标签:numpy compare 出错 展示 完成 内容 bec slice 帮助
TensorFlow是咱们机器学习领域非常常用的一个组件,它在数据处理,模型建立,模型验证等等关于机器学习方面的领域都有很好的表现,前面的一节我已经简单介绍了一下TensorFlow里面基础的数据结构即:Tensor和Dataset; 这里咱们开始介绍TensorFlow的建模过程以及验证模型的一些简单方法。其实无论是sklearn还是TensorFlow,他们的模型建立过程都是相似的,都是经历columns类型声明,模型定义,数据训练,validation等等几个步骤。前面的几节内容我已经简单的介绍了如何用sklearn建立tree_based模型,这里我主要是想演示TensorFlow的应用,所以我就用linear regressor来当做例子来演示TensorFlow是如何从数据加载一直到数据验证的阶段。至于线性拟合的实现的具体细节,我在下一节的内容会从数学的角度具体解释的。本节内容所使用的数据都是来自于网络中,大家可以忽略具体的数据的意思,主要的了解TensorFlow的应用过程,不必过于纠结于模型的细节部分,模型的细节我会在随后的章节解释。好了,那么咱们现在开始吧
第一步:数据准备
顾名思义,就是咱们准备数据的过程,这里包括有missing value handling, categorical data encoding,data split, data permutation等等内容,这一步咱们要将咱们将来模型训练所用到的数据都能准备好。这个准备过程无非也就是上面的这些步骤,咱们可以看下面的代码演示
cali_housing_dataset_original = pd.read_csv("https://download.mlcc.google.com/mledu-datasets/california_housing_train.csv") cali_housing_dataset_original["median_house_value"] /= 1000.0 #create a random generator generator = np.random.Generator(np.random.PCG64()) #permutate the data frame cali_housing_dataset_permutation = cali_housing_dataset_original.reindex( generator.permutation(cali_housing_dataset_original.index) ) cali_housing_dataset_permutation.describe() #select the features that we will use in the model trainning process my_feature = cali_housing_dataset_permutation[["total_rooms"]] #select the targets of the dataset targets = cali_housing_dataset_permutation[["median_house_value"]]
这里我就不演示那些feature engineering的过程,那些内容太多,大家可以看我之前的博客,这里主要是想向大家演示一下permutation的过程。因为最新的numpy对于randomize的过程已经有更新了,不再使用的那些老的API了,numpy中最新的randomize的过程是通过创建2个generator来实现随机过程和随机数的生成了,这两个generator一个个是bit generator, 就如咱们上面代码中的PCG64(), 它能产生一个随机的bit stream, 根据numpy的官方文档,虽然有很多种bit generator,但是PCG64是最稳定的一种;另外一个就是Generator, 它是通过np.random.Generator()函数来实例化一个对象的,它能将bit generator产生的bit stream转化成数字。这里的数据咱们就选择一个最最简单的linear regression的方式,那就是只选择一个feature,那就是total_rooms; 咱们的target是median_house_value。
第二步:定义feature 类型 和 optimizer
既然咱们的数据都准备好了,那么之后那么得定义一下咱们数据的类型(每一个column的类型都得定义),将来在咱们定义模型的时候咱们也得将columns的信息传递给咱们的模型对象;以及用什么optimizer将来来训练咱们的模型,这个optimizer将来也得传递给咱们的模型对象。 具体optimizer是什么我下面会慢慢讲的。为了方便演示,还是先上代码给大家看
#indicates what is the data type of the feature to tensorflow feature_columns = [tf.feature_column.numeric_column("total_rooms")]
#using stochastic gradient descent as the optimizer for our model #to ensure the magtitute of gradient do not become too large, we apply clipping_norm to our optimizer my_optimizer = tf.optimizers.SGD(learning_rate = 0.0000001, clipnorm=5.0)
从上面的代码可以看出,第一句是声明咱们feature_columns里面只有一个numeric_column,记住每一个column都有一个feature_column对象,这里因为咱们只选取了一个feature是total_rooms,所以咱们这里就一个tf.feature_column对象。这里的第二行代码是咱们的重点,也是以后优化模型中经常要调整的部分,这里咱们可以看出,这里的optimizer是一个SGD, SGD是stochastic gradient descent的缩写,就是每一次计算咱们的gradient descent的时候,咱们只选取一组数据进行计算,如果每一次计算gradient descent的时候咱们都用整个数据进行计算,那么咱们的计算机是负担不起的,消耗的存储空间和计算能力都太大了,因为在实际中咱们的数据集的数量经常都是以万为单位的。具体计算gradient descent的过程我会在下一节中讲述模型训练过程中演示的。咱们可以看出来,SGD中还有两个参数,分别是learning_rate和clipnorm, 咱们知道,当我们在训练我们的模型的时候,我们需要逐步的训练很多次,知道咱们的gradient descent趋于0是才停止,咱们的每一步的大小都要合理,如果learning_rate太小,咱们训练的步数就会太多,影响咱们的效率;如果learning_rate太大,则可能导致咱们训练模型的过程不能converge,就是永远找不到那个最小值,从而导致训练的模型失败;为了防止咱们咱们的gradient太大,我们这里不单单用learning_rate来限制,咱们还加了一个clipnorm来限制咱们的gradient magtitute大小,防止咱们fail to converge, 这相当于一个双重保险。
第三步:定义一个模型model
将上面的参数都定义完成后,咱们就得定义一下咱们的模型啦,TensorFlow提供了大量的模型可供使用,几乎所有主流的机器学习的模型和深度学习相关的模型,TensorFlow几乎实现全覆盖了,具体咱们可以去他的官网查询, 他的官网地址是:https://www.tensorflow.org/api_docs/python/tf ,记住在TensorFlow中,他的模型都在tf.estimator这个模块中。因为这里是咱们讲述用TensorFlow开发机器学习应用的入门,咱们就选一个最简单的模型linear regressor模型来演示
linear_regressor = tf.estimator.LinearRegressor( feature_columns = feature_columns, optimizer = my_optimizer )
这里咱们可以看出是如何初始化一个LinearRegressor对象的,同样的,咱们可以看出来它初始化的时候也是需要传递feature_columns和optimizer这2个参数的,而这两个参数正是咱们第二步中所初始化的,可以说是环环相扣啊,哈哈,也可以看出咱们前面定义初始化的一个对象都是没有多余的,都是要用到的。这两个参数分别告诉了咱们的模型咱们数据columns的类型以及用什么optimizer来训练这2个信息。
第四步:数据源input_fn
既然咱们的原始数据准备好了,模型也都定义好了,如果需要训练咱们的模型,咱们还差什么呢?对了就是将咱们的原始数据(这里的例子是dataframe)转化成TensorFlow中的dataset,并将转化后的data传递给咱们的模型,让咱们之前定义的模型用这些数据去训练。这里应该也是咱们用TensorFlow来建模的一个核心部分了,咱们先看代码演示,然后我会逐个详细解释的
def my_input(features, targets, batch_size=500, shuffle=True, num_epochs=None): """ epochs: while trainning, in the case of steps is larger than the length of dataset, we set the epochs to None, which means repeat forever. However, in trainning process, we have the steps to control the total number of iterations. While in the case of making predictions of a given dataset, we must set epochs to 1 and shuffle to False. Because we only want the input function return the dataset once, otherwise the function will keep returnning the results forvere once and once again. shuffle: in the trainning process, in order to balance the dataset, we set it to True. However while in prediction process, we have to set it to False, which could help us to evaluate the outputs. For example, if the outputs are shuffled, we have no way to compare the outputs to our original lables. """ #convert panda dataframe to a dict of Numpy array features = {key:tf.multiply(np.array(value),1) for key,value in dict(features).items()} #construct a dataset ds = tf.data.Dataset.from_tensor_slices((features,targets)) ds = ds.batch(batch_size).repeat(num_epochs) if shuffle: ds = ds.shuffle(buffer_size = 10000) return ds
这里有几个核心的参数我需要解释一下,首先features和target两个参数很明显就是咱们第一步中获取的数据,分别是用来训练这个模型的特征变量和label;重点这里解释一下batch_size, shuffle 和 num_epochs这三个参数,这三个参数在咱们TensorFlow的整个学习过程中都得用到,绝对的重点,不容怀疑。首先咱们来看batch_size, 因为SGD每一次都只会选用一条数据来计算咱们的gradient(训练模型),而咱们的数据具有很强的随机性,那么就会导致咱们的模型最后很可能不可用,但是如果咱们每一个step都选用整个dataset来训练模型,又会导致咱们的训练过程非常漫长,那么聪明的人类就自然而然的想到了咱们可以每一次选用一定数量的数据来训练模型,一般的数据量咱们大致的范围都是在10-10000之间,这种方式就成为mini-batch SGD, 在这里咱们就是采用了这种方式,咱们每一次选用500条数据来训练咱们的模型,这是通过设置batch_size的值来实现的。对于shuffle这个参数呢,也是为了打乱咱们的数据来进行训练,最终的目的也是为了能帮助咱们训练出更加精确的模型,防止咱们的数据分布不合理导致模型有偏差,它里面的buffer_size的意思是先从ds中选中buffer_size个数据(这些数据暂时还是有序的,顺序和ds中一样),然后iterate的时候呢,就从这个buffer中随机的选择数据(这个选择数据的过程就是无序的选择了,实现了随机的目的)。最后还有这个repeat(num_epochs)的函数,首先repeat函数在training的过程中一定需要的,因为当咱们设置steps步数参数的时候,如果steps的总数要多余整个dataset的数据量的时候,那么这时候咱们一定得重复利用咱们的dataset来达到训练的目的,否则咱们的数据源的数据量不够了,会出错的,这就是为什么需要repeat的原因,至于num_epochs是来控制重复的次数的,一般在training阶段咱们将它设置成None, 意思就是无限循环,知道training中的steps全部走完位置,如果在predict阶段,咱们一般就设置成1,因为咱们验证阶段不需要重复的,同样的在predict的时候,数据源函数中的shuffle也要设置成False的,否则predict的结果都是乱序的,无法跟原来的数据进行对比了。前面几个参数在咱们模型训练过程中可以说是最重要的参数了,这里说的也比较多,所以一点得用心搞明白。
第五步:训练模型 training
既然上面咱们把模型的参数都设置好了,数据源也定义好了,那么接下来咱们的任务就是训练咱们定义的模型了,这个过程在代码中是很简单的,但它内部做的工作是很多的,它需要计算在每个维度(feature)上的gradient descent,知道它趋于0为止,它的计算细节我会在接下来的一个章节中展示出来,咱们先看代码
linear_regressor.train( input_fn = lambda:my_input(my_feature, targets), steps = 1000 )
是不是很简单,咱们只需要将数据源函数作为参数传递给他,并且设置一个steps就可以了。这里input_fn我就不解释了,简单说一下steps,steps指的是咱们训练的步数,咱们每计算一次gradient descent,就算一步,这里指咱们最多计算1000次,即使1000的时候gradient descent不等于0咱也停止咱的训练过程,然后咱们可以重新设置optimizer中的learning_rate来重新训练。
第六步:predict和evaluate
经过前面五步后,咱们已经训练出来了一个模型,那么接下来咱们需要用这个模型来预测一下数据,并且看看它的效果,去evaluate一下这个模型。正常的情况下咱们会将数据split成training data 和 validation data,这里我为了方便,咱就直接用training data来演示如何predict还有如何evaluate咱们的模型。简单的代码如下
#create a input function for prediction prediction_input_fn = lambda:my_input(my_feature,targets,shuffle=False,num_epochs=1) #prediction predictions = linear_regressor.predict(input_fn = prediction_input_fn) predictions = np.array([item["predictions"][0] for item in predictions]) #errors MSE mean_squared_error(targets,predictions)
在咱们做prediction的时候,咱们也是需要数据源input_fn的,在prediction的时候,shuffle=False, num_epochs=1; 然后调用这个模型linear_regressor的predict方法,将数据源函数传递给他, 它返回的结果是一个list,这个list里面的element是一个dictionary,这个dictionary的key值“predictions”, value也是一个一个list,并且只有一个元素element,此element就是咱们要的结果。最后咱们要evaluate这个模型预测的结果,咱们有很多种方式可以验证,这里只展示了一个最简单的方式,就是计算咱们的target和prediction的方差,其实有很多很多种方式,在后面的章节我会慢慢介绍。
第七步:data visualization
好了,最后咱们来看一下根据咱们的学习的模型,咱们想看看它的具体的拟合的效果,这里就需要用一点之前咱们学习的数据可视化的内容了,这里比较简单,咱们通过模型学习到的参数,画一条拟合线,然后在将数据画到画布上,坐标分别是"total_rooms"和"house_median_price",然后通过scatter plot展示出来。代码如下
sample = cali_housing_dataset_permutation.sample(n=300) x_0 = sample["total_rooms"].min() x_1 = sample["total_rooms"].max() linear_regressor.get_variable_names()#retrieve the name of the variable weights = linear_regressor.get_variable_value("linear/linear_model/total_rooms/weights")[0]#returns the value of variable given by name bias = linear_regressor.get_variable_value("linear/linear_model/bias_weights")#retruns the value of bias y_0 = weights*x_0+bias y_1 = weights*x_1+bias plt.plot([x_0,x_1],[y_0,y_1])#plot our regression line plt.ylabel("median_house_value")#label the y Axes plt.xlabel("total_rooms")#label the x Axes plt.scatter(sample["total_rooms"],sample["median_house_value"])#plot a scatter plot from the sample plt.show()
结果如下
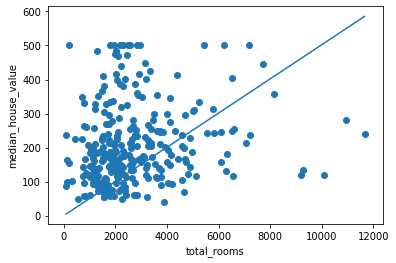
可以看得出来,拟合的还不错。嘿嘿,关于模型训练过程的可视化,后面还有很多种,以后我慢慢说,例如:x坐标是steps, y坐标是loss, 也是非常常见的一种方式。
总结
今天完整的展示了用TensorFlow创建模型的整个过程,一直从data preparation到最后的evaluation,可以说贯穿了TensorFlow开发机器学习应用的整个过程。今天先用一个最简单的线性拟合例子展示这个过程,后面我还会展示更多的更加复杂的模型,例如:Logistic Regression, DNN, LSTM,等等等等。但是万变不离其宗,他们的基础步骤都是上面的七个步骤。最后 ,祝武汉加油!!!!!!!!
机器学习-TensorFlow建模过程 Linear Regression线性拟合应用
标签:numpy compare 出错 展示 完成 内容 bec slice 帮助
原文地址:https://www.cnblogs.com/tangxiaobo199181/p/12241170.html