标签:img mic 来讲 区分 组合 残差 思想 关于 经典
1.提升方法AdaBoost算法
AdaBoost的思想:是先得到一个弱分类器,然后在这个弱分类器的基础上将其提升到强分类器,具体方法是提升上一个分类器中被误分类的样本的权重,使得本次训练的分类器更加重视这些样本,最后的分类器是所有的分类器的线性组合。
前一次没有正确分类的样本点在后一次会被更加重视,前一次的分类器训练结果是会影响后一次分类器结果的。
AdaBoost先对所有划分选择出一个误分类最小的划分,得出一个分类器,分类器的权值![]()
,样本的权值也发生更新![]() ,也就是说前一次的训练的结果会被这次的分类器产生影响。
,也就是说前一次的训练的结果会被这次的分类器产生影响。
问:AdaBoost算法每一次训练的训练误差相对于上一轮是不是一定减少?
答:首先区分训练误差和训练误差率,训练误差![]()
不同于分类误差率![]()
,被上一轮分类错误的样本增加了它的权值,从而使得下一轮分类器的训练重视这些被上一轮分类器误分的样本,权值更高的样本更有可能被正确分类,那么相应的分类误差率一定减小,训练误差不一定减少。
延伸:分类误差率一定一直减少,那么样本权值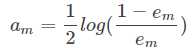
一定一直增加,所以可以确定前一轮的分类器的权值一定小于后一轮的权值,am<am+1。
2.AdaBoost算法的训练误差分析
训练误差率是不断减少的,那么训练误差也在学习过程中不断地减少(注意是学习过程中分类器的加法模型的训练误差一直减少,而后一个分类器的训练误差不一定比前一个分类误差的训练误差小)。训练误差是随着每加权一个弱分类器而减少的,那么要得出训练误差![]() 的性质,就需要使其小于一个值(在这里是
的性质,就需要使其小于一个值(在这里是![]() ),推出后一个值的性质,就可以得出前者的性质,比如后者呈指数形式下降,前者小于后者,那么它也呈指数下降。同理,如果一个变量是一直增大的,那么要证明这个变量的性质,就要使其大于一个值,推出这个值得性质就可以得出变量的性质。
),推出后一个值的性质,就可以得出前者的性质,比如后者呈指数形式下降,前者小于后者,那么它也呈指数下降。同理,如果一个变量是一直增大的,那么要证明这个变量的性质,就要使其大于一个值,推出这个值得性质就可以得出变量的性质。
问:在第二节中AdaBoost的训练误差界的证明中得出,AdaBoost的训练误差是以指数速率下降的,和AdaBoost的损失函数是指数函数有什么联系?可不可以得出训练误差是以指数速率下降,所以选择损失函数为指数函数?
答:损失函数的意义是得出模型给出的结果和实际结果的偏离程度,AdaBoost的损失函数选择指数函数,是因为AdaBoost在第一节处理的是二分类问题,如果处理的是回归问题那么选择的是均分差损失函数,损失函数的选择只与处理的问题有关。所以训练误差的性质与损失函数的选择之间没有联系。
3.前向分布算法与AdaBoost
第三节介绍了前向分布算法并从前向分布算法的角度来看AdaBoost。首先介绍了前向分布算法,前向分布算法的目标是训练一个加法模型![]()
是从前向后,每一步只学习一个基函数及其系数,而平常的分布算法是从m=1到M所有参数βm,γm的优化问题简化为逐次求解各个βm,γm的优化问题,一步一个脚印肯定比一步登天更容易实现,不是吗?
AdaBoost也可以从前向分布算法的角度来看,不过要设定基函数为基本分类器,损失函数为指数损失函数。它的每一轮的分类器的训练是为了拟合残差,第一轮是为了拟合样本数据,后面都是为了拟合残差。由前向分布算法可以推导出第一节的分类器权值am和第m+1轮的样本权值am+1
4.从提升树到GBDT
第四节介绍了提升树,提升树是AdaBoost的特例,可以认为提升树是基本分类器为二类分类树,损失函数为平方损失函数的AdaBoost。分类问题的提升树改变权重,回归问题的提升树拟合残差。
前向分布算法+决策树(分类树or回归树)=提升树
因为损失函数是平方损失函数的时候,残差是好求的,而如果不是平方损失函数也不是指数损失函数的时候,残差就不可求得,这时,就要用损失函数关于当前模型f(x)的负梯度来近似代替残差。梯度提升算法就是用梯度下降法来讲弱分类器提升为强分类器的算法。
问:提升树和AdaBoost之间是什么关系?
答:AdaBoost是提升思想的算法模型,经典的AdaBoost一般用于分类问题,并没有指定基函数,或者说是基分类器,它可以从改变样本的权值的角度和前向分布算法的角度来解释。当确定基函数是回归或分类树时,结合前向分布算法就得出提升树算法。
使用梯度提升进行分类的算法叫做GBDT,进行回归时则叫做GBRT。一般的提升树是用残差来确定树的叶节点的切分,并根据残差来确定该切分下的输出值,而GBDT首先是根据负梯度来确定切分,确定切分后根据线性搜索估计叶节点区域的值,使损失函数极小化。这就好比是寻找一个全局极小值,负梯度只给定一个方向,通过线性搜索确定在该方向下走几步(该次向北,走20步。。。)线性搜索的步骤:![]()
所以可以认为伪残差是只给出方向的残差。
GBDT的算法流程如下:
1)初始化,初始化一个常数值,即只有一个根节点的树![]()
2)for m=1,2,…,M
(a)for i=1,2,…,N,计算负梯度(伪残差):![]()
(b)对伪残差拟合一个回归树,得到第m棵树的叶结点区域 ,j=1,2…,J,
(这里的J是事先确定的,也就是把区域分成的份数,确定份数后穷举所有切分拟合残差得出损失误差最小的切分就是最佳切分,从而就可以得出第m棵树的叶结点区域)
(c)对j=1,2,..J,计算
![]()
(d)更新![]()
(3)输出回归树
fm(x)
参考博客:https://blog.csdn.net/weixin_35479108/article/details/87438226
标签:img mic 来讲 区分 组合 残差 思想 关于 经典
原文地址:https://www.cnblogs.com/xutianlun/p/12252726.html