标签:产生 jar 换行 信息 文件目录 mapper ble 界面 获取
系统环境:hadoop2.65,mysql5.7.28,sqoop1.47,hive1.2.2,虚拟机centos7,物理机windows10
注意点:安装sqoop不要将目录设在hadoop下面,否则在运行下面命令时会发生找不到jar包的问题,我估计是系统将hadoop的lib目录认为成了sqoop的lib目录了。因为在我把相应的jar包放在hadoop的lib文件下时就可以通过,由于有很多jar包,所以一个jar找到了,又会有一个jar包找不到,所以建议不要放在hadoop目录下。
操作要求:将物理机的mysql数据转到虚拟机的mysql,然后使用sqoop将虚拟机的mysql转到hive中。
1.在物理机中使用Navicat的导出向导,获取sql文件,利用里面的建表语句,在虚拟机的mysql中建表,需要注意的是,linux的建表语句和windows有些许差异,比如:在编码的改动,需要将原来的编码utf8mb4_0900_ai_ci改成utf8_general_ci,utf8mb4改成utf8。
2.然后利用传输工具将sql文件传给虚拟机,然后虚拟机开启mysql,使用source命令调用sql文件,然后执行文件将所有数据插入mysql中。
3.然后我们在hive中创建相应的表,需要注意的是hive中没有varchar,需要使用string代替。
4.(可有可无)在hdfs上创建文件夹,来存放mysql数据
5.使用sqoop将mysql转到hdfs上,注意点:需要打开hdfs和yarn
\ 用于换行 bin/sqoop用来启动命令 import用来导入配置 connect连接数据库 用户名 密码 执行语句,$CONDITIONS在使用query语句时必须加上 指明hdfs上的目标目录 如果指定文件目录存在则先删除掉 使用1个map并行任务 启动压缩 指定hadoop的codec方式 默认为gzip 使用直接导入方式,优化导入速度,在mysql中速度提升比较明显 字段之间通过制表符分隔 bin/sqoop import \ --connect jdbc:mysql://192.168.133.130:3306/holiday2020 \ --username root \ --password 123456 \ --query ‘select * where capital_info $CONDITIONS LIMIT 5000‘ \ --target-dir /heiyang/data \ --delete-target-dir \ --num-mappers 1 \ --compress \ --compression-codec org.apache.hadoop.io.compress.SnappyCodec \ --direct \ --fields-terminated-by ‘\t‘
命令就会开始执行,会得到以下信息:
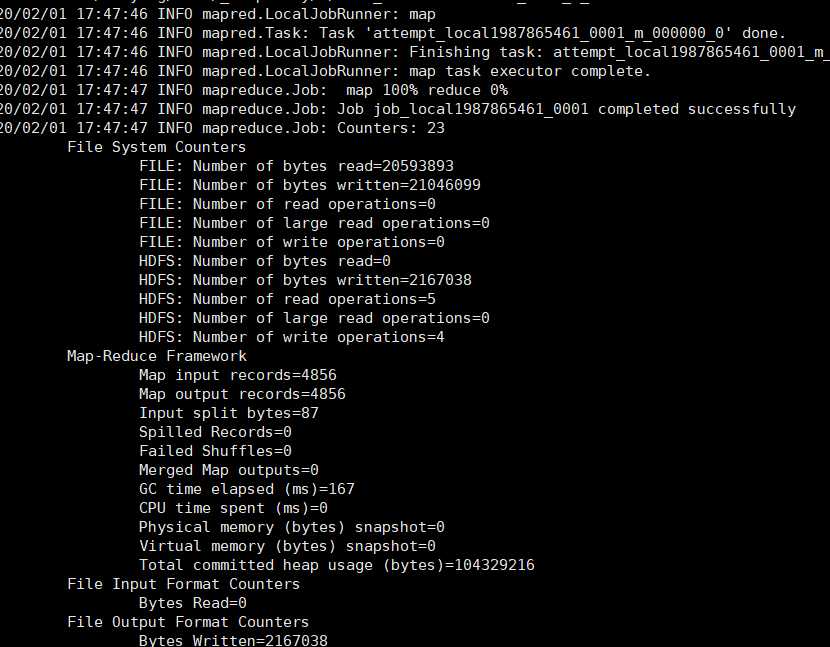
表示map完成,然后我们就可以看到hdfs上产生了两个文件
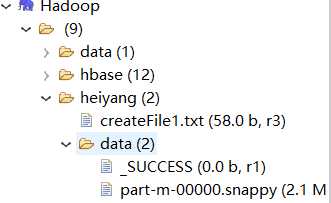
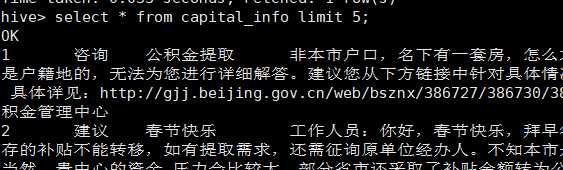
6.最后使用hive将数据导入到后hive中即可
load data inpath ‘/heiyang/data/‘ into table default.capital_info;
标签:产生 jar 换行 信息 文件目录 mapper ble 界面 获取
原文地址:https://www.cnblogs.com/heiyang/p/12249932.html