标签:整合 info 知识图谱 日期时间 业务需求 工程 自然语言处理技术 wot 技术
一、NER简介
NER又称作专名识别,是自然语言处理中的一项基础任务,应用范围非常广泛。命名实体一般指的是文本中具有特定意义或者指代性强的实体,通常包括人名、地名、组织机构名、日期时间、专有名词等。NER包含以下model:
NER系统就是从非结构化的输入文本中抽取出上述实体,并且可以按照业务需求识别出更多类别的实体,比如产品名称、型号、价格等。因此实体这个概念可以很广,只要是业务需要的特殊文本片段都可以称为实体。命名实体识别技术是信息抽取、信息检索、知识图谱、机器翻译、问答系统等多种自然语言处理技术必不可少的组成部分。
二、NER的技术发展
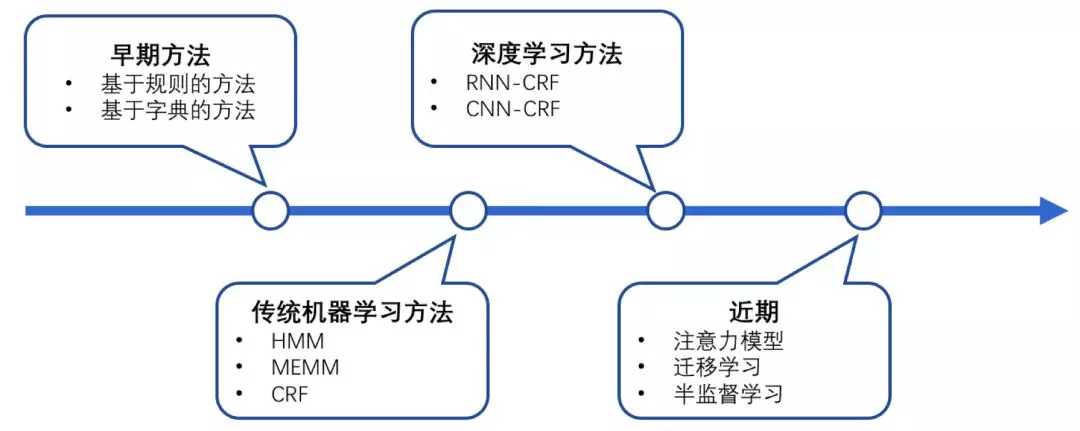
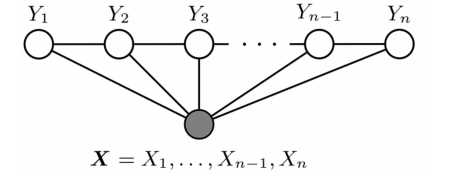
早期基于规则、字典的方法就不细说。目前使用最广泛的应该是基于统计的方法(对语料库的依赖比较大),利用大规模的语料来学习出标注模型,来对各个位置进行标注。CRF是NER目前的主流模型,它的目标函数不仅考虑输入的状态特征函数,而且还包含了标签转移特征函数。在已知模型时,给输入序列求预测输出序列即求使目标函数最大化的最优序列,是一个动态规划问题,可以使用Viterbi算法解码来得到最优标签序列。CRF的优点在于其为一个位置进行标注的过程中可以利用丰富的内部及上下文特征信息。
随着深度学习的发展,DL-CRF模型做序列标注被提出。在神经网络的输出层接入CRF层(重点是利用标签转移概率)来做句子级别的标签预测,使得标注过程不再是对各个token独立分类。
三、BiLSTM-CRF
LongShort Term Memory网络一般叫做LSTM,是RNN的一种特殊类型,可以学习长距离依赖信息。LSTM 由Hochreiter &Schmidhuber (1997)提出,并在近期被Alex Graves进行了改良和推广。在很多问题上,LSTM 都取得了相当巨大的成功,并得到了广泛的使用。LSTM 通过巧妙的设计来解决长距离依赖问题。
所有 RNN 都具有一种重复神经网络单元的链式形式。在标准的RNN中,这个重复的单元只有一个非常简单的结构,例如一个tanh层。
LSTM 同样是这样的结构,但是重复的单元拥有一个不同的结构。不同于普通RNN单元,这里是有四个,以一种非常特殊的方式进行交互。
LSTM通过三个门结构(输入门,遗忘门,输出门),选择性地遗忘部分历史信息,加入部分当前输入信息,最终整合到当前状态并产生输出状态
应用于NER中的biLSTM-CRF模型主要由Embedding层(主要有词向量,字向量以及一些额外特征),双向LSTM层,以及最后的CRF层构成。实验结果表明biLSTM-CRF已经达到或者超过了基于丰富特征的CRF模型,成为目前基于深度学习的NER方法中的最主流模型。在特征方面,该模型继承了深度学习方法的优势,无需特征工程,使用词向量以及字符向量就可以达到很好的效果,如果有高质量的词典特征,能够进一步获得提高。
四、总结
将神经网络与CRF模型相结合的CNN/RNN-CRF成为了目前NER的主流模型。对于CNN与RNN,并没有谁占据绝对优势,各有各的优点。由于RNN有天然的序列结构,所以RNN-CRF使用更为广泛。基于神经网络结构的NER方法,继承了深度学习方法的优点,无需大量人工特征。只需词向量和字向量就能达到主流水平,加入高质量的词典特征能够进一步提升效果。对于少量标注训练集问题,迁移学习,半监督学习应该是未来研究的重点。
标签:整合 info 知识图谱 日期时间 业务需求 工程 自然语言处理技术 wot 技术
原文地址:https://www.cnblogs.com/chenyusheng0803/p/12240961.html