标签:local fir 文件夹 quit grep apach img 内容 contain
学习于林子雨《大数据技术原理与应用》教材配套大数据软件安装和编程实践指南
一. 安装spark
第一步,spark下载(http://spark.apache.org/downloads.html)
第二步,spark压缩包解压
sudo tar -zxf ~/下载/spark-1.6.2-bin-without-hadoop.tgz -C /usr/local/
第三步,解压后文件夹改名为spark
第四步,赋予权限
sudo chown -R hadoop:hadoop ./spark
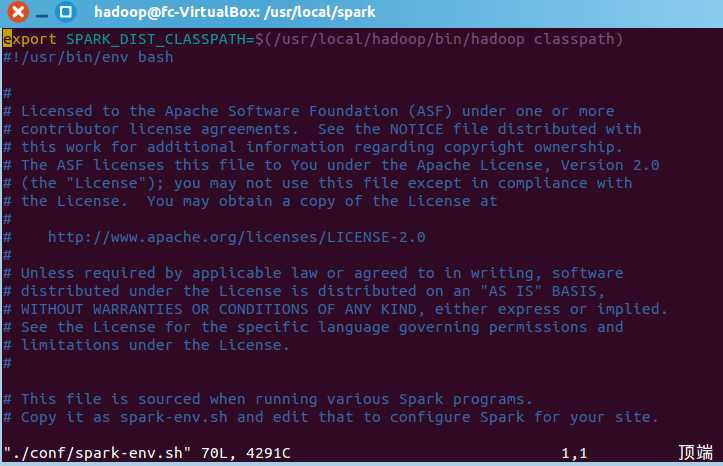
第五步,安装后,还需要修改Spark的配置文件spark-env.sh
第六步,测试
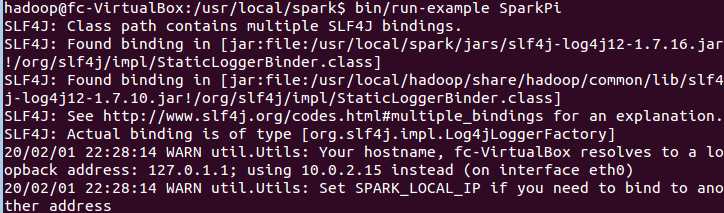 ,还有很多信息,这里只截了这么多,但可使用命令bin/run-example SparkPi 2>&1 | grep "Pi is",进行过滤,得到结果如图:
,还有很多信息,这里只截了这么多,但可使用命令bin/run-example SparkPi 2>&1 | grep "Pi is",进行过滤,得到结果如图:
就算安装成功了。
二.使用 Spark Shell 编写代码
第一步,启动spark shell
bin/spark-shell
成功后如图: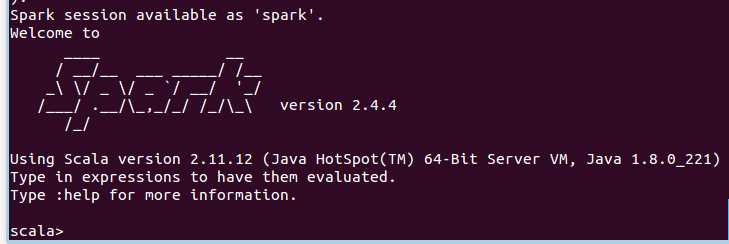
第二步,加载text文件
val textFile = sc.textFile("file:///usr/local/spark/README.md")
如图:
第三步,简单RDD操作





第四步,退出Spark Shell
:quit
标签:local fir 文件夹 quit grep apach img 内容 contain
原文地址:https://www.cnblogs.com/my---world/p/12250521.html