标签:sem tor 问题 标签 很多 输入 flatten str png
在上一节介绍了标记的解析,就相当于识别了一句话里有哪些词语,接下来就是把这些词语组成完整的句子,即拼装标记为语法树。
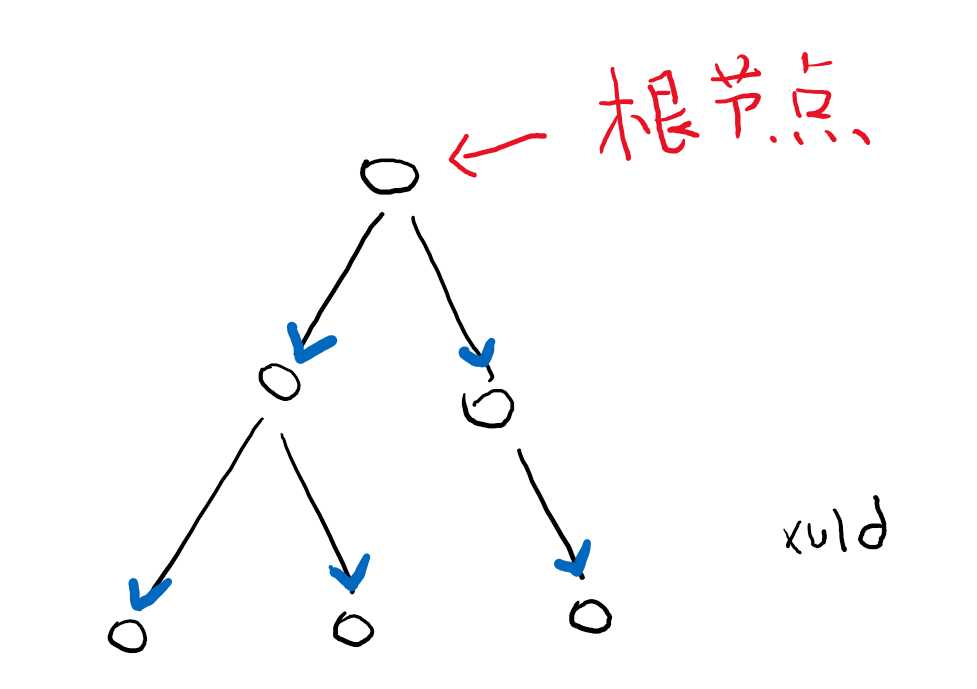
树是计算机数据结构里的专业术语。就像一个学校有很多年级,每个年级下面有很多班,每个班级下面有很多学生,这种组织结构就叫树。
很多人一提到树就想起二叉树,说明你压根不懂什么是树。二叉树只是树的一种。二叉树被用的最多的地方在试卷,请忘掉这个词。
从树中的任一个节点开始,都可以遍历这个节点的所有后代节点。因为节点不会出现循环关系,所以遍历树也不会出现死循环。
遍历节点的顺序有有很多,没特别说明的话,是按照先父节点、再子节点,同级节点则从左到右的顺序(图中编号顺序)。
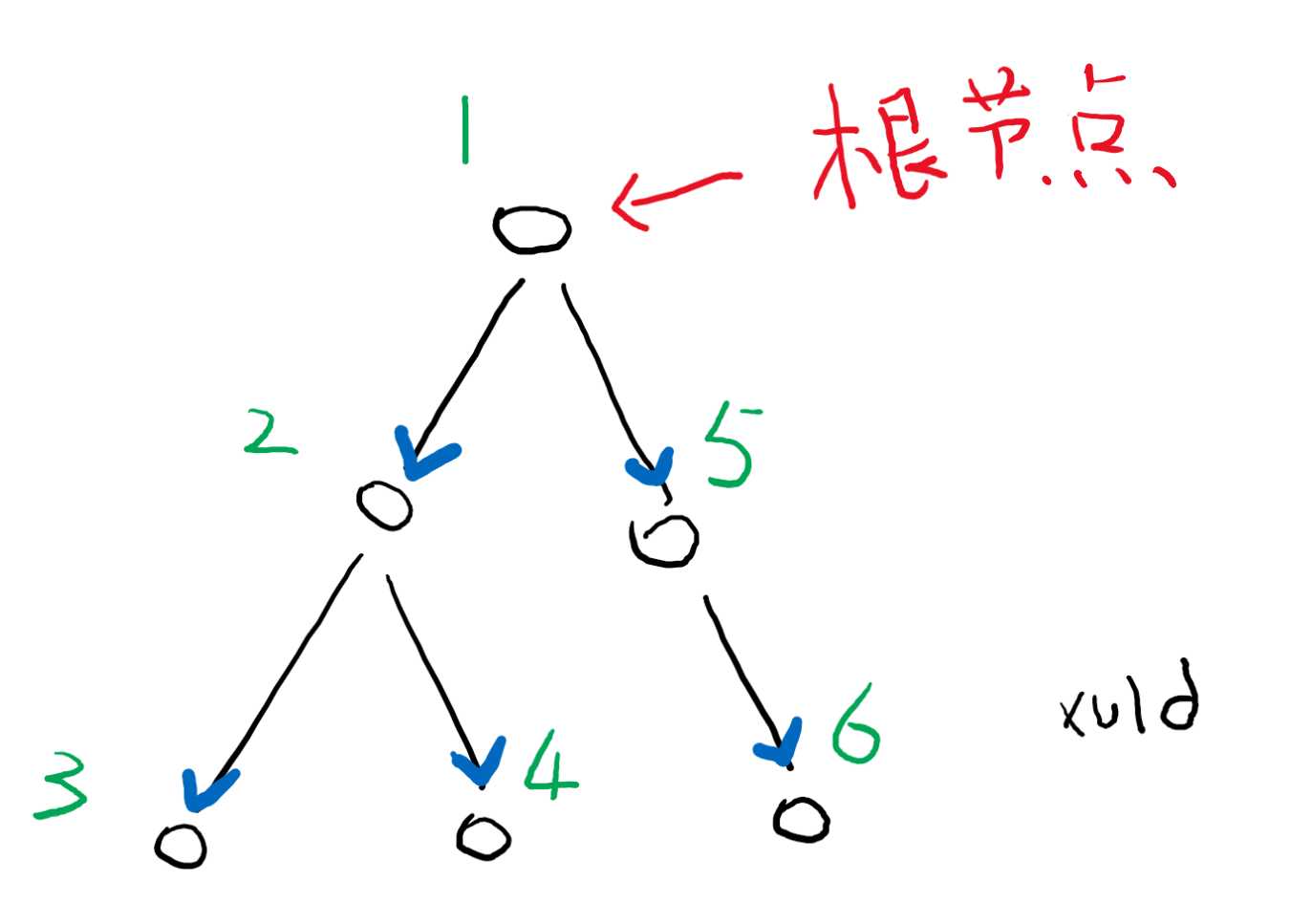
语法树用于表示解析之后的代码结构的一种树。
比如以下代码解析后的语法树如图:
var x = [‘l‘, [100]]
if (x) {
foo(x)
}
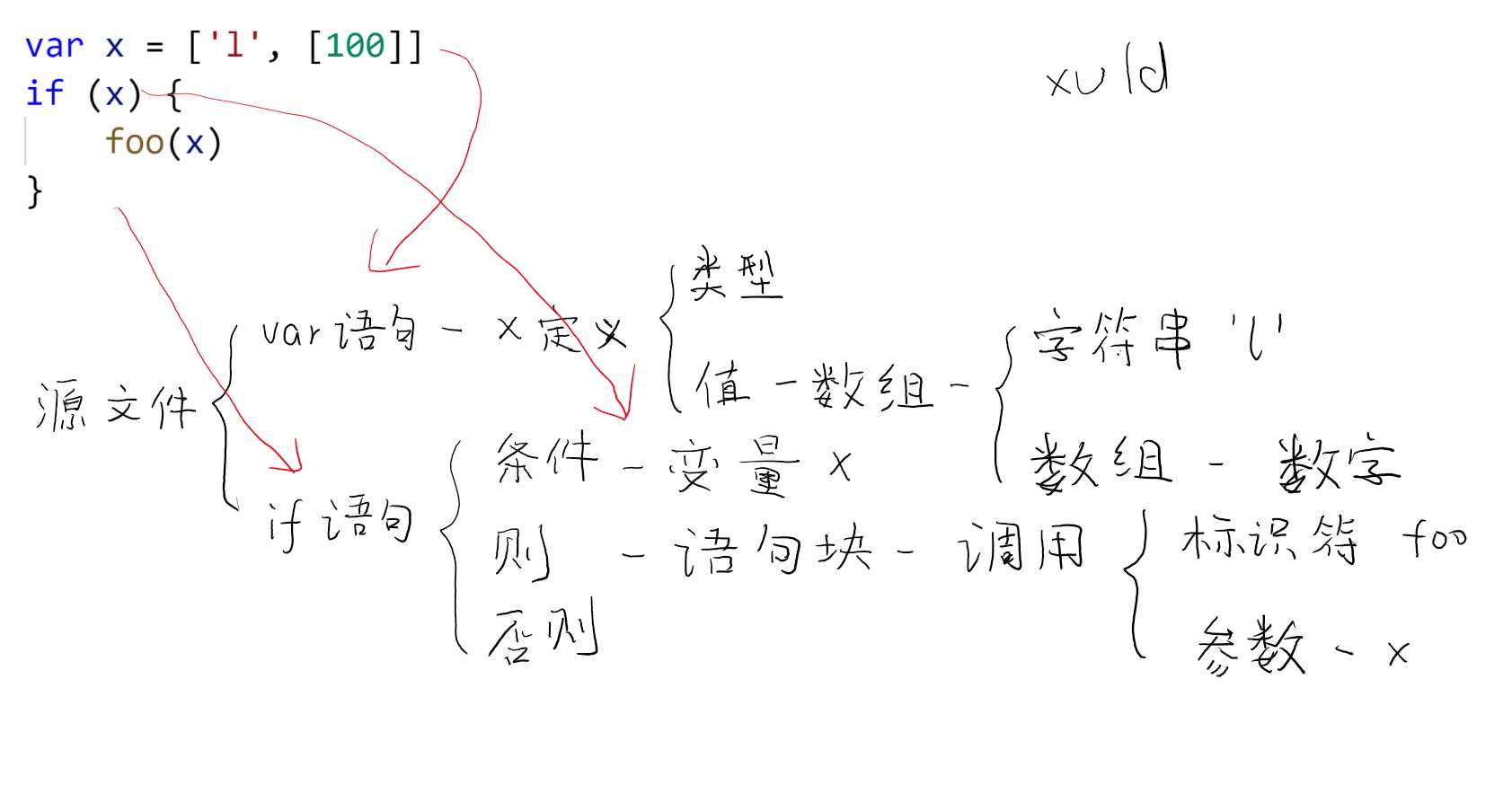
其中,源文件(Source File)是语法树的根节点。
语法树中有很多种类的节点,根据种类的不同,这些节点的子节点种类也会变化。比如:
TypeScript 中,节点有约 100 种,它们都继承 “Node” 接口:
export interface Node extends TextRange {
kind: SyntaxKind;
flags: NodeFlags;
parent: Node;
// ...(略)
}
Node 接口中 kind 枚举用于标记这个节点的种类。
TypeScript 将表示标记种类的枚举和表示节点种类的枚举合并成一个了(这可能也是导致很多人读不懂代码的原因之一):
export const enum SyntaxKind {
// ...(略)
TemplateSpan,
SemicolonClassElement,
// Element
Block,
EmptyStatement,
VariableStatement,
ExpressionStatement,
IfStatement,
DoStatement,
WhileStatement,
ForStatement,
ForInStatement,
ForOfStatement,
ContinueStatement,
BreakStatement,
// ...(略)
}
如果你深知“学而不思则罔”的道理,现在应该会思考这样一个问题:那到底有哪 100 种语法节点呢?
这里先推荐一个工具:https://astexplorer.net/
这个工具可以在左侧输入代码,右侧查看实时生成的语法树(以 JSON 方式展示)。读者可以在这个工具顶部选择“JavaScript”语言和“typescript”编译器,查看 TypeScript 生成的语法树结构。
为了帮助英文文盲们更好地理解语法类型,读者可参考:https://github.com/meriyah/meriyah/wiki/ESTree-Node-Types-Table
虽然语法节点种类很多,但其实只有四类:
在 TypeScript 中,节点命名比较规范,一般类型节点以 TypeNode 结尾;表达式节点以 Expression 结尾;语句节点以 Statement 结尾。
比如 if 语句节点:
export interface IfStatement extends Statement {
kind: SyntaxKind.IfStatement;
expression: Expression;
thenStatement: Statement;
elseStatement?: Statement;
}
鉴于有些读者对部分语法比较陌生,这里可以说明一些可能未正确理解的节点类型
export interface ExpressionStatement extends Statement, JSDocContainer {
kind: SyntaxKind.ExpressionStatement;
expression: Expression;
}
表达式是不能直接出现在最外层的,但以下代码是允许的:
var x = 1;
1 + 1; // 这是表达式
因为 1 + 1 是表达式,它们同时又是一个表达式语句。所以以上代码的语法树如图:

常见的赋值、函数调用语句都其实是一个表达式语句。
一对“{}”本身也是一个语句,称为块语句。一个块语句可以包含若干个语句。
export interface Block extends Statement {
kind: SyntaxKind.Block;
statements: NodeArray<Statement>;
/*@internal*/ multiLine?: boolean;
}
比如 while 语句的主体只能是一条语句:
export interface IterationStatement extends Statement {
statement: Statement;
}
export interface WhileStatement extends IterationStatement {
kind: SyntaxKind.WhileStatement;
expression: Expression;
}
但 while 里面明明是可以写很多语句的:
while(x_d) {
var a = 120;
var b = 100;
}
本质上,当我们使用 {} 时,就已经使用了一个块语句,while 的主体仍然是一个语句:块语句。其它语句都是块语句的子节点。
export interface LabeledStatement extends Statement, JSDocContainer {
kind: SyntaxKind.LabeledStatement;
label: Identifier;
statement: Statement;
}
通过标签语句可以为语句命名,比如:
label: var x = 120;
命名后有啥用?可以在 break 或 continue 中引用该名称,以此实现跨级 break 和 continue 的效果:
export interface BreakStatement extends Statement {
kind: SyntaxKind.BreakStatement;
label?: Identifier; // 跳转的标签名
}
export interface ContinueStatement extends Statement {
kind: SyntaxKind.ContinueStatement;
label?: Identifier; // 跳转的标签名
}
比如 x + y * z 中,需要先算乘号。生成的语法树节点如下:
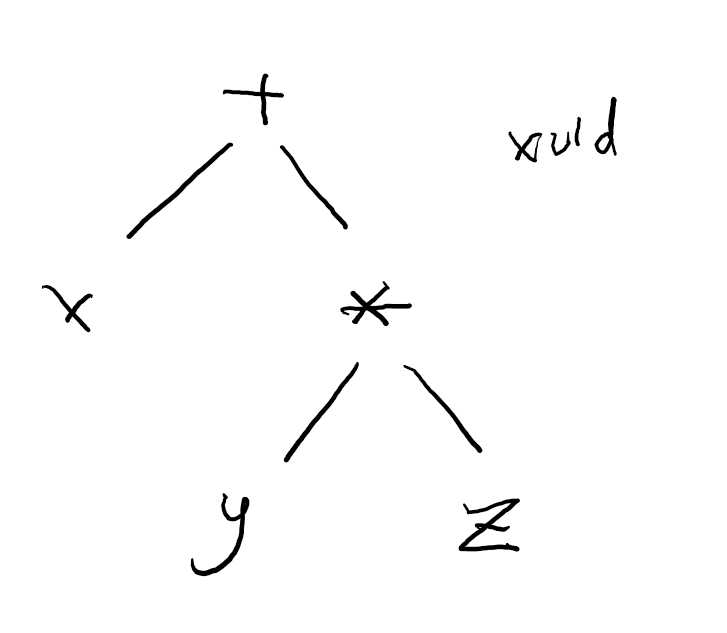
通过节点的层次关系,实现了这种优先级的效果(因为永远不会把图里的 x 和 y 先处理)。
因此创建语法树的同时,也就处理了优先级的问题,括号完全可以从语法树中删除。
一个复杂的类,也能用语法树表示?
当然,任何语法最后都是用语法树表达的,只不过类确实复杂一些:
export interface Declaration extends Node {
_declarationBrand: any;
}
export interface NamedDeclaration extends Declaration {
name?: DeclarationName;
}
export interface ClassLikeDeclarationBase extends NamedDeclaration, JSDocContainer {
kind: SyntaxKind.ClassDeclaration | SyntaxKind.ClassExpression;
name?: Identifier;
typeParameters?: NodeArray<TypeParameterDeclaration>;
heritageClauses?: NodeArray<HeritageClause>;
members: NodeArray<ClassElement>;
}
export interface ClassDeclaration extends ClassLikeDeclarationBase, DeclarationStatement {
kind: SyntaxKind.ClassDeclaration;
/** May be undefined in `export default class { ... }`. */
name?: Identifier;
}
类、函数、变量、导入声明严格意义上是独立的一种语法分类,但鉴于它和其它语句用法一致,为了便于理解,这里把声明作语句的一种看待。
当源代码被解析成语法树后,源代码就不再需要了。如果后续流程发现一个错误,编译器需要向用户报告,并指出错误位置。
为了可以得到这个位置,需要将节点在源文件种的位置保存下来:
export interface TextRange {
pos: number;
end: number;
}
export interface Node extends TextRange {
kind: SyntaxKind;
flags: NodeFlags;
parent: Node;
// ...(略)
}
通过节点的 parent 可以找到节点的根节点,即所在的文件;通过节点的 pos 和 end 可以确定节点在源文件的行列号(具体已经在第二节:标记位置 中介绍)。
为了方便程序中遍历任意节点,TypeScript 提供了一个工具函数:
/**
* Invokes a callback for each child of the given node. The ‘cbNode‘ callback is invoked for all child nodes
* stored in properties. If a ‘cbNodes‘ callback is specified, it is invoked for embedded arrays; otherwise,
* embedded arrays are flattened and the ‘cbNode‘ callback is invoked for each element. If a callback returns
* a truthy value, iteration stops and that value is returned. Otherwise, undefined is returned.
*
* @param node a given node to visit its children
* @param cbNode a callback to be invoked for all child nodes
* @param cbNodes a callback to be invoked for embedded array
*
* @remarks `forEachChild` must visit the children of a node in the order
* that they appear in the source code. The language service depends on this property to locate nodes by position.
*/
export function forEachChild<T>(node: Node, cbNode: (node: Node) => T | undefined, cbNodes?: (nodes: NodeArray<Node>) => T | undefined): T | undefined {
if (!node || node.kind <= SyntaxKind.LastToken) {
return;
}
switch (node.kind) {
case SyntaxKind.QualifiedName:
return visitNode(cbNode, (<QualifiedName>node).left) ||
visitNode(cbNode, (<QualifiedName>node).right);
case SyntaxKind.TypeParameter:
return visitNode(cbNode, (<TypeParameterDeclaration>node).name) ||
visitNode(cbNode, (<TypeParameterDeclaration>node).constraint) ||
visitNode(cbNode, (<TypeParameterDeclaration>node).default) ||
visitNode(cbNode, (<TypeParameterDeclaration>node).expression);
case SyntaxKind.ShorthandPropertyAssignment:
return visitNodes(cbNode, cbNodes, node.decorators) ||
visitNodes(cbNode, cbNodes, node.modifiers) ||
visitNode(cbNode, (<ShorthandPropertyAssignment>node).name) ||
visitNode(cbNode, (<ShorthandPropertyAssignment>node).questionToken) ||
// ...(略)
}
}
forEachChild 函数只会遍历节点的直接子节点,如果用户需要递归遍历所有子节点,需要递归调用 forEachChild。forEachChild 接收一个函数用于遍历,并允许用户返回一个 true 型的值并终止循环。
掌握语法树是掌握整个编译系统的基础。你应该可以深刻地知道语法树的大概样子,并清楚每种语法的语法树结构。如果还没有彻底掌握,可以使用上文推荐的工具。
下一节将介绍生成语法树的全过程。【不定时更新】
标签:sem tor 问题 标签 很多 输入 flatten str png
原文地址:https://www.cnblogs.com/xuld/p/12238167.html