标签:port ssl 匹配 created id3 set 个数 dtree top
决策树是监督学习的分类算法,关键在于决策树树的构造。构造决策树的算法有:ID3、C4.5、CART。
ID3算法的构造决策树的过程如下:
因为有好几个特征,依据哪一个特征划分,如,形如[‘四条腿‘,‘会叫‘,‘狗‘],是依据有几条腿的特征,还是会不会叫的特征,所以要有评判标准:可以依据信息熵或者基尼不纯度进行选取
信息熵
计算公式\(H=-\sum_{i=1}^n p(x_{i}) \log_{2} p(x_{i})\)其中\(p(x_i)\)为\(x_{i}\)对应的出现的概率
信息熵越小,集合的有序程度越高,分类的效果越好
基尼不纯度
即随机从数据集中选取一项,查看它被错误分类的概率。基尼不纯度越小,集合的有序程度越高,分类的效果越好
在ID3算法中采用信息熵划分数据
所以通过信息熵选取,如果依据该特征划分得到的信息熵越小(熵是混乱程度,如果熵小,说明数据越不混乱,越是一类,所以越好),就先依据该特征划分
信息熵计算
#输入数据集,形如['四条腿','会叫','狗']。最后的狗为所属类型,输出计算的信息熵
def calEntropy(dataSet):
length = len(dataSet)
count = {}
entropy = 0
#统计每个类型在数据集中的个数
for i in dataSet:
label = i[-1]
count[label] = count.get(label, 0) + 1
for key in count:
p = count[key] / length#计算该类型在数据集中的概率
entropy = entropy - p * math.log(p, 2)#计算信息熵
return entropy特征的选取
#划分的函数
def splitDataSet(dataSet, axis, value):
childDataSet = []
for i in dataSet:
if i[axis] == value:
childList = i[:axis]
childList.extend(i[axis + 1:])
childDataSet.append(childList)
return childDataSet
#选取最好特征的函数
def chooseFeature(dataSet):
oldEntropy = calEntropy(dataSet)
character = -1
#因为数据形如['四条腿','会叫','狗'],['两条腿','会叫','鸡']最后一个是所属的类别,如果对所有特征遍历,所以要循环数据长度减一次
for i in range(len(dataSet[0]) - 1):
newEntropy = 0
#先按第一个特征划分,得到第i个特征的所有的值,如第1个是会叫,会叫
featureList = [word[i] for word in dataSet]
value = set(featureList)#去掉重复的特征值
#遍历每一个特征值,得到每一个值划分后的子集的熵,最后求所有特征值的熵的期望
for j in value:
childDataSet = splitDataSet(dataSet, i, j)
newEntropy += len(childDataSet) / len(dataSet) * calEntropy(childDataSet)
#将得到的熵与上一个特征划分后的熵对比,哪个小,就选取哪个特征,最后返回该特征的序号,作为划分的依据
if (newEntropy < oldEntropy):
character = i
oldEntropy = newEntropy
return character#返回列表中出现此处最多的一项所对应的类别
def most(classList):
classCount = {}
for i in range(len(classList)):
classCount[i] = classCount.get(i, 0) + 1
sortCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortCount[0][0]
#构造决策树
def createDT(dataSet, labels):
tempLabels=labels[:]
classList = [word[-1] for word in dataSet]
#第一个停止条件,划分到所有类别都相同
if classList.count(classList[0]) == len(classList):
return classList[0]
#或者第二个停止条件,已经遍历完所有特征了,就看哪一个类别多,这一支就代表哪一个类别
if len(dataSet[0]) == 1:
return most(dataSet)
character = chooseFeature(dataSet)
node = tempLabels[character]#取得最好的特征所对应的名称
myTree = {node: {}}#树结构用字典存储
del (tempLabels[character])
featureList = [word[character] for word in dataSet]
value = set(featureList)
#按照这一特征的不同特征值再进行划分
for i in value:
newLabels = tempLabels
myTree[node][i] = createDT(splitDataSet(dataSet, character, i), newLabels)
return myTree其实就是树的搜索遍历
def classify(dTree, labels, testData):
node = list(dTree.keys())[0]#得到根结点
condition = dTree[node]#得到该节点到其它结点的所有判断条件
labelIndex = labels.index(node)
for key in condition:
#遍历所有判断条件,如果条件匹配
if testData[labelIndex] == key:
#如果不是叶子结点,继续搜索子树
if type(condition[key]).__name__ == 'dict':
classLabel=classify(condition[key], labels, testData)
#如果是叶子结点,该叶子结点的类别就是预测的类别
else:
classLabel = condition[key]
return classLabel
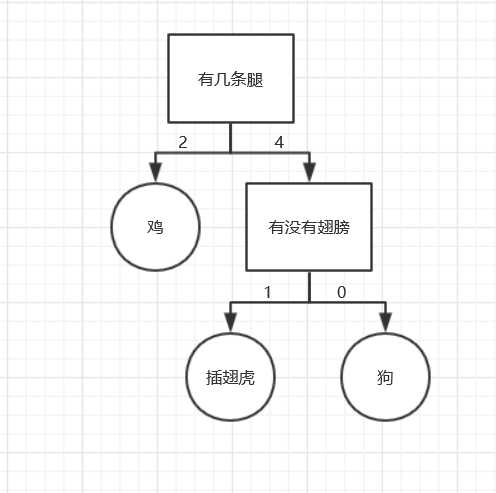
有以下数据
| 有几条腿 | 有没有翅膀 | 类别 |
|---|---|---|
| 4 | 0 | 狗 |
| 4 | 0 | 狗 |
| 4 | 1 | 插翅虎 |
| 2 | 1 | 鸡 |
| 2 | 1 | 鸡 |
预测有4条腿,1对翅膀的是哪一个类别
import math
import pickle
import operator
#训练数据存在这里
def createDataSet():
dataSet = [[4, 0, '狗'], [4, 0, '狗'], [4, 1, '插翅虎'], [2, 1, '鸡'], [2, 1, '鸡']]
labels = ['有几条腿', '有没有翅膀']
return dataSet, labels
#计算信息熵
def calEntropy(dataSet):
length = len(dataSet)
count = {}
entropy = 0
for i in dataSet:
label = i[-1]
count[label] = count.get(label, 0) + 1
for key in count:
p = count[key] / length
entropy = entropy - p * math.log(p, 2)
return entropy
#划分数据集
def splitDataSet(dataSet, axis, value):
childDataSet = []
for i in dataSet:
if i[axis] == value:
childList = i[:axis]
childList.extend(i[axis + 1:])
childDataSet.append(childList)
return childDataSet
#选择最好的特征
def chooseFeature(dataSet):
oldEntropy = calEntropy(dataSet)
character = -1
for i in range(len(dataSet[0]) - 1):
newEntropy = 0
featureList = [word[i] for word in dataSet]
value = set(featureList)
for j in value:
childDataSet = splitDataSet(dataSet, i, j)
newEntropy += len(childDataSet) / len(dataSet) * calEntropy(childDataSet)
if (newEntropy < oldEntropy):
character = i
oldEntropy = newEntropy
return character
#当遍历完所有特征时,用于选取当前数据集中最多的一个类别代表该类别
def most(classList):
classCount = {}
for i in range(len(classList)):
classCount[i] = classCount.get(i, 0) + 1
sortCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortCount[0][0]
#构造决策树
def createDT(dataSet, labels):
tempLabels=labels[:]
classList = [word[-1] for word in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1:
return most(dataSet)
character = chooseFeature(dataSet)
node = tempLabels[character]
myTree = {node: {}}
del (tempLabels[character])
featureList = [word[character] for word in dataSet]
value = set(featureList)
for i in value:
newLabels = tempLabels
myTree[node][i] = createDT(splitDataSet(dataSet, character, i), newLabels)
return myTree
#分类
def classify(dTree, labels, testData):
node = list(dTree.keys())[0]
condition = dTree[node]
labelIndex = labels.index(node)
for key in condition:
if testData[labelIndex] == key:
if type(condition[key]).__name__ == 'dict':
classLabel=classify(condition[key], labels, testData)
else:
classLabel = condition[key]
return classLabel
#用于将构建好的决策树保存,方便下次使用
def stroeTree(myTree,filename):
f=open(filename,'wb')
pickle.dump(myTree,f)
f.close()
#载入保存的决策树
def loadTree(filename):
f=open(filename,'rb')
return pickle.load(f)
测试程序
dataSet, labels = createDataSet()
myTree=createDT(dataSet, labels )
stroeTree(myTree,r'C:\Users\Desktop\1.txt')
myTree=loadTree(r'C:\Users\Desktop\1.txt')
print(myTree)
print(classify(myTree,labels,[4,1]))最后构造的决策树如图
标签:port ssl 匹配 created id3 set 个数 dtree top
原文地址:https://www.cnblogs.com/Qi-Lin/p/12257550.html