标签:gpt rop 传统 token com 地方 png alt loss
该文主要采用“知识蒸馏”方法对BERT(预训练语言模型)精简、优化,将较大模型压缩成较小的模型,最终目的是:提高模型推理的效率,让运行在智能手机等硬件设备上的深度学习模型具有轻量级、响应快及能源利用率高等特性。
在2019年的NLP领域预训练+微调的模型训练思路百家争鸣,ElMo、GPT、BERT、Mass、ULMFit等模型陆续登台成为当前领域最闪耀的星星,纵览全局能够真正快速用于产品化落地的model恐怕唯有BERT了,虽说GPT-2被传的神乎其神,但其未公开的预训练模型还是不能让广大粉丝热捧。既然如此,我们不妨在BERT上做做研究,以其在产品落地上进一步发挥威力。
虽然各类BERT的衍生模型频繁霸榜,但由于其block堆叠实在太多,在实际任务推理时性能瓶颈是一个很大的问题。不得不承认使用BERT确实比其它的传统DL方法效果要好,而且简单、快速、易操作,既然坚持要用它,那么我们就要面对它的瓶颈-推理速度慢,慢到什么程度?使用一个12层的model,对单个句子(不超过30个字)的预测耗时在100ms-200ms,如果这个时间你能够承受,可以满足你的业务要求,那很ok,你可以直接使用BERT完成任务。。。如果无法接受,就得想办法在影响性能的地方搞事情了。
在模型这块,精简参数,加快推理的方法有:1)量化:使用更小的精度模型替换全精度模型;2)权重剪纸:合理去除网络中的部分连接;3)知识蒸馏:算法层面的提速方式,且成本较低。
2015年hinton等人将知识蒸馏方法进一步发扬光大,可进一步参看《Distilling the Knowledge in a Neural Network》细节之处,大体思路是:使用两个网络(teacher model 和 student model),用teacher model 指导 student model的生成,最终蒸馏出来的student model就是我们需要的精简model。在这里teacher model是海量数据集下预训练得到的大模型,需要他的目的是将大模型的eval结果soft label 指导student model 学习;而student model 是由soft label和hard label组成,如下图所示: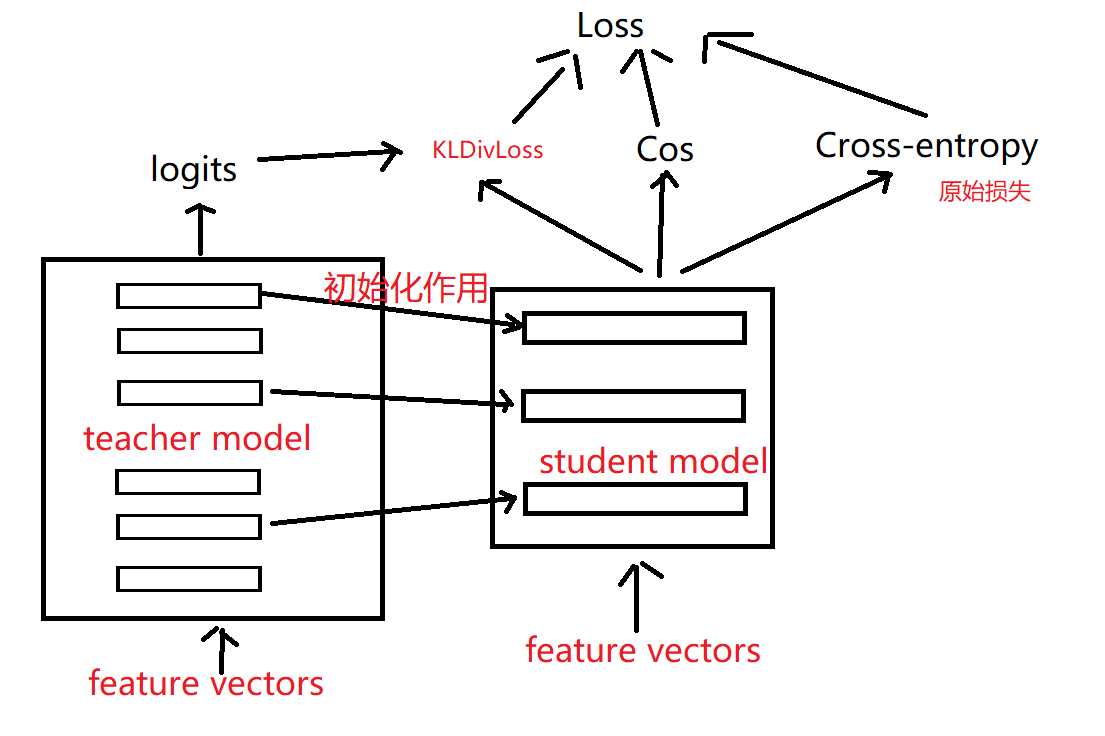
几个重要的地方:1)文章指出,对计算性能影响较大的不是隐含层节点的个数而是隐含层的层数,所以在大模型没两层去掉一层;2)也要去掉token type embedding;3)小模型的初始化用大模型预训练好的参数
损失的计算:
以上求权重和计算整个网络的损失:Loss = 5.0*KLDivLoss + 2.0*Cross-entropy + 1.0*Cos
————————————————————————————————————————待续
《DistilBERT,adistilledversionofBERT:smaller, faster,cheaperandlighter》阅读心得
标签:gpt rop 传统 token com 地方 png alt loss
原文地址:https://www.cnblogs.com/demo-deng/p/12257116.html