标签:描述 应该 正则 那是 等于 span 删除 理由 线性
你应该知道了 怎样应用一种 事实上是线性回归的一个变体 来预测不同用户对不同电影的评分值 这种具体的算法叫 ”基于内容的推荐“
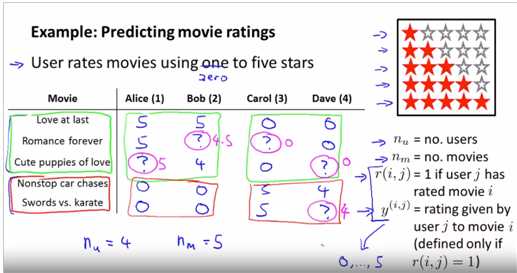
我们开发一个推荐系统 主要工作就是 想出一种学习算法 能够帮我们自动地 填上这些缺失的数值

假如说 对于这个例子 你已经知道Alice的 参数向量θ(1) 后面我们还会 详细讲到 这个参数是怎么得到的

为了学习参数向量θ(j) 我们应该怎么做呢? 这是一个基本的线性回归问题
因此我们要做的 就是选择一个参数向量θ(j) 使得预测的结果 这里 尽可能接近 我们在训练集中的观测值 。n为每一部电影的特征数
你会得到一个很好的θ(j)的估计值
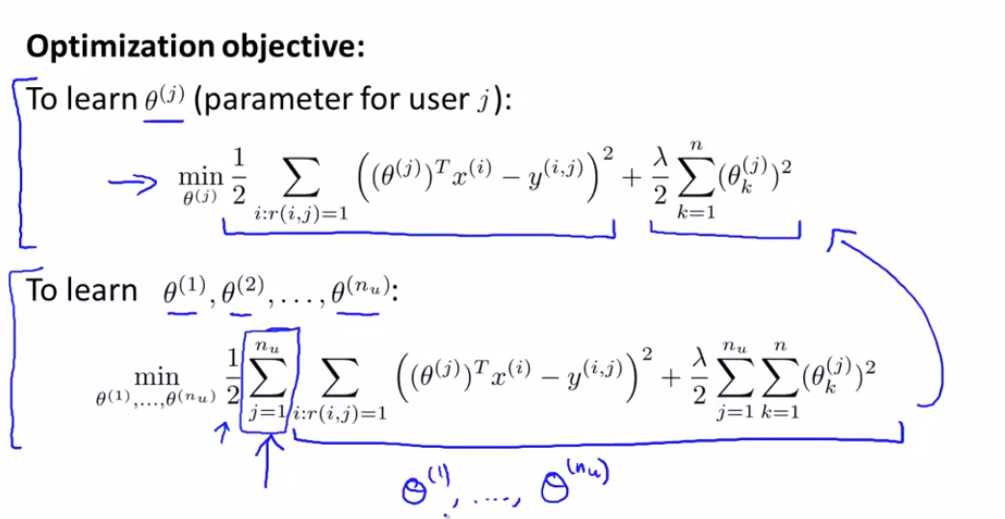

对于推荐系统 我要把符号稍微变化一下 为了让数学更简单 我要去掉这个m(j)
如果你觉得这个 梯度下降的更新 看起来跟之前 线性回归差不多的话 那是因为这其实就是线性回归
唯一的一点区别 是在线性回归中 我们有1/m项 实际上这里我们也有 1/m(j)项 但在前面我们 推导最优化目标函数时
我们忽略了这个项 因此这里就没有了 除此之外 实际上就是 对所有的训练样本求和 预测误差乘以 xk 加上正则化项
所以 如果你用 梯度下降法的话 你可以这样 最小化代价函数J 来学习出所有的参数
当然 用这些微分项 如果你愿意的话 你也可以把它们用在 更高级的优化算法里
比如聚类下降 或者L-BFGS(Limited-memory Broyden–Fletcher–Goldfarb–Shanno Algorithm) 或者别的方法 来最小化代价函数J



加上一个正则化项 来防止特征的数值 变得过大

迭代 不停重复 优化θ x θ x θ 这非常有效 如果你 这样做的话 你的算法将会收敛到
一组合理的电影的特征 以及一组对合理的 对不同用户参数的估计
协同过滤算法指的是 当你执行这个算法时 你通过一大堆用户 得到的数据
这些用户实际上在高效地 进行了协同合作 来得到每个人 对电影的评分值 只要用户对某几部电影进行评分 每个用户就都在帮助算法 更好的学习出特征
这样 通过自己 对几部电影评分之后.我就能帮助系统更好的学习到特征 这些特征可以 被系统运用 为其他人 做出更准确的电影预测
协同的另一层意思 是说每位用户 都在为了大家的利益 学习出更好的特征 这就是协同过滤

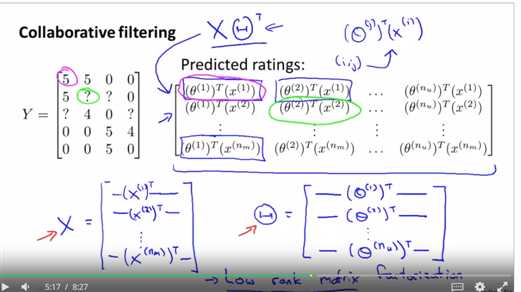
这和 前面的算法之间 唯一的不同是 不需要反复计算 就像我们之前所提到的 先关于 θ 最小化 然后关于 x 最小化 然后再关于 θ 最小化 再关于 x 最小化... 在新版本里头 不需要不断地在 x 和 θ 这两个参数之间不停折腾 我们所要做的是 将这两组参数 同时化简 而先前我们所有的 特征值x 是 n+1 维 包括截距 删除掉x0 我们现在只会有 n 维的 x 同样地 因为参数 θ 是 在同一个维度上 所以 θ 也是 n 维的 因为如果没有 x0 那么 θ0 也不再需要 我们将这个前提移除的理由是 因为我们现在是在 学习所有的特征 所以我们没有必要 去将这个等于一的特征值固定死 因为如果算法真的需要 一个特征永远为1 它可以选择靠自己去获得1这个数值 所以如果这算法想要的话 它可以将特征值 x1 设为1 所以没有必要 去将1 这个特征定死 这样算法有了 灵活性去自行学习 所以 把所有讲的这些合起来 即是我们的协同过滤算法


协同过滤 向量化

均值归一化

我们还是没有任何好方法 来把电影推荐给她 因为你知道
预测结果是所有这些电影 都会被 Eve 给出一样的评分 所以没有一部电影 拥有高一点儿的预测评分 让我们能推荐给她 所以这不太好

每个电影 在新矩阵Y中的 平均评分都是0
接下来我要做的就是 对这个评分数据集 使用协同过滤算法 所以我要假设 这就是我从用户那儿
得到的数据 或者假设它们就是 我从用户那儿得到的实际评分 我要把这个当做我的数据集 用它来学习
我的参数 θ(j) 和特征变量 x(i) 就是用这些均值归一化后的电影评分来学习
当我想要做 电影评分预测时 我要做的步骤如下 对用户j对电影i的评分 我要预测它为 θ(j) 转置乘以 x(i) 其中 x 和 θ 都是 均值归一化的数据集中学习出的参数
但是因为我已经对数据集 减去了均值 所以为了 给电影i预测评分 我要把这个均值加回来 所以我要再加回 µi
具体来说 如果用户5 Eve 之前幻灯片里的的描述仍然成立 Eve 从来没有 给任何电影打分
所以学习到的用户5的参数 仍然还是 会等于 0 所以我们会得到的是 对特定的电影 i 我们预测 Eve 的评分是 θ(5) 转置乘以 x(i)
然后再加上 µi 所以如果 θ(5) 等于0的话 这第一部分就会等于0 所以对电影 i 的评分 我们最终会预测为 µi 这实际上是说得通的
如果 Eve 没给任何电影评分 我们就对这个新用户 Eve 一无所知 我们要做的就是预测 她对每个电影的评分 就是这些电影所得的平均评分
标签:描述 应该 正则 那是 等于 span 删除 理由 线性
原文地址:https://www.cnblogs.com/tingtin/p/12238525.html