标签:temp ges search 规划 fit mes info 图片 guide
强化学习算法类型
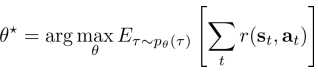
策略梯度:可直接区别以上的目标
基于值:估计最优策略(不明确哪个是最优的策略情况下估计)的值函数和Q函数
Actor-critic(演员-评论家):使用当前策略去估计值函数和Q函数来改进策略
基于模型:估计转换模型,接着
1.让该模型去规划不明确的策略
2.让该模型去改进策略
3.其他
比较:
有监督学习:几乎都是使用梯度下降
强化学习:通常不使用梯度下降
特定算法示例:
• 值函数方法
• Q-learning, DQN
• Temporal difference learning
• Fitted value iteration
• 策略梯度方法
• REINFORCE
• Natural policy gradient
• Trust region policy optimization
• Actor-critic方法
• Asynchronous advantage actor-critic (A3C)
• Soft actor-critic (SAC)
• Model-based方法
• Dyna
• Guided policy search
应用举例:
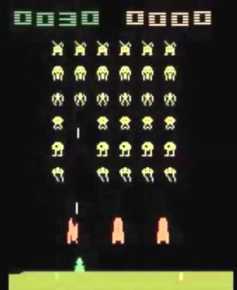
例1: 用Q函数玩Atari games
论文参考:
• Playing Atari with deep reinforcement learning, Mnih et al. ‘13
• Q-learning with convolutional neural networks
例2: 机器人和基于模型的强化学习
论文参考:
• End-to-end training of deep visuomotor policies, L.* , Finn* ’16
• Guided policy search (model-based RL) for image-based robotic manipulation
例3: 用策略梯度实现走路
论文参考:
• High-dimensional continuous control with generalized advantage estimation, Schulman et al. ‘16
• Trust region policy optimization with value function approximation

例4: 用Q函数实现机器人抓取
论文参考:
• QT-Opt, Kalashnikov et al. ‘18
• Q-learning from images for real-world robotic grasping

标签:temp ges search 规划 fit mes info 图片 guide
原文地址:https://www.cnblogs.com/phonard/p/12258905.html