标签:越来越大 允许 方差 图片 训练 目的 计算 nbsp 错误
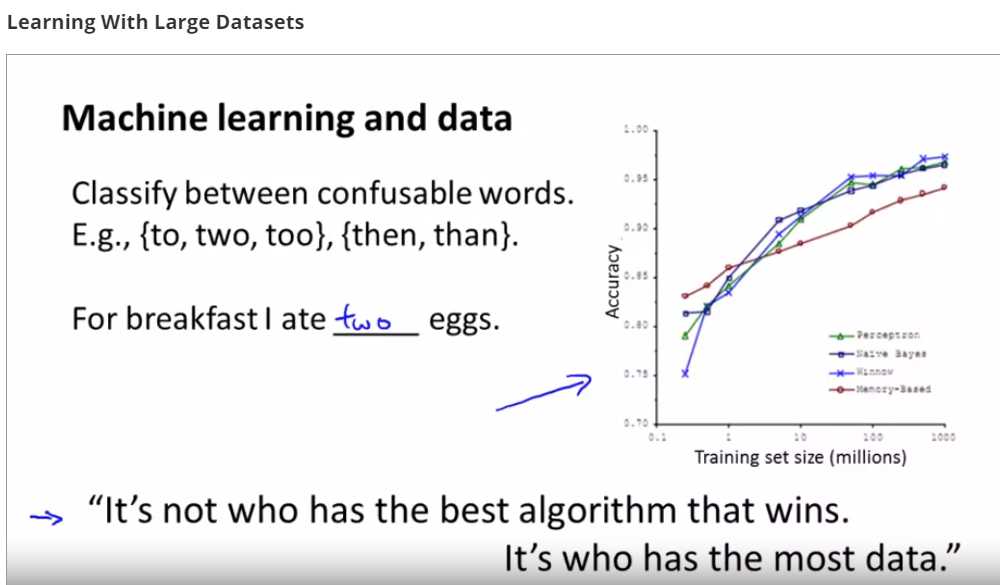
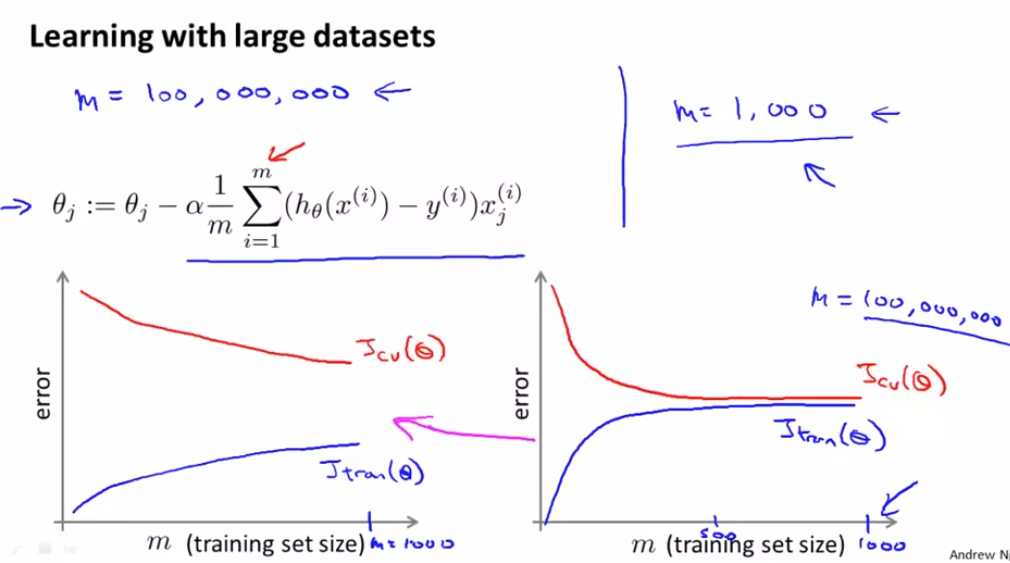
左侧像高方差的算法,增加训练集的大小提高性能 右侧像高偏差的算法,不需要增大算法的规模,m=1000就很好了 一个很自然的方法是多加一些特征 或者在你的神经网络里加一些隐藏的单元等等 所以最后你会变成一个像左边的图 也许这相当于m等于1000 这给你更多的信心去花时间在添加基础设施来改进算法 而不是用多于一千条数据来建模 会更加有效果 所以在大规模的机器学习中 我们喜欢找到合理的计算量的方法 或高效率的计算量的方法来处理大的数据集

对于很多机器学习算法 包括线性回归、逻辑回归、神经网络等等 算法的实现都是通过得出某个代价函数
或者某个最优化的目标来实现的 然后使用梯度下降这样的方法来求得代价函数的最小值 当我们的训练集较大时 梯度下降算法则显得计算量非常大
而梯度下降法的问题是 当m值很大时 计算这个微分项的计算量就变得很大 这种梯度下降算法也被称为批量梯度下降(batch gradient descent) “批量”就表示我们需要每次都考虑所有的训练样本

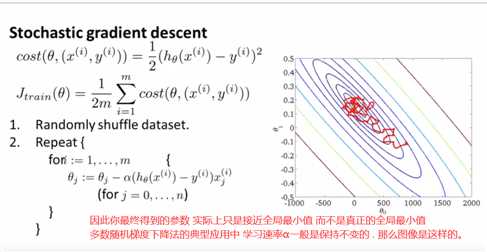
打乱数据是为了 快一些收敛
随机梯度下降不需要等到对所有m个训练样本 求和来得到梯度项 而是只需要对单个训练样本求出这个梯度项
我们已经在这个过程中开始优化参数了 不需要等到对所有这些数据进行扫描 然后才一点点地修改参数 直到达到全局最小值
对随机梯度下降来说 我们只需要一次关注一个训练样本 而我们已经开始一点点把参数朝着全局最小值的方向进行修改了


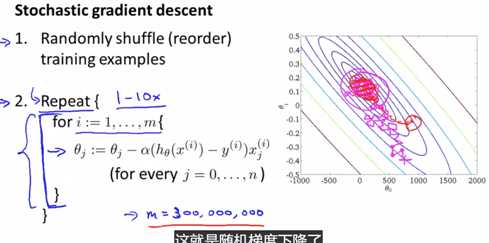
批量梯度下降的收敛过程 会倾向于一条近视的直线 一直找到全局最小值
在随机梯度下降中 每一次迭代都会更快 因为每一次迭代只需要保证对一个训练样本拟合好就行了
所以 如果我们从这个点开始进行随机梯度下降的话 第一次迭代 可能会让参数朝着这个方向移动
然后第二次迭代 只考虑第二个训练样本 假如很不幸 我们朝向了一个错误的方向 第三次迭代 我们又尽力让参数修改到拟合第三组训练样本
可能最终会得到这个方向 然后再考虑第四个训练样本 , 等等
在你运行随机梯度下降的过程中 你会发现 一般来讲 参数是朝着全局最小值的方向被更新的 但也不一定
所以看起来它是以某个比较随机、迂回的路径在朝全局最小值逼近 实际上 你运行随机梯度下降 和批量梯度下降 两种方法的收敛形式是不同的
实际上随机梯度下降是在某个靠近全局最小值的区域内徘徊 而不是直接逼近全局最小值并停留在那点 但实际上这并没有多大问题
只要参数最终移动到某个非常靠近全局最小值的区域内 这也会得出一个较为不错的假设
所以 通常我们用随机梯度下降法 也能得到一个很接近全局最小值的参数 对于绝大部分实际应用的目的来说 已经足够了
最后一点细节 在随机梯度下降中 我们有一个外层循环 它决定了内层循环的执行次数 所以 外层循环应该执行多少次呢
这取决于训练样本的大小 通常一次就够了 最多到10次 是比较典型的 因此 如果我们有非常大量的数据 , 所以每次你只需要考虑一个训练样本
你就能训练出非常好的假设 这时 由于m非常大 那么内循环只用做一次就够了
但通常来说 循环1到10次都是非常合理的 但这还是取决于你训练样本的大小 如果你跟批量梯度下降比较一下的话
批量梯度下降在一步梯度下降的过程中 就需要考虑全部的训练样本 所以批量梯度下降就是这样微小的一次次移动
这也是为什么随机梯度下降法要快得多 这就是随机梯度下降了 如果你应用它 应该就能在很多学习算法中应用大量数据了 并且会得到更好的算法表现

小批量梯度下降。 他们有时甚至比随机梯度下降更快一点 在仅仅看了前10个数据, 我们就可以开始取得进展, 可以改进参数theta,而不是一定要把整个训练集扫描一遍. 所以, 这就是为什么小批量梯度下降比批量梯度下降更快。 为什么我们要一次看 b 个数据, 而不是每次只看一个数据作为随机梯度下降? 答案是因为矢量化。 特别是小批量梯度下降可能优于随机梯度下降, 只要你能较好地实行矢量化。 在这种情况下, 10 个数据的总和可以以更矢量化的方式执行, 这将允许你对十个数据的计算进行部分的并行化 小批量梯度下降的一个缺点是, 现在有了这个额外的参数 b, 您可能需要调整小批量批次的大小,因此可能需要时间

回到我们之前批量梯度下降的算法 我们确定梯度下降已经收敛的一个标准方法 是画出最优化的代价函数
关于迭代次数的变化 这就是代价函数 我们要保证这个代价函数在每一次迭代中 都是下降的 当训练集比较小的时候 我们不难完成
对于随机梯度下降算法 为了检查算法是否收敛 我们可以进行下面的工作
让我们沿用之前定义的cost函数 关于θ的cost函数 随机梯度下降就是这样进行的 在算法扫描到样本(x(i),y(i)) 但在更新参数θ之前 使用这个样本
我们可以算出这个样本对应的cost函数 让我们来计算出 这个假设对这个训练样本的表现 我要在更新θ前来完成这一步
原因是如果我们用这个样本更新θ以后 再让它在这个训练样本上预测 其表现就比实际上要更好了
为了检查随机梯度下降的收敛性 我们要做的是 每1000次迭代 我们可以画出前一步中计算出的cost函数
并对算法处理的最后1000个样本的cost值求平均值 如果你这样做的话 它会很有效地帮你估计出 你的算法在最后1000个样本上的表现
所以 我们不需要时不时地计算Jtrain 那样的话需要所有的训练样本 随机梯度下降法的这个步骤 只需要在每次更新θ之前进行 也并不需要太大的计算量
要做的就是 每1000次迭代运算中 我们对最后1000个样本的cost值求平均然后画出来 通过观察这些画出来的图 我们就能检查出随机梯度下降是否在收敛
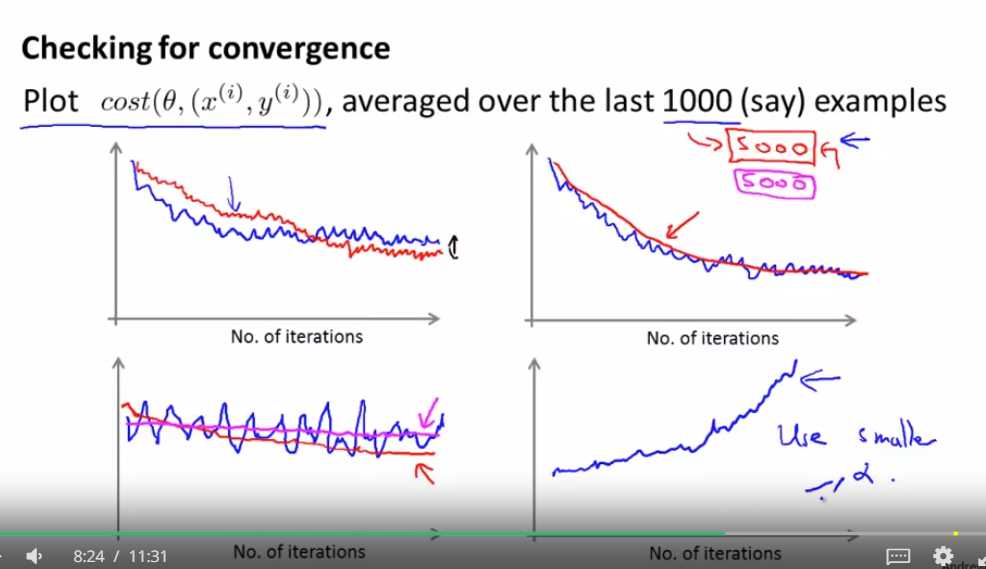
左上图 :红色的曲线代表随机梯度下降使用一个更小的学习速率
左下图:所以可能用5000组样本来平均 比用1000组样本来平均 更能看出趋势
如果曲线看起来噪声较大 或者老是上下振动 那就试试增大你要平均的样本数量 这样应该就能得到比较好的变化趋势
右下图 :如果你发现代价值在上升 那么就换一个小一点的α值
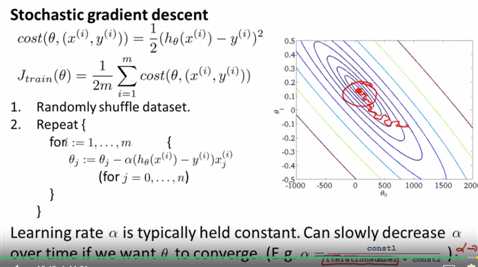
如果你想让随机梯度下降确实收敛到全局最小值 你可以随时间的变化减小学习速率α的值
迭代次数指的是你运行随机梯度下降的迭代次数 就是你算过的训练样本的数量,但是需要调整常数1,2的大小。这让算法显得更繁琐
但如果你能调整得到比较好的参数的话 你会得到的图形是 你的算法会在最小值附近振荡 但当它越来越靠近最小值的时候 由于你减小了学习速率 因此这个振荡也会越来越小 直到落到几乎靠近全局最小的地方
这个公式起作用的原因是 随着算法的运行 迭代次数会越来越大 因此学习速率α会慢慢变小
因此你的每一步就会越来越小 直到最终收敛到全局最小值 所以 如果你慢慢减小α的值到0 你会最后得到一个更好一点的假设
但由于确定这两个常数需要更多的工作量 并且我们通常也对 能够很接近全局最小值的参数 已经很满意了 因此我们很少采用逐渐减小α的值的方法 在随机梯度下降中 你看到更多的还是让α的值为常数



标签:越来越大 允许 方差 图片 训练 目的 计算 nbsp 错误
原文地址:https://www.cnblogs.com/tingtin/p/12242455.html