研究方向的重要性(有意义):
城市土地使用信息在城市管理、政府政策制定、和人类活动监测方面扮演着重要的角色。
However,存在的困难:
由于城市系统的复杂性,将城市功能区正确分类是一件具有挑战性的事情。
与此项研究课题相关的其他研究的做法:
许多研究都是从高分辨率遥感影像或者社交媒体数据提取出特征,并对特征进行对比分析来进行土地使用的分类。但是由于缺乏有效的模型,很少有研究将这两个特征同时考虑
本研究提出的方法:
我们提出了一种新奇的场景分类的框架在交通分析区水平上来鉴别主要的城市土地利用模式。这个框架是整合概率主题模型和支持向量机(SVM)。在这个框架中的土地使用字典是通过融合从高分辨率遥感图像中提取出来的自然物理特征和从多元社交媒体数据中的社会经济语义特征。除了与人工解译作比较,我们设计了几个实验来检测提出的模型对于先前得到的语义特征的不同组合所反应的不同土地使用分类正确性。
分类结果(总体正确率0.865,Kappa指数0.828)显示我们所提出策略的有效性--混合从多源地理空间数据提取的特征作为语义特征来训练分类模型。
这个方法可以被应用于帮助城市策划者分析精细的城市结构和监视城市土地使用变化。并且在未来从多源数据得到的其他数据将会融合进这个提出的框架中。
介绍
①城市土地使用模式
LULC(土地使用和土地覆盖):
土地使用和土地覆盖信息包含许多领域重要的地域空间特征,例如,城市规划,政府管理,和可持续发展。
城市土地使用模式:
中国经济和城市的快速发展生成了多种多样复杂的城市功能区,功能区反映了城市土地使用模式。
土地使用模式不仅受政府政策的影响,也受随城市发展而持续改变的室内生活方式的影响。
Therefore,土地使用模式的有效检测对于制定有效的城市规划非常重要。在近期的研究中,土地使用模式的有效检测是一个有争议的话题。
②利用HSR遥感影像进行LULC的检测。
在最近的研究中,HSR影像分类模型可以广泛地应用于提取和分析土地使用和土地覆盖(LULC)。LULC的分析主要由三个空间单元组成:像素,物体 和场景。物体用来评估土地覆盖,场景经常用于鉴别城市功能区和评价城市土地使用模式。
许多研究采用面向对象分类(OOC)模式通过地物的物理特征(例如光谱,形状和质地特征)来提取城市土地使用模式。However,OOC模型经常忽视地物的空间分布及语义特征,因为它们旨在挖掘地物低级语义土地覆盖信息。
由于在挖掘足够的信息方面存在困难,上述传统分类模型很难使用传统遥感分类模型分类出的典型专题特征去鉴别土地使用分类。困难是由于跨越“语义鸿沟”的问题。
③高、低级语义特征对比
简单来说,低等级语义特征表明“信息”直接来源于数据,而高等级语义特征指的是指针对每个用户和应用程序的“知识”。语义鸿沟指的是这两个级别之间特定的功能差异。
在图像解译的领域,低等级语义特征直接从影像数据中提取,例如颜色和纹理,只能够表达物理属性。 不同的物体可能有相同的物理属性,相同的物体也可能有不同的物理属性。所以使用低等级的语义特征进行图像分类很可能是不正确的。
但是,将高级语义特征(即人类操作员根据用途和其他信息赋予对象的各种属性)引入图像分类中,可能会以较高的准确性进行更明确的分类。例如,有一系列包含不同场景的HSR图像,可以基于低级特征描述来识别土地覆盖物对象,例如 建筑物。 但是,尝试捕获高级潜在语义概念的目的是寻求不同的功能类型,例如住宅区,商业区和工业区。
④HSR场景分类
为了弥合LULC之间的“语义鸿沟”,最近的研究已将“场景分类”的概念引入到HSR图像分类中,以用单个类别标记场景。当前的大多数研究都应用了词袋(BoW)建模方法,并通过概率主题模型(PTM)融合了地面场景的物理特征,以提高具有高级语义信息的城市土地利用类型的检测准确性。
Zhang et al.(2015b)引入了线性Dirichlet混合模型(LDMM),该策略融合了HSR图像和道路网络数据,以检测每个土地块中土地使用的百分比
HSR提取特征的局限性
但是,从遥感图像中提取特征只能代表地面成分的外部自然物理特性,而区域土地利用类型通常与室内人类社会经济活动具有很强的相关性,而这很难从HSR图像中提取。
⑤社交媒体数据可反映室内人类经济活动
为了解决这个问题,最近的研究提出了“社会感知”和“城市计算”的概念。引入了多源社交媒体数据,例如浮动汽车的全球定位系统(GPS)轨迹,移动电话信号,社交媒体的签到数据和兴趣点(POI),以监视住宅活动和城市土地使用动态 。 许多深入的讨论表明,多源社交媒体数据具有揭示城市土地利用模式的巨大潜力。
Yuan等。 (2012年)提出了一个基于POI的语义分析模型DRoF来绘制城市功能区(Yuan等,2012)。 Yuan和Zheng(2015)引入了潜在狄利克雷分配(LDA)模型,该模型结合了浮动汽车的GPS轨迹和POI频率来挖掘具有高级语义信息的城市土地利用类型,这可以改善基于HSR图像的方法
⑥上述两种方法各自的局限性及本文提出的方法
但是,这些方法仅利用一种类型的数据,而不是将HSR图像和社交媒体数据中的地理空间信息融合到土地利用类型的检测中。
城市土地利用类型相似的地区往往具有相似的外部自然-物理特性和室内人类社会经济活动模式(Yao等人,2016),例如,仅仅利用遥感图像信息而不使用室内人类活动信息很难将中央商务区(CBD)和带有高层塔楼的住宅区区分开。另一方面,都是人类活动较少的地区,光秃秃的田野和农田,可以通过从遥感图像中识别自然物理特性来区分。
如前所述,我们的研究旨在通过结合几种机器学习和自然语言处理(NLP)模型来融合从HSR图像(遥感信息)和多源社交媒体数据(社会感知信息)作为对城市土地利用进行分类并通过人工解释评估分类模型的准确性和可靠性的模式。该模型用于检测广州市海珠区的土地利用方式,广州海珠区是中国南方最发达的城市之一,具有多种土地利用类型。通过组合各种特征并比较相应的分类结果,我们得到了特征与土地利用分类结果的最佳组合。
二、研究区域和数据
①海珠区基本情况
研究区域位于广东省广州市海珠区(图1(a)),总面积102平方公里,常住人口约1,010,500。 广州被认为是华南地区的政治,文化和经济中心。 作为广州四个市中心区之一,海珠区的城市结构非常复杂,混合了多种土地利用类型,例如住宅社区,购物中心,医疗设施和教育建筑。
②对图1(a)(b)进行解释说明
图1(b)显示了2014年海珠区的高空间分辨率(HSR)Worldview-2图像,其网格尺寸为34,263×14,382,空间分辨率为0.5 m。 根据OpenStreetMap提供的路网数据,HSR图像和官方城市规划数据,我们将图像分为593个土地斑块,类似于交通分析区(TAZ)(Long and Thill 2015)。
图1(a)通过人工解释显示了研究区域中主要土地利用类型的分类结果,其中包括公共管理服务用地(M),工业用地(I),绿地(G),商业用地(C) ,住宅用地(R),公园用地(P)和城市村庄(U)。
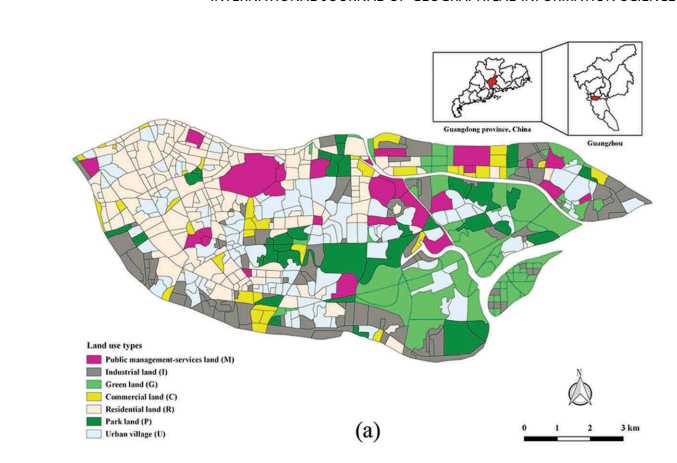
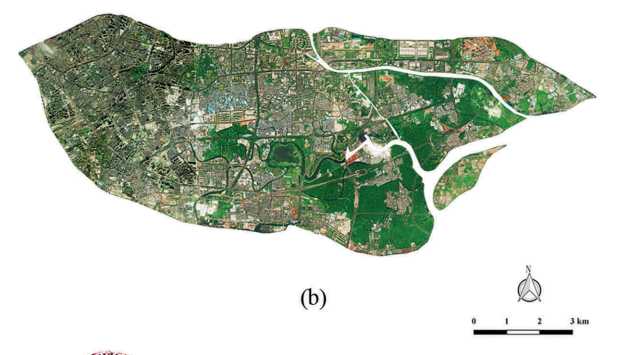
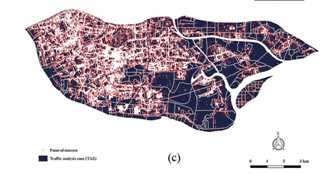
表1. 案例研究区域:广东省广州市海珠区。 (a)在交通分析区一级的单位内通过人工解释获得的城市土地使用数据; (b)Worldview-2卫星在研究区域内提供的高空间分辨率(HSR)遥感图像; 前面的黑线代表从OpenStreetMap(OSM)下载的道路; (c)高德兴趣点(POI)的空间分布密度。
③多源社交媒体数据
社交媒体数据包括OpenStreetMap(OSM)道路网络(http://www.open streepmap.org),高德POI和实时腾讯用户密度(RTUD)(http://heat.qq.com),用于补充HSR图像提取的特征,并丰富用于研究区域土地用途识别的其他信息。
我们研究中的POI由高德地图服务(http://lbs.amap.com/)提供,高德地图服务是中国最受欢迎和最大的网络地图服务提供商之一。 我们通过高德地图API(图1(c))从研究区域中的432个类别的大约123,915条记录中获得了POI(包括企业,商业场所,教育设施(幼儿园,小学和中学),居住社区,临床) 设施和风景名胜区。
RTUD是适用于t语义分类的新数据集,其中包含使用腾讯应用程序(例如,腾讯移动应用QQ(类似于Messenger的软件),微信(移动聊天软件),Soso Maps( Web地图服务和导航软件)以及其他提供LBS服务的移动应用程序。图2通过在25 m的空间分辨率下分别计算工作日和休息日数据的平均值来显示RTUD时间序列数据。
先前的研究表明,均值过滤是一种有效的社交媒体数据预处理方法,可以减少数据大小和计算需求,而不会造成太多信息丢失。
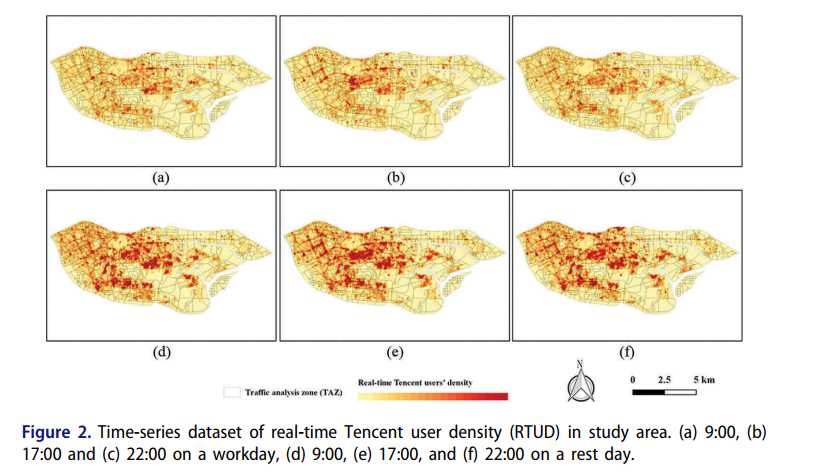
表2. 研究区域中实时腾讯用户密度(RTUD)的时间序列数据集。 (a)工作日9:00,(b)工作日17:00和(c)工作日22:00,(d)休息日9:00,(e)休息日17:00和(f)休息日22:00
3.方法
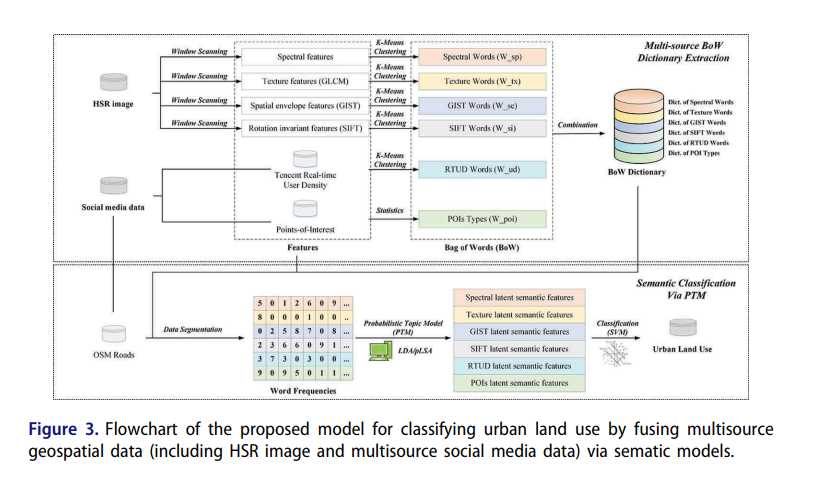
图3.通过语义模型融合多源地理空间数据(包括HSR图像和多源社交媒体数据)而提出的城市土地利用分类模型的流程图。
①研究方法总述(4步)
该模型的流程图如图3所示。我们的研究目的是通过融合HSR遥感图像和社交媒体数据中的多源特征,对主要的城市土地利用类型进行分类。在这项研究中,我们采用了以下四个步骤来确定每个交通分析区域(TAZ)中的城市土地利用类型。
首先,我们使用窗口扫描从遥感图像中提取特征。 提取的特征通过光谱,纹理和空间包络特征进行表征,并同时使用尺度不变特征变换(SIFT)提取旋转不变特征。
其次,我们使用k-means聚类方法将上一步中提取的特征和RTUD数据分为几类,并主观定义POI的类型。 我们获得了大量视觉单词,这些单词通过k-means算法进行聚类并被视为中级特征,以便将它们与低级原始特征和高级语义词汇特征区分开来,并构建了多源词典 BoW。
第三,我们基于开源的OSM道路网络数据在研究区域中描绘了TAZ,并计算了从每个TAZ中的HSR图像和社交媒体数据中提取的特征词。 通过使用PTM,我们将基于特征词出现频率的潜在语义特征挖掘到高维语义向量中。
最后,我们应用了多类支持向量机(SVM)模型。 我们使用在地面上验证的选定土地使用数据来训练SVM模型,以对城市土地使用类型进行分类,并评估语义特征不同组合下的分类性能。
②环境支持
我们的研究团队在Windows 8.1(×64)上使用C ++实现了以下所述的模型,包括CGAL(http://www.cgal.org),GDAL(http:// www.gdal.org/)、OpenCV(http://opencv.org/)和 LIBSVM(http://www.csie.ntu.edu.tw/~cjlin/libsvm/)。 基于LDA的主题模型的源代码可从普林斯顿大学(http://www.cs.princeton.edu/~blei/topicmo deling.html)获得。
3.1 空间特征提取
①HSR图像信息及利用
HSR图像包含丰富的光谱和空间信息。 在所有特征描述符中,HSR图像的光谱和纹理特征能够反映出地面成分的内部成分和色调变化。 SIFT特征描述符可以处理地面组件的模式识别的拉伸,旋转和视角变化,这已在图像分析中得到广泛应用。 本文从HSR图像中提取的模式类似于Zhong等人基于语义分配级别(SAL)的PTM模型中的模式。
②光谱特征的表示
为了降低从HSR图像提取光谱特征时的计算复杂性,我们采用具有一定大小的窗口和间隙,并为每个HSR图像提取每个波段的均值和标准差(STD)。 因此,第i个窗口中心的光谱特征 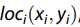 可以表示为
可以表示为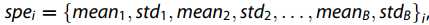 其中B表示频段计数。 我们可以继续一些均匀间隔的光谱特征向量。
其中B表示频段计数。 我们可以继续一些均匀间隔的光谱特征向量。
③纹理特征的表示
灰度共生矩阵(GLCM)有效描述图像和纹理的图案。 与光谱特征相似,我们将图像的灰度级压缩为八幅图像,并提取四个基于GLCM的Haralick特征统计量,包括每个窗口中具有一定大小的相关性,ASM,能量,对比度和同质性。设B为带宽,第i个窗口的纹理特征为: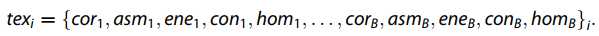
④SIFT(尺度不变特征变换)描述图像局部特征
在这项研究中,我们介绍了两种方法(SIFT和GIST)来描述图像的局部特征。
第一种方法是在每个窗口中计算SIFT功能。 先前的研究表明,当采用128维矢量表示SIFT特征时,它可以实现最佳的优化配准性能。为了降低计算成本,我们获得了HSR图像的第一部分,然后采用窗口扫描的方法来提取SIFT特征向量,其中第i个窗口中心的SIFT特征为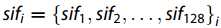
在描述整个场景时,我们通常使用部分模式而不是全局模式。由于HSR图像的复杂性和不确定性,该方法不仅计算和存储成本高,而且在两个场景相同但具有不同的内部地面分量空间分布的情况下也会导致误分类。为了解决这个问题,我们引入了奥利维亚等人提出的GIST空间包络特征,其在宏观层面上描述图像场景的有效性已在最近的研究中得到证实。
⑤GIST(空间包络)描述图像局部特征
SIFT描述符最初旨在识别在不同条件下出现的同一对象,并且具有很强的区分能力。 “ GIST”是场景的抽象表示,可以自发激活场景类别的内存表示,并且在识别自然场景类别例如 山和海岸。 GIST被认为是一种常见的空间包络特征描述符,可以充分描述五个不同的空间包络场景,包括自然度,开放度,粗糙度,膨胀度和坚固性。 在我们的研究中,我们将每个窗口划分为4x4,并计算每个波段的GIST特征。 与SIFT相似,第i个窗口的主要GIST特征是: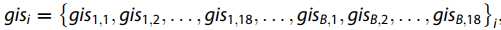 其中,B代表带宽。
其中,B代表带宽。
⑥社交媒体数据
转折句:
尽管遥感数据可以充分代表地面组成部分的物理属性,但不能说明人类活动造成的社会经济属性。
社交媒体数据可以补充有关人类活动的信息。 先前的研究表明,POI的分布可以有效地用于说明地块的功能。在这里,我们将POI类别介绍为一种反映社会经济属性的虚拟词语类型。 然后可以通过过滤的RTUD时间序列获得人类活动的模式,其时间和值很重要。 城市居民活动的特点与周围环境和城市功能区密切相关。 因此,RTUD的时间序列可以表示某些区域的功能模式。 因此,我们将每个窗口的RTUD模式描述为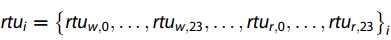 ,j表示研究区域内的第j个窗口,w和r分别代表工作日和休息日的时序曲线。
,j表示研究区域内的第j个窗口,w和r分别代表工作日和休息日的时序曲线。
3.2 建立多源BoW词典
①定义向量
假设某城市存在某个区域R,其多源特征可以描述为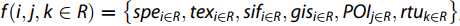 ,其中i,j和k分别指示R区域中RTUD数据的窗口中心,POI和栅格中心。 请注意,
,其中i,j和k分别指示R区域中RTUD数据的窗口中心,POI和栅格中心。 请注意,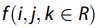 是一个多维向量。 我们使用k-means方法对BoW词典中的每个特征进行聚类并将其转换为某个虚拟词。 因此,区域R中的特征词可以描述为一个文档
是一个多维向量。 我们使用k-means方法对BoW词典中的每个特征进行聚类并将其转换为某个虚拟词。 因此,区域R中的特征词可以描述为一个文档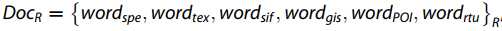 ,其中wordPOI是内部POI类别的集合,在此基础上,我们可以应用主题模型来识别和分类多源文档。
,其中wordPOI是内部POI类别的集合,在此基础上,我们可以应用主题模型来识别和分类多源文档。
②建立过程
需要在较大的研究区域中提取大量的特征数据,这会导致在聚类过程中效率低下。 当特征数量超过500,000时,我们选择了500,000个数据点的随机子集,通过k均值聚类进行初步聚类,并通过轮廓估计进行迭代以优化结果。 基于通过初步聚类过程获得的聚类中心,计算出欧几里得距离,以估计每个中心与其他未标记语义特征向量之间的相似性; 未标记的特征被分类为最接近的特征。
3.3 通过PTMs和SVM进行语义分类
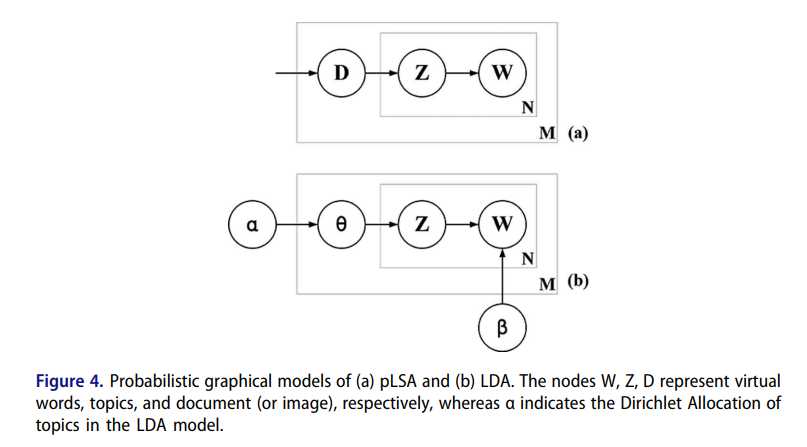
图4:(a)pLSA和(b)LDA的概率图形模型。 节点W,Z,D分别表示虚拟词,主题和文档(或图像),而α表示节点的Dirichlet分配
LDA模型中的主题。
如图4所示,PTMs(包括概率潜在语义分析(pLSA)和LDA模型)旨在评估生成的虚拟单词和挖掘文档的潜在语义特征。 PTMs已被广泛应用于NLP领域。 而且,近年来在HSR图像的场景分类中取得了令人满意的结果。
①LDA解pLSA的过拟合问题
pLSA利用文档,主题和单词之间的关系,分解单词wj的概率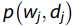 ,这出现在BoW与概率和总概率公式结合的论文中。
,这出现在BoW与概率和总概率公式结合的论文中。
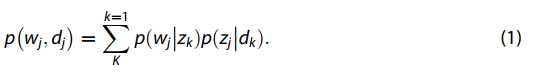
在等式(1)中,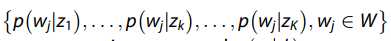 展示了潜在语义空间中的基本向量,而
展示了潜在语义空间中的基本向量,而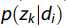 代表主题分布,可以将其视为给定文档的语义特征。 因此,我们将向量集
代表主题分布,可以将其视为给定文档的语义特征。 因此,我们将向量集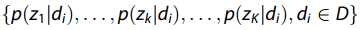 应用于表示文档。
应用于表示文档。
pLSA模型存在过拟合的问题,因为它表示的每个文档只是某个主题离散概率的数字形式。 它无法在训练数据集之外挖掘语义特征。 为了解决这些问题,新的基于LDA的pLSA模型假设语义困惑参数受Dirichlet分配的约束。对于具有K个给定主题的某些文档,向量组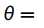
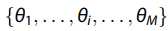 中的每个向量
中的每个向量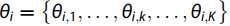 都遵循带有参数
都遵循带有参数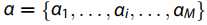 的Dirichlet分配。 LDA定义原始潜在语义分布的概率函数是解决pLSA缺点的关键。
的Dirichlet分配。 LDA定义原始潜在语义分布的概率函数是解决pLSA缺点的关键。
②PTMs和SVM进行语义分类的过程
基于OSM道路网络数据,我们将研究区域划分为几个TAZ。 将每个TAZ视为一个地块,我们计算了所有要素类中视觉单词的分布频率,并将结果输入到PTMs模型中,以计算高维潜在语义特征。
然后,将在先前的研究中已被证明在对高维特征进行分类方面具有很高的效率的SVM应用于我们提出的模型中,以识别TAZ中的城市土地利用类型。 由于SVM是二进制分类器,因此我们采用多分类器组合的方法来训练和分类每个TAZ中的潜在语义特征。
最终分类结果由每个TAZ中最常出现的类别给出。
③本研究的训练过程
在这项研究中,我们在每个类别中选择50%的训练样本,这些样本的特征被随机组合并输入到多类别SVM分类器中。 其余50%的数据用作测试数据。 SVM分类器由LIBSVM软件包实现。
在训练过程中,我们使用训练数据集的25%作为验证数据集,并使用Kappa评估模型校准。 需要调整带有径向基函数(RBF)内核的SVM的两个敏感参数,惩罚C因子和内核参数NU。 我们设置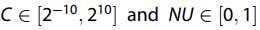 并通过网格搜索方法搜索最佳参数,其中优化目标是最大化Kappa。
并通过网格搜索方法搜索最佳参数,其中优化目标是最大化Kappa。
4.结果
4.1 通过不同的特征组合来进行场景分类
表2:通过语义特征进行不同组合的场景分类结果
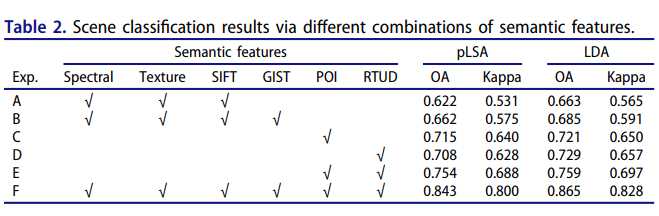

图5:通过语义特征的不同组合得出的基于LDA的土地利用分类结果。(a)光谱,纹理和SIFT,(b)光谱,纹理,SIFT和GIST,(c)POI,(d)RTUD,(e)POI和RTUD,以及(f)光谱,纹理,SIFT,GIST ,POI和RTUD。
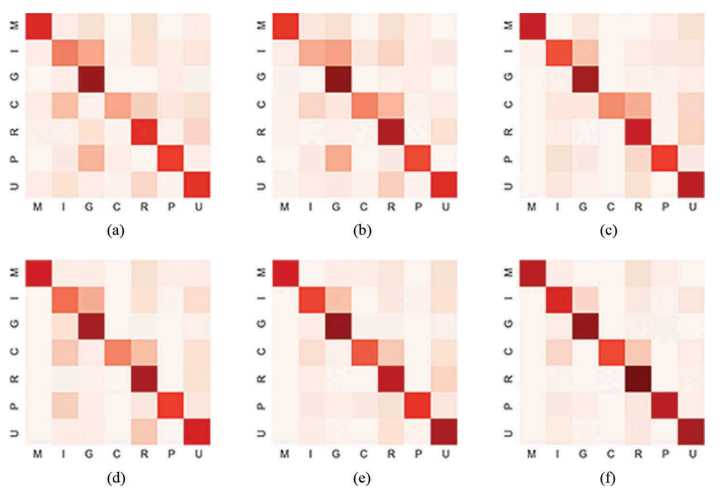

图6:通过pLSA的场景分类结果混淆矩阵。 功能组合:(a)光谱,纹理和SIFT,(b)光谱,纹理和SIFT。 GIST,(c)POI,(d)RTUD,(e)POI和RTUD,以及(f)光谱,纹理,SIFT,GIST,POI和RTUD。
表2显示了不同的特征组合方法及其平均精度,图6显示了每种组合的分类结果(图5)中最接近平均准确度的混淆矩阵。 为了确保分类结果的可靠性和稳定性,我们对每组重复进行了100次分类过程,并计算了平均分类准确性。
①LDA模型和pLSA模型对比并分析其原因
如表2和图5所示,HSR图像或社交媒体数据中基于PTM的语义特征可用于区分地块的功能类型。 关于SVM分类的准确性,LDA模型生成的语义特征比pLSA模型生成的语义特征稍高。 现有研究表明,在测量预测新文档的复杂性时,LDA比pLSA更好。
我们的研究区域位于广州市区,高度混合的土地利用斑块作为自然保护区中的主题混合文档,这将使LDA模型产生更好的分类结果。因此,这项研究采用了额外的二进制除法程序来优化LDA模型的敏感超参数α,相关参数对分类结果的准确性的影响将在以下部分讨论。
② 从结果分析仅使用HSR图像进行研究的局限性
传统的基于HSR图像的场景分类方法仅考虑光谱,纹理和SIFT特征,只能在复杂的城市土地利用分类中获得较差的分类精度。将GIST特征用于宏观描述场景并不能提高分类的准确性,因为使用从遥感影像中提取的自然-物理语义特征对区分高度混合的土地利用斑块具有挑战性。
如图6(a,b),7(a,b)和表3所示,仅应用纹理特征时,商业用地(图5(a,b)中的#1和#5)很容易与住宅混合 土地,工业用地和城市村庄,因为商业用地通常广泛分布在遥感影像中,并表现出复杂的空间格局。因此,从遥感图像中提取的自然物理特征不能反映城市功能区的内部特性和结构。
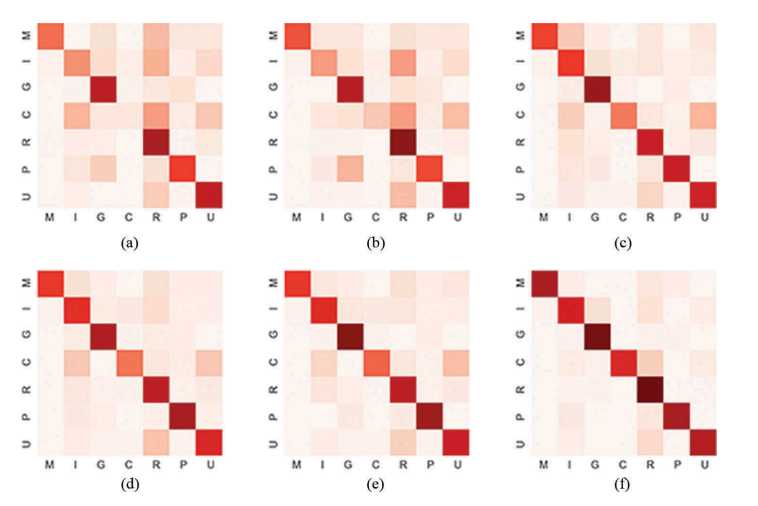

图7.通过LDA的场景分类结果混淆矩阵。 功能组合:(a)光谱,纹理和SIFT,(b)光谱,纹理,SIFT和GIST,(c)POI,(d)RTUD,(e)POI和RTUD,以及(f)光谱,纹理, SIFT,GIST,POI和RTUD。
③社交媒体数据对结果的影响
图6(c,d),7(c,d)显示了从社交媒体数据(如POI和RTUD)中提取的语义特征,它们是城市土地利用类型与人类活动(包括商业用地和居住用地)的高度相关性。 这两种数据的分类准确性明显提高; 总准确度和Kappa分别提高9.95%和16.58%。
与POI相比,RTUD可以有效地区分居住区和城市村庄,这可以说明时间序列人口密度更能够反映城市区域内地面真实土地用途的类型。 基于POI的语义特征比RTUD更好地区分了城市村庄,这说明POI的分布与人们的室内习惯相比在城市村庄识别中具有更大的优势。
如图5(c,d)所示,可以通过基于RTUD的语义特征来充分识别人类活动稀少的城市区域,例如绿地和公园地。 因此,将POI和基于RTUD的语义特征组合在一起进行分类。 与每种类型的特征(C组和D组)的独立应用相比,该模型获得了更好的结果,后者的总体准确度(OA)和Kappa分别增加了0.03-0.05和0.04-0.05。
④当同时使用HSR图像和社交媒体数据时得到的效果最好
在特征组合测试的F组中,我们将所有语义特征输入SVM以对土地利用类型进行分类,并获得最佳的分类结果,其中OA和Kappa超过0.80。 从实验结果中,我们发现可以区分人类活动稀疏的区域(例如绿地和公园用地)和土地使用类型复杂的区域(例如商业用地和居住用地)。例如, 当只考虑基于遥感或基于社交媒体的语义特征时,如图5#2所示,当仅将公共管理服务用地划分为公园用地(图5(b)#2)和住宅用地(图5(e)#2)时,分类不正确。
但是,通过融合两个建议的主要特征可以正确地识别地块(图5(f)#2)。 通过在建议的模型中将每个HSR区中的HSR图像的自然-物理特性和社交媒体数据的社会经济特性融合在一起,可以获得最佳的分类结果。
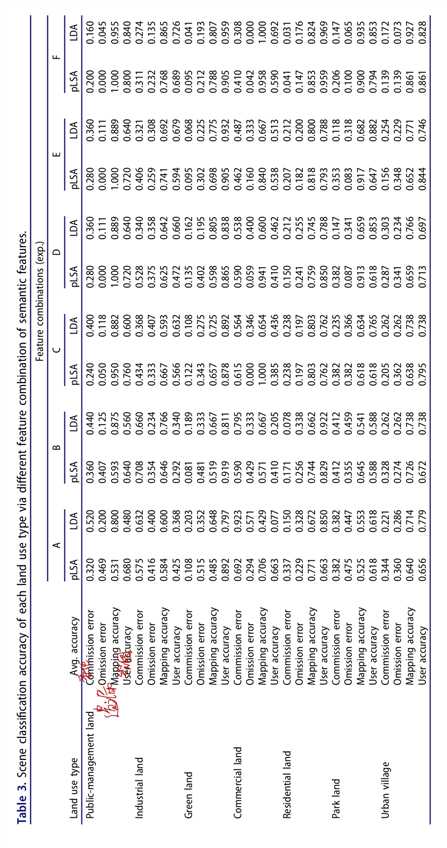
表3:通过语义特征的不同特征组合,每种土地利用类型的场景分类精度
4.2 参数敏感性分析
在本节中,我们评估分类精度与我们提出的模型的三个关键参数之间的相关性,其中包括样本窗口的大小,构成BoW的聚类类别的数量以及PTM中使用的主题数量。 在先前的研究中已经充分讨论了用于提取HSR图像中地面成分的自然物理特性的样本窗口的大小因子。 根据Zhong(2015)的结论,我们将HSR图像分割为25x25个像素的一组重叠图像块,以确定光谱,纹理,SIFT和GIST特征。 每对相邻的补丁设置为重叠15个像素,以保留足够的空间信息。
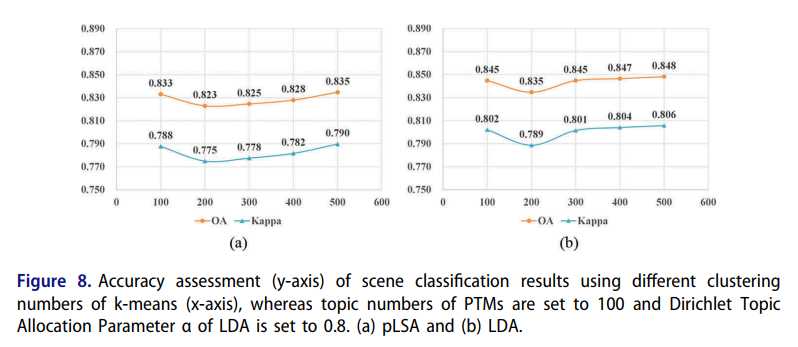
图8:将PTM的主题数设置为100,将LDA的Dirichlet主题分配参数α设置为0.8,使用不同的k均值聚类数(x轴)对场景分类结果进行准确性评估(y轴)。 (a)pLSA和(b)LDA。
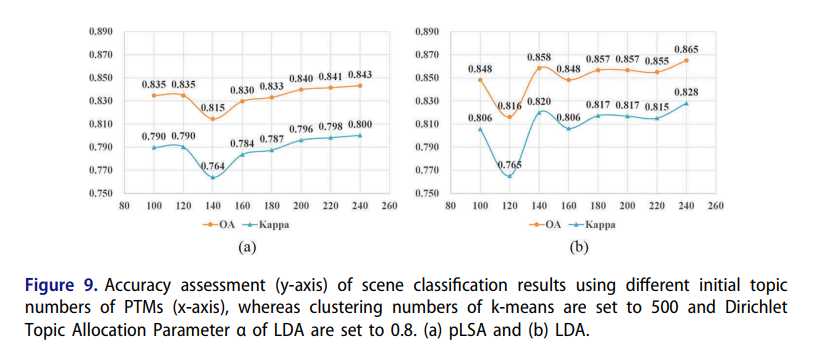
图9:将k均值的聚类数设置为500,将LDA的Dirichlet主题分配参数α设置为0.8时,使用不同的PTM初始主题数(x轴)对场景分类结果进行准确性评估(y轴)。 (a)pLSA和(b)LDA。
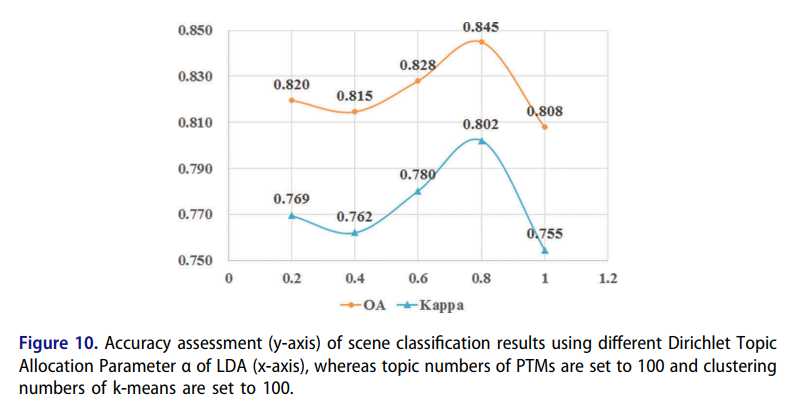
图10.PTM的主题数设置为100,k均值的聚类数设置为100时,使用LDA的不同Dirichlet主题分配参数α(x轴)进行场景分类结果的准确性评估(y轴)。
① 结合图分析各个参数敏感性
先前的几项研究表明,视觉单词的数量和初始主题对基于PTM的场景分类的分类准确性有重大影响。 但是,获得最佳主题的方法仍然是一个未解决的问题。
图8和图9显示了k均值簇数,PTM主题数和分类准确性之间的关系。pLSA和LDA模型都能够在某个窗口区域内获得相对较好的性能。 图8证明了k均值聚类数量的减少会导致基于PTM的场景分类的分类结果的准确性稳定并且几乎没有波动。
因此,在固定K值的情况下,pLSA和LDA的准确性水平表现出最初的明显偏差,并最终导致初始主题数量的增加(图9)。 由于Dirichlet主题分配参数α的最佳结果不确定,因此基于LDA的场景分类结果的准确性表现出很大的波动性(图10)
在多源空间数据融合场景分类领域,获取最佳初始主题数和α的方法尚未解决。 通过以上对模型参数的敏感性分析,我们分别选择了k均值的聚类数和PTM的初始主题数,分别为500和240。
5. 讨论
在有关HSR遥感和社交媒体数据分析的最新文献中,提高城市LULC分类准确度一直是一个重要问题。 但是,很少有研究有效地融合了从多源地理空间数据中提取的语义上的各种特征。 这项研究提出了一种有效的框架,通过融合从HSR图像和社交媒体数据(如高德兴趣点(POI)和RTUD)提取的语义特征,对城市土地利用进行分类。
①对本研究结果的讨论
这项研究结合了从PTM获得的几种不同的语义特征,并将其输入到SVM分类器中。 结果表明,HSR图像和社交媒体数据均可对城市土地利用类型进行高精度分类。
我们的发现与以前的研究一致,即HSR图像有利于识别农村地区的自然成分,而社交媒体数据的使用对于人口密度高的大都市区更好。将所有功能组合到SVM分类器中后,结果获得了最高的准确性(OA = 0.865,Kappa = 0.828),这表明我们的模型可以有效地融合HSR图像和社交媒体数据中的自然-物理和社会经济信息,从而获得更高分辨率的 城市土地利用分类。
②未来可进行的研究(数据方面)
一方面,在未来的研究中,我们期望引入更多开放的社交媒体资源(例如移动数据和浮动汽车轨迹); 另一方面,基于全球敏感性分析(GSA),将评估来自不同数据源的数据对不同类型土地利用类型进行分类的适用性。 此外,我们使用了大量的遥感图像样本和多种类型的开放式社交媒体数据来构建训练数据集,并对不同类别和准确性进行敏感性分析。 这项工作将帮助我们建立一个框架,以了解不同级别的城市土地使用模式。
③更细粒度的土地利用方式来替代TAZ
在许多涉及城市土地用途划分,场景分类和城市功能区分类的研究中,TAZ被用作基本单位,而在中国大城市的城市研究并不罕见。 他们的结果表明,使用TAZ来识别城市土地利用模式是合理和有效的。 但是,实际上确实存在城市地区的混合土地使用,甚至单个建筑物都具有不同的功能。 面对这个问题,多源地理空间数据,包括社交媒体数据和HSR图像,可能会提供一种新工具来量化土地使用的混合性,并在未来区分实际的土地使用情况和城市规划。 因此,在未来的研究中,应该确定更细粒度的土地利用方式来替代TAZ。
④土地混合使用问题
这项研究的目的是在语义模型的框架内探索多源空间数据的整合,从而有效地分析每个研究单位(TAZ)的主要土地利用类型。 但是,城市土地使用方式复杂多样,尤其是在中国的特大城市中。 例如,在我们的研究区域中,许多多功能土地用途与生活和商业功能混合在一起,这增加了通过人工解释或培训样本选择来识别土地用途的难度。 尽管我们已经对土地用途进行了硬分类,但已经获得了较高的准确性,但结果是基于对数据的准确和人工解释。 因此,在未来的工作中,应基于开放的社交媒体数据在未来的研究中考虑土地混合使用的问题。
6. 结论
研究课题的意义:
快速的城市发展导致城市内土地利用类型的多样化和复杂化。 由于城市规划者和政府决策者必须考虑到土地利用的现状,因此及时而充分的城市土地利用信息无疑将促进城市的可持续发展。 但是,城市土地利用方式的复杂性和融合性给准确有效地绘制城市土地利用绘图带来了巨大挑战。
本研究的框架步骤:
一个框架:通过融合从HSR遥感影像和多源社交媒体数据中提取的多源语义特征,在TAZ单位级别对主要城市土地利用类型进行分类。 首先,我们从HSR图像和开放的社交媒体数据(包括POI和RTUD)中提取了各种特征,并建立了基于k均值的BoW和所有特征类别的字典。 在第二步中,引入了包含pLSA和LDA的PTM以提取多源语义信息。 最后,我们将不同类型的语义特征融合并输入到广州海珠区的多类SVM分类器中。
结果:
结果表明,该模型可以有效地融合从HSR图像和多源社交媒体数据中提取的自然,物理和社会经济语义特征,以获得最高的城市土地利用分类精度(OA = 0.865,Kappa = 0.828)。
未来工作:
我们可能会继续从以下三个方面来研究融合模型:首先,发现各种开放式社交媒体数据在检测城市土地利用方面的潜力; 其次,利用该模型提高了城市土地利用融合模式检测的准确性。 最后,讨论应用从城市土地利用图提取的空间信息进行深度学习的可行性。