标签:方法 关键词 语言 12月 idf inverse 图像 ima false
今天学习自然语言的算法
TF为词频(Term Frequency),表示词t在文档d中出现的频率,计算公式
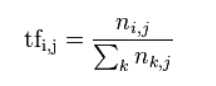
其中,ni,j 是该词 ti 在文件 dj 中的出现次数,而分母则是在文件 dj 中所有字词的出现次数之和。
IDF 为逆文档频率(Inverse Document Frequency),表示语料库中包含词 t 的文档的数目的倒数,计算公式:
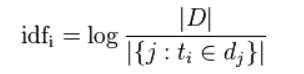
其中,|D| 表示语料库中的文件总数,|{j:ti∈dj}| 表示包含词 ti 的文件数目,如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用 1+|{j:ti∈dj}|。TF-IDF 在实际中主要是将二者相乘,也即 TF * IDF, 计算公式:
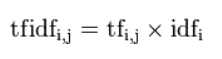
因此,TF-IDF 倾向于过滤掉常见的词语,保留重要的词语。例如,某一特定文件内的高频率词语,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的 TF-IDF。
Jieba中基于TF-IDF算法的关键词抽取:

jieba代码:
#_*_coding:utf-8_*_ import jieba.analyse sentence = "人工智能(Artificial Intelligence),英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。人工智能从诞生以来,理论和技术日益成熟,应用领域也不断扩大,可以设想,未来人工智能带来的科技产品,将会是人类智慧的“容器”。人工智能可以对人的意识、思维的信息过程的模拟。人工智能不是人的智能,但能像人那样思考、也可能超过人的智能。人工智能是一门极富挑战性的科学,从事这项工作的人必须懂得计算机知识,心理学和哲学。人工智能是包括十分广泛的科学,它由不同的领域组成,如机器学习,计算机视觉等等,总的说来,人工智能研究的一个主要目标是使机器能够胜任一些通常需要人类智能才能完成的复杂工作。但不同的时代、不同的人对这种“复杂工作”的理解是不同的。2017年12月,人工智能入选“2017年度中国媒体十大流行语”。" keywords = " ".join(jieba.analyse.extract_tags(sentence,topK=20,withWeight=False, allowPOS=())) print(keywords) keywords = (jieba.analyse.extract_tags(sentence, topK=10, withWeight=True, allowPOS=([‘n‘, ‘v‘]))) print(keywords)

标签:方法 关键词 语言 12月 idf inverse 图像 ima false
原文地址:https://www.cnblogs.com/goubb/p/12250767.html