标签:函数 出生日期 次数 两种 年龄 文档 消费 action 生活
用户画像是根据用户社会属性、生活习惯、兴趣爱好和消费行为等信息而抽象出的一个标签化的用户模型,简而言之,就是给用户“打标签”。通过获取用户的信息,并对其进行分析,绘制用户画像。
用户信息可以分为两个维度,静态信息和动态信息,静态信息则指用户的固有属性,如性别,年龄,消费水平等,动态信息则是通过观察用户的一举一动,即获取的用户行为信息。
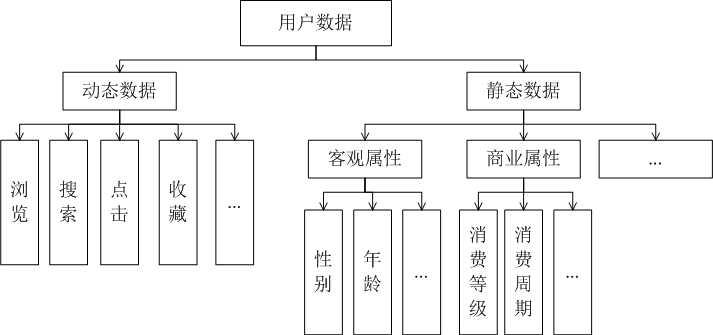
此外,我们还可将标签分为两种:静态属性标签和动态属性标签。静态属性标签长期甚至永远都不会发生改变,比如性别,出生日期,这些数据都是既定的事实,几乎不会改变;动态属性标签存在有效期,需要定期地更新,保证标签的有效性,比如用户的购买力,用户的活跃情况等内容。
通过分析用户行为,然后为用户打上标签,再为打上的标签添加权重,其中标签用来表征内容,权重用来表征指数(可信度)。用户画像需要通过对用户行为进行监控即建立在大量的真实数据的基础上从而虚拟出人物画像。后台数据库表如下图:

user_id:用户id
tag_id:标签id
tag_name:标签名称,用户某一行为与该标签联系
tag_type:标签类型
action_name:用户行为名称,如搜索,点击,收藏等
action_count:用户该行为的次数
action_time:用户该行为的时间,某年某月某日
weight:该标签的权重
标签权重字段非常重要,该权重影响着对用户属性的归类,属性归类不准确,接下来基于画像对用户进行推荐。标签权重也可以分为两部分来看,一是该标签的用户权重,就单纯的考虑用户与标签的关系;二是在客观权重的基础上,结合业务场景,再得到真正的标签权重。判断用户权重的方法很多,我们采用的是TF-IDF算法。
TF-IDF标签权重算法
TF:词频,指的是某一个给定的词语在该文件中出现的频率,如果一个词条在一类文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,数学表示:
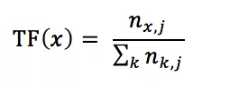
IDF:逆向文件频率,是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到,简单来说,就是看这个词语的稀缺程度,数学表示:
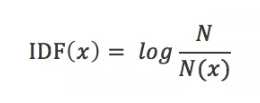
计算公式:用户标签权重=行为权重*衰减因子*行为次数*TF-IDF计算得到每个用户身上标签的权重。
行为权重
用户对同种产品产生不同行为,例如搜索、点击、收藏、取消收藏这几种行为的行为权重一定是不一样的,例如将取消收藏行为权重设为负值,具体的行为权重可以参考网上案例或者根据业务场景决定;
衰减因子
一般考虑时间,用户的行为会随着时间的过去,历史行为和当前的相关性不断减弱,例如去年发生的行为和今年发生的行为应该是有衰减逻辑在里面的,在建立与时间衰减相关的函数时,我们可套用牛顿冷却定律数学模型。如果周期小或业务场景稳定,也可以选择忽略这个因素;
行为次数
一般来说,不同的行为次数决定了用户的偏好程度,用户行为越多,对偏好影响就越大;
以上内容如有不当之处还望指正!
标签:函数 出生日期 次数 两种 年龄 文档 消费 action 生活
原文地址:https://www.cnblogs.com/qilin20/p/12249319.html