标签:图计算 因此 问题 数据封装 sock 添加 team mapr 离线处理
因为想要通过hive作为数据库来保存爬取后和处理完成的数据,需要添加spark的hive支持,这方面还没编译完,所以今天暂时没有这方面的进度,所以写写SparkSteaming。
数据的价值随着时间的流逝而减少
这也正是MapReduce的使用范围所产生的的极大弊端,没法应对大流量的实时数据,MR这类离线处理并不能很好地解决问题。
流计算可以很好地对大规模流动数据在不断变化的运动过程中实时地进行分析,捕捉到可能有用的信息,并把结果发送到下一计算节点。而Spark中能很好地处理流计算的就是SparkSteaming。
SparkSteaming有很好地实时性、低延迟与稳定可靠,但缺点相对也有,就是无法做到毫秒级延迟,但优点也很明显,支持从多种数据源获取数据,包括Kafk、Flume、Twitter、ZeroMQ、Kinesis 以及TCP sockets,还可以使用Spark的其他子框架,如集群学习、图计算等,对流数据进行处理。

对应的批数据,在Spark内核对应一个RDD实例,因此,对应流数据的DStream可以看成是一组RDDs,即RDD的一个序列。通俗点理解的话,在流数据分成一批一批后,通过一个先进先出的队列,然后 Spark Engine从该队列中依次取出一个个批数据,把批数据封装成一个RDD,然后进行处理,这是一个典型的生产者消费者模型,对应的就有生产者消费者模型的问题,即如何协调生产速率和消费速率。
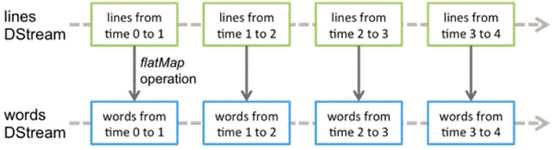
DStream(Discretized Stream)作为Spark Streaming的基础抽象,它代表持续性的数据流。这些数据流既可以通过外部输入源赖获取,也可以通过现有的Dstream的transformation操作来获得。在内部实现上,DStream由一组时间序列上连续的RDD来表示。每个RDD都包含了自己特定时间间隔内的数据流。如下图所示,DStream中在时间轴下生成离散的RDD序列。。

对DStream中数据的各种操作也是映射到内部的RDD上来进行的,如图所示,对Dtream的操作可以通过RDD的transformation生成新的DStream。
标签:图计算 因此 问题 数据封装 sock 添加 team mapr 离线处理
原文地址:https://www.cnblogs.com/limitCM/p/12253740.html