;JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162;HADOOP_HOME=/usr/local/hadoop/
PYTHONPATH选择spark文件夹内的python文件夹,SPARK_HOME 选择spark文件夹,JAVA_HOME可选,HADOOP_HOME可选。
配置完成后基本就可以用了。简单测试。
from pyspark import SparkContext sc = SparkContext(‘spark://hadoop-master:7077‘, ‘exp4‘) students = sc.textFile(‘file:///usr/local/spark/mycode/exp4/chapter5-data1.txt‘) qu1 = students.map(lambda line: (line.split(‘,‘)[0], 1)).reduceByKey(lambda a, b: a + b) print(qu1.collect()) qu2 = students.map(lambda line: (line.split(‘,‘)[1], 1)).reduceByKey(lambda a, b: a + b) print(qu2.collect())
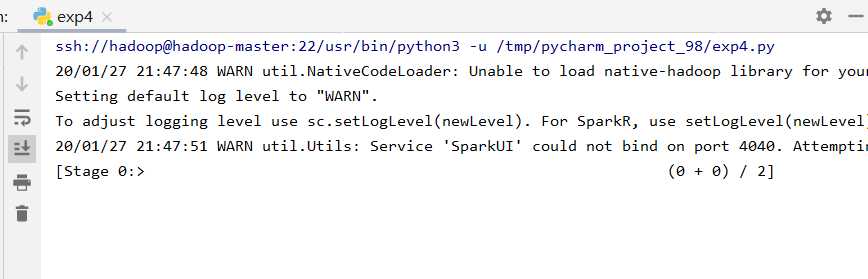
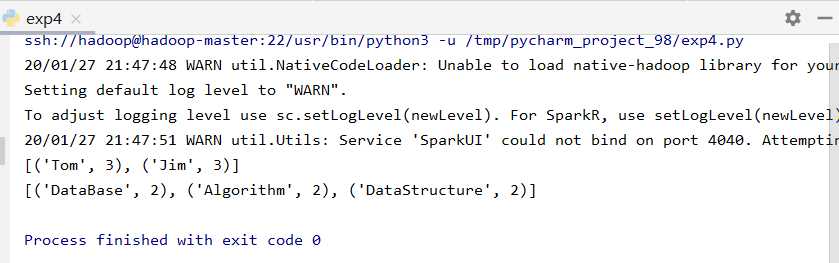
完成。
标签:split 用户 local 默认 ica blink app mac 选择
原文地址:https://www.cnblogs.com/limitCM/p/12236986.html