标签:gradient filter 因子 行人检测 pad 一个 超过 ima 一起
YOLO(You Only Look Once)是一个流行的目标检测方法,和Faster RCNN等state of the art方法比起来,主打检测速度快。截止到目前为止(2017年2月初),YOLO已经发布了两个版本,在下文中分别称为YOLO V1和YOLO V2。YOLO V2的代码目前作为Darknet的一部分开源在GitHub。在这篇博客中,记录了阅读YOLO两个版本论文中的重点内容,并着重总结V2版本的改进。
Update@2018/04: YOLO v3已经发布!可以参考我的博客论文 - YOLO v3。

这里不妨把YOLO V1论文“You Only Look Once: Unitied, Real-Time Object Detection”的摘要部分意译如下:
我们提出了一种新的物体检测方法YOLO。之前的目标检测方法大多把分类器重新调整用于检测(这里应该是在说以前的方法大多将检测问题看做分类问题,使用滑动窗提取特征并使用分类器进行分类)。我们将检测问题看做回归,分别给出bounding box的位置和对应的类别概率。对于给定输入图像,只需使用CNN网络计算一次,就同时给出bounding box位置和类别概率。由于整个pipeline都是同一个网络,所以很容易进行端到端的训练。
YOLO相当快。base model可以达到45fps,一个更小的model(Fast YOLO),可以达到155fps,同时mAP是其他可以实现实时检测方法的两倍。和目前的State of the art方法相比,YOLO的localization误差较大,但是对于背景有更低的误检(False Positives)。同时,YOLO能够学习到更加泛化的特征,例如艺术品中物体的检测等任务,表现很好。
和以往较为常见的方法,如HoG+SVM的行人检测,DPM,RCNN系方法等不同,YOLO接受image作为输入,直接输出bounding box的位置和对应位置为某一类的概率。我们可以把它和目前的State of the art的Faster RCNN方法对比。Faster RCNN方法需要两个网络RPN和Fast RCNN,其中前者负责接受图像输入,并提出proposal。后续Fast RCNN再给出这些proposal是某一类的概率。也正是因为这种“直来直去”的方法,YOLO才能达到这么快的速度。也真是令人感叹,网络参数够多,数据够多,什么映射关系都能学出来。。。下图就是YOLO的检测系统示意图。在test阶段,经过单个CNN网络前向计算后,再经过非极大值抑制,就可以给出检测结果。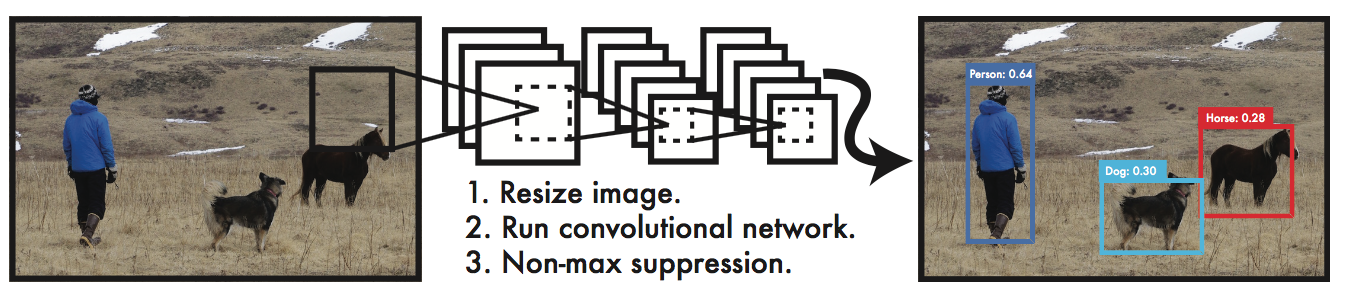
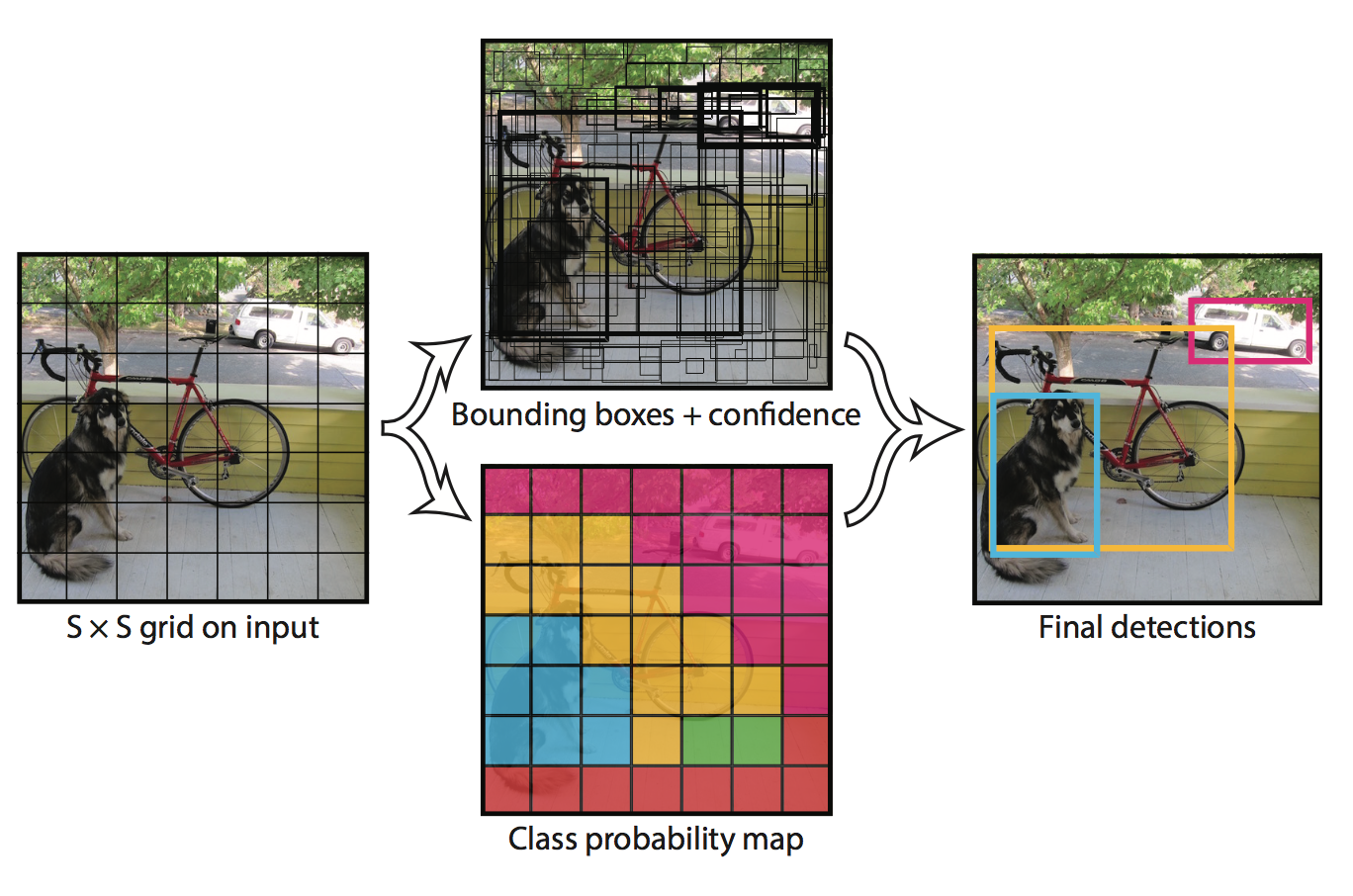
网络输出:每个bounding box对应于5个输出,分别是$x,y,w,h$和上述提到的置信度。其中,$x,y$代表bounding box的中心离开其所在grid cell边界的偏移。$w,h$代表bounding box真实宽高相对于整幅图像的比例。$x,y,w,h$这几个参数都已经被bounded到了区间$[0,1]$上。除此以外,每个grid cell还产生$C$个条件概率,$P(text{Class}_i|text{Object})$。注意,我们不管$B$的大小,每个grid cell只产生一组这样的概率。在test的非极大值抑制阶段,对于每个bounding box,我们应该按照下式衡量该框是否应该予以保留。
实际参数:在PASCAL VOC进行测试时,使用$S = 7$, $B=2$。由于共有20类,故$C=20$。所以,我们的网络输出大小为$7times 7 times 30$
Inspired by GoogLeNet,但是没有采取inception的结构,simply使用了$1times 1$的卷积核。base model共有24个卷积层,后面接2个全连接层,如下图所示。
另外,Fast YOLO使用了更小的网络结构(9个卷积层,且filter的数目也少了),其他部分完全一样。
同很多人一样,这里作者也是先在ImageNet上做了预训练。使用上图网络结构中的前20个卷积层,后面接一个average-pooling层和全连接层,在ImageNet 1000类数据集上训练了一周,达到了88%的top-5准确率。
由于Ren的论文提到给预训练的模型加上额外的卷积层和全连接层能够提升性能,所以我们加上了剩下的4个卷积层和2个全连接层,权值为随机初始化。同时,我们把网络输入的分辨率从$224times 224$提升到了$448 times 448$。
在最后一层,我们使用了线性激活函数;其它层使用了leaky ReLU激活函数。如下所示:
很重要的问题就是定义很好的loss function,为此,作者提出了以下几点说明:
loss函数的具体形式见下图(实在是不想打这一大串公式。。)。其中,$mathbb{1}_i$表示是否有目标出现在第$i$个grid cell。
$mathbb{1}_{i,j}$表示第$i$个grid cell的第$j$个bounding box是否对某个目标负责。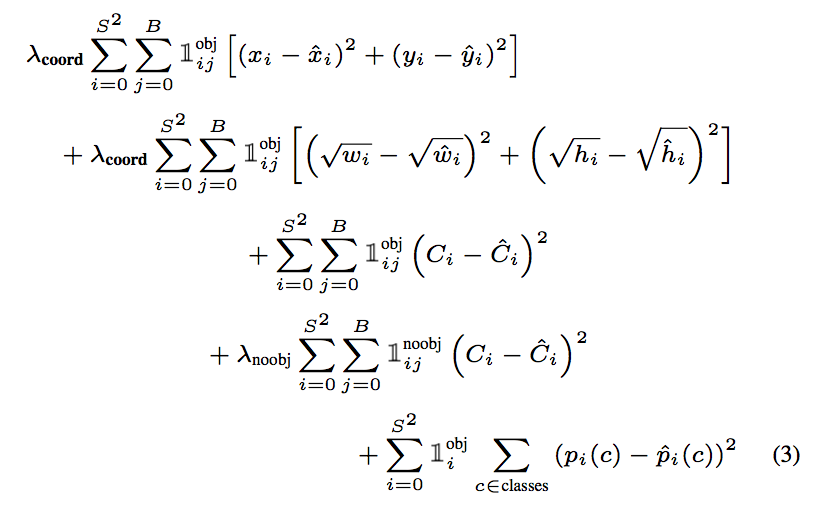
在进行反向传播时,由于loss都是二次形式,所以导数形式都是统一的。下面是Darknet中detection_layer.c中训练部分的代码。在代码中,计算了cost(也就是loss)和delta(也就是反向的导数),
|
|
YOLO V2是原作者在V1基础上做出改进后提出的。为了达到题目中所称的Better,Faster,Stronger的目标,主要改进点如下。当然,具体内容还是要深入论文。
下面,还是先把论文的摘要意译如下:
我们引入了YOLO 9000模型,它是实时物体检测的State of the art的工作,能够检测超过9K类目标。首先,我们对以前的工作(YOLO V1)做出了若干改进,使其成为了一种在实时检测方法内在PASCAL VOC和COCO上State of the art的效果。通过一种新颖的多尺度训练犯法(multi-scale training method), YOLO V2适用于不同大小尺寸输入的image,在精度和效率上达到了很好地trade-off。在67fps的速度下,VOC2007上达到了76.8mAP的精度。40fps时,达到了78.6mAP,已经超过了Faster RCNN with ResNet和SSD的精度,同时比它们更快!最后,我们提出了一种能够同时进行检测任务和分类任务的联合训练方法。使用这种方法,我们在COCO detection dataset和ImageNet classification dataset上同时训练模型。这种方法使得我们能够对那些没有label上detection data的数据做出detection的预测。我们使用ImageNet的detection任务做了验证。YOLO 9000在仅有200类中44类的detection data的情况下,仍然在ImageNet datection任务中取得了19.7mAP的成绩。对于不在COCO中的156类,YOLO9000成绩为16.0mAP。我们使得YOLO9000能够在保证实 大专栏 YOLO 论文阅读时的前提下对9K类目标进行检测。
根据论文结构的安排,将从Better,Faster和Stronger三个方面对论文提出的各条改进措施进行介绍。
在YOLO V1的基础上,作者提出了不少的改进来进一步提升算法的性能(mAP),主要改进措施包括网络结构的改进(第1,3,5,6条)和Anchor Box的引进(第3,4,5条)以及训练方法(第2,7条)。
Batch Normalization能够加快模型收敛,并提供一定的正则化。作者在每个conv层都加上了了BN层,同时去掉了原来模型中的drop out部分,这带来了2%的性能提升。
YOLO V1首先在ImageNet上以$224times 224$大小图像作为输入进行训练,之后在检测任务中提升到$448times 448$。这里,作者在训练完224大小的分类网络后,首先调整网络大小为$448times 448$,然后在ImageNet上进行fine tuning(10个epoch)。也就是得到了一个高分辨率的cls。再把它用detection上训练。这样,能够提升4%。
YOLO V1中直接在CNN后面街上全连接层,直接回归bounding box的参数。这里引入了Faster RCNN中的anchor box概念,不再直接回归bounding box的参数,而是相对于anchor box的参数。
作者去掉后面的fc层和最后一个max pooling层,以期得到更高分辨率的feature map。同时,shrink网络接受$416times 416$(而不是448)大小的输入image。这是因为我们想要最后的feature map大小是奇数,这样就能够得到一个center cell(比较大的目标,更有可能占据中间的位置)。由于YOLO conv-pooling的效应是将image downsamplig 32倍,所以最后feature map大小为$416/32 = 13$。
与YOLO V1不同的是,我们不再对同一个grid cell下的bounding box统一产生一个数量为$C$的类别概率,而是对于每一个bounding box都产生对应的$C$类概率。和YOLO V1一样的是,我们仍然产生confidence,意义也完全一样。
使用anchor后,我们的精度accuracy降低了,不过recall上来了。(这也较好理解。原来每个grid cell内部只有2个bounding box,造成recall不高。现在recall高上来了,accuracy会下降一些)。
在引入anchor box后,一个问题就是如何确定anchor的位置和大小?Faster RCNN中是手工选定的,每隔stride设定一个anchor,并根据不同的面积比例和长宽比例产生9个anchor box。在本文中,作者使用了聚类方法对如何选取anchor box做了探究。这点应该是论文中很有新意的地方。
这里对作者使用的方法不再过多赘述,强调以下两点:
使用不同的$k$,聚类实验结果如下,作者折中采用了$k = 5$。而且经过实验,发现当取$k=9$时候,已经能够超过Faster RCNN采用的手工固定anchor box的方法。下图右侧图是在COCO和VOC数据集上$k=5$的聚类后结果。这些box可以作为anchor box使用。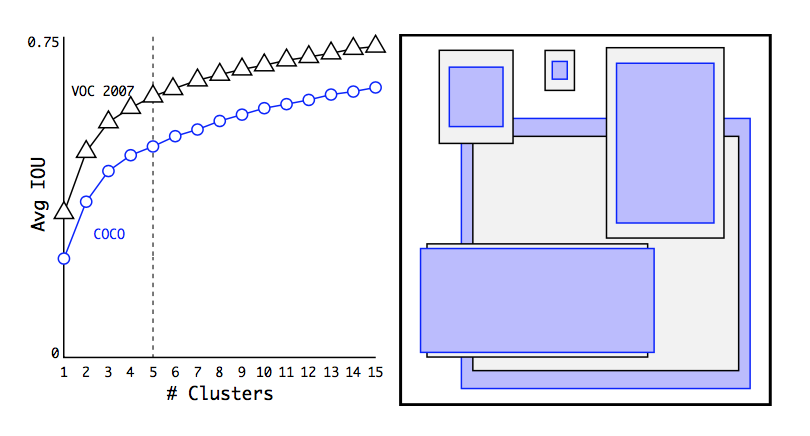
我们仍然延续了YOLO V1中的思路,预测box相对于grid cell的位置。使用sigmoid函数作为激活函数,使得最终输出值落在$[0, 1]$这个区间上。
在output的feature map上,对于每个cell(共计$13times 13$个),给出对应每个bounding box的输出$t_x$, $t_y$, $t_w$, $t_h$。每个cell共计$k=5$个bounding box。如何由这几个参数确定bounding box的真实位置呢?见下图。
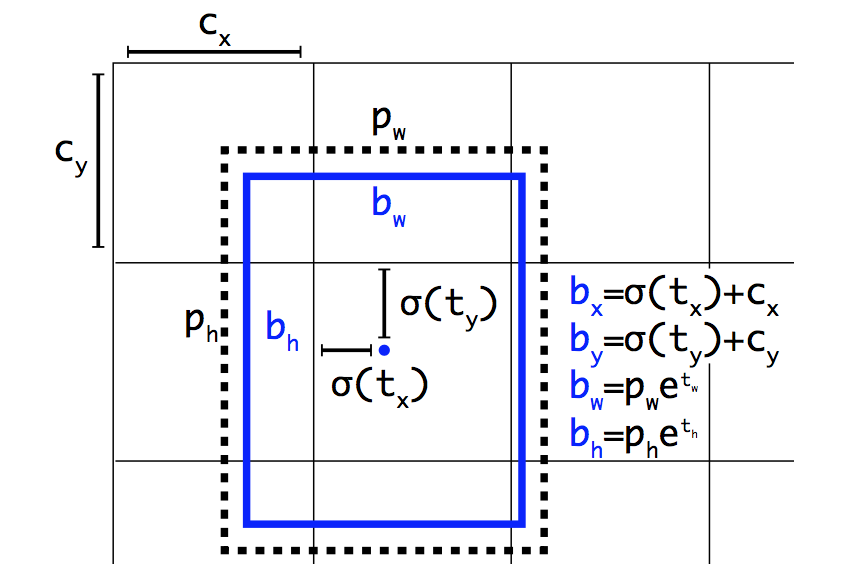
设该grid cell距离图像左上角的offset是$(c_x, c_y)$,那么bounding box的位置和宽高计算如下。注意,box的位置是相对于grid cell的,而宽高是相对于anchor box的。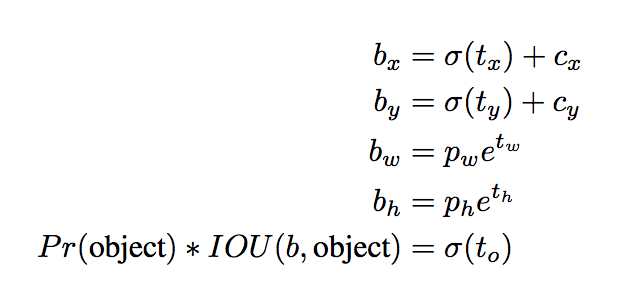
Darknet中的具体的实现代码如下(不停切换中英文输入实在是蛋疼,所以只有用我这蹩脚的英语来注释了。。。):
|
|
顺便说一下对bounding box的bp实现。具体代码如下:
|
|
接下来,我们看一下bp的计算。主要涉及到决定bounding box大小和位置的四个参数的回归,以及置信度$t_o$,以及$C$类分类概率。上面的代码中已经介绍了bounding box大小位置的四个参数的梯度计算。对于置信度$t_o$的计算,如下所示。
|
|
这里额外要说明的是,阅读代码可以发现,分类loss的计算方法和V1不同,不再使用MSELoss,而是使用了交叉熵损失函数。对应地,梯度计算的方法如下所示。不过这点在论文中貌似并没有体现。
|
|
这个trick是受Faster RCNN和SSD方法中使用多个不同feature map提高算法对不同分辨率目标物体的检测能力的启发,加入了一个pass-through层,直接将倒数第二层的$26times 26$大小的feature map加进来。
在具体实现时,是将higher resolution(也就是$26times 26$)的feature map stacking在一起。比如,原大小为$26times 26 times 512$的feature map,因为我们要将其变为$13times 13$大小,所以,将在空间上相近的点移到后面的channel上去,这部分可以参考Darknet中reorg_layer的实现。
使用这一扩展之后的feature map,提高了1%的性能提升。
在实际应用时,输入的图像大小有可能是变化的。我们也将这一点考虑进来。因为我们的网络是全卷积神经网络,只有conv和pooling层,没有全连接层,所以可以适应不同大小的图像输入。所以网络结构上是没问题的。
具体来说,在训练的时候,我们每隔一定的epoch(例如10)就随机改变网络的输入图像大小。由于我们的网络最终降采样的比例是$32$,所以随机生成的图像大小为$32$的倍数,即$lbrace 320, 352, dots, 608rbrace$。
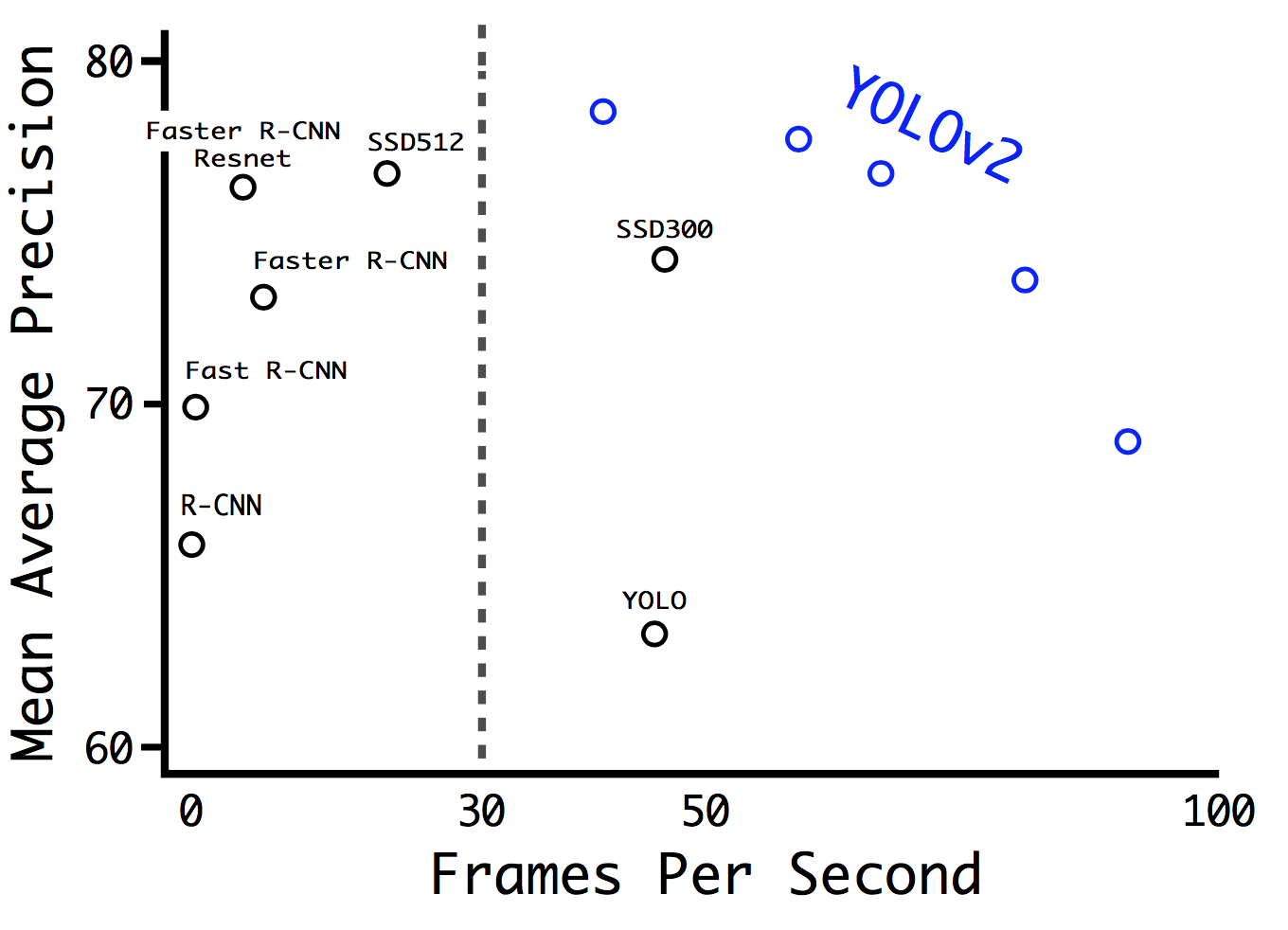
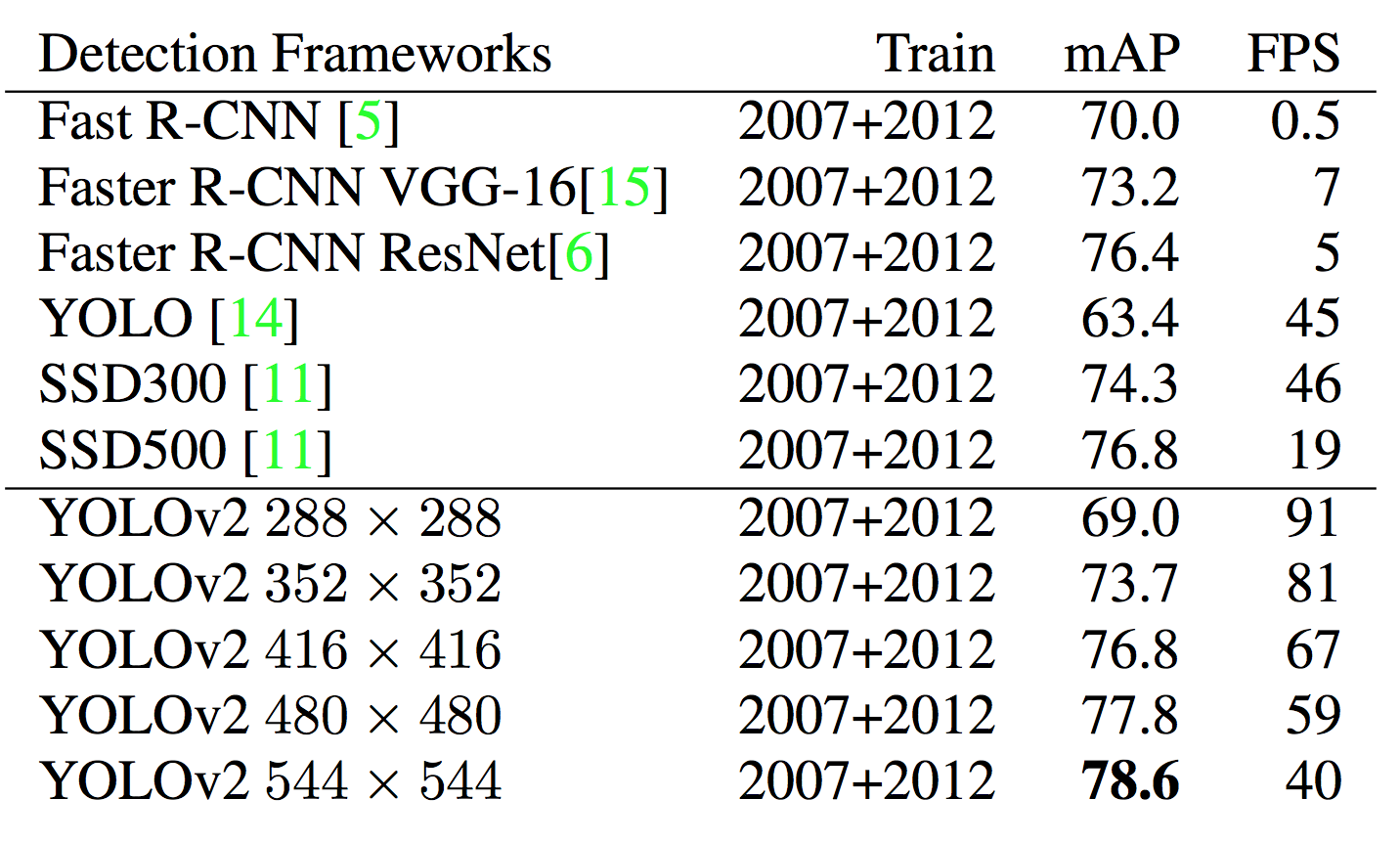
在实际使用中,如果输入图像的分辨率较低,YOLO V2可以在不错的精度下达到很快的检测速度。这可以被用应在计算能力有限的场合(无GPU或者GPU很弱)或多路视频信号的实时处理。如果输入图像的分辨率较高,YOLO V2可以作为state of the art的检测器,并仍能获得不错的检测速度。对于目前流行的检测方法(Faster RCNN,SSD,YOLO)的精度和帧率之间的关系,见下图。可以看到,作者在30fps处画了一条竖线,这是算法能否达到实时处理的分水岭。Faster RCNN败下阵来,而YOLO V2的不同点代表了不同输入图像分辨率下算法的表现。对于详细数据,见图下的表格对比(VOC 2007上进行测试)。
在Better这部分的末尾,作者给出了一个表格,指出了主要提升性能的措施。例外是网络结构上改为带Anchor box的全卷积网络结构(提升了recall,但对mAP基本无影响)和使用新的网络(计算量少了~33%)。
这部分的改进为网络结构的变化。包括Faster RCNN在内的很多检测方法都使用VGG-16作为base network。VGG-16精度够高但是计算量较大(对于大小为$224times 224$的单幅输入图像,卷积层就需要30.69B次浮点运算)。在YOLO V1中,我们的网络结构较为简单,在精度上不如VGG-16(ImageNet测试,88.0% vs 90.0%)。
在YOLO V2中,我们使用了一种新的网络结构Darknet-19(因为base network有19个卷积层)。和VGG相类似,我们的卷积核也都是$3times 3$大小,同时每次pooling操作后channel数double。另外,在NIN工作基础上,我们在网络最后使用了global average pooling层,同时使用$1times 1$大小的卷积核来做feature map的压缩(分辨率不变,channel减小,新的元素是原来相应位置不同channel的线性组合),同时使用了Batch Normalization技术。具体的网络结构见下表。Darknet-19计算量大大减小,同时精度超过了VGG-16。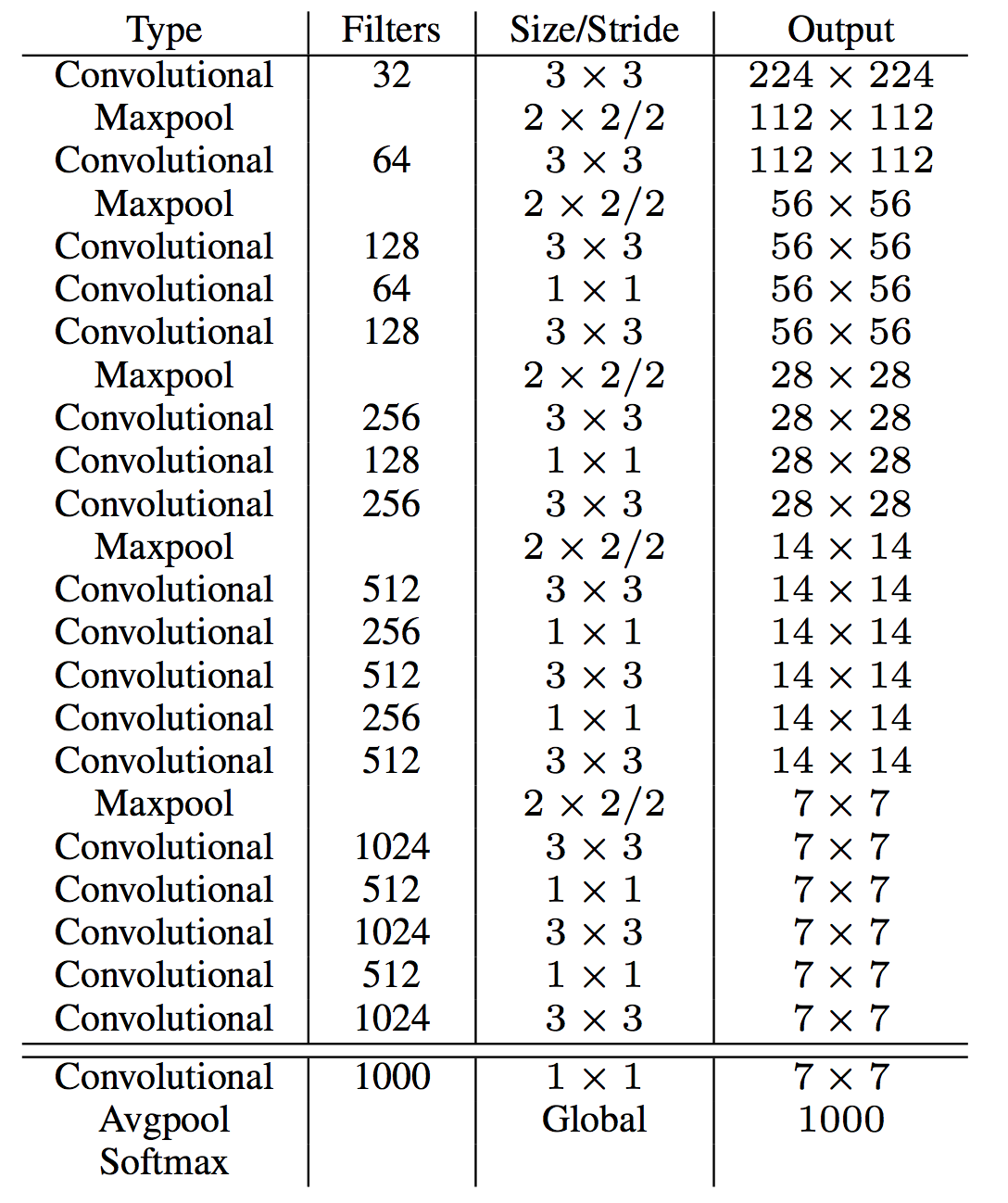
在训练过程中,首先在ImageNet 1K上进行分类器的训练。使用数据增强技术(如随机裁剪、旋转、饱和度变化等)。和上面的讨论相对应,首先使用$224times 224$大小的图像进行训练,再使用$448times 448$的图像进行fine tuning,具体训练参数设置可以参见论文和对应的代码。这里不再多说。
然后,我们对检测任务进行训练。对网络结构进行微调,去掉最后的卷积层(因为它是我们当初为了得到1K类的分类置信度加上去的),增加$3$个$3times 3$大小,channel数为$1024$的卷积层,并每个都跟着一个$1times 1$大小的卷积层,channel数由我们最终的检测任务需要的输出决定。对于VOC的检测任务来说,我们需要预测$5$个box,每个需要$5$个参数(相对位置,相对大小和置信度),同时$20$个类别的置信度,所以输出共$5times(5+20)=125$。从YOLO V2的yolo_voc.cfg文件中,我们也可以看到如下的对应结构:
|
|
同时,加上上文提到的pass-through结构。
未完待续
标签:gradient filter 因子 行人检测 pad 一个 超过 ima 一起
原文地址:https://www.cnblogs.com/lijianming180/p/12262470.html