标签:直接 对比 win64 name def 取数 windows 错误 cgi
小编也是最近在学习数据挖掘,看到了第三章用决策树预测获胜的球队。然而,NBA官网早就改版了,Export不能全部下载一年的数据记录,只能按月,而且我也下载不了。想了想,就只能爬取了。话不多说。
小编最开始用的Xpath,感觉路径有点麻烦,而且速度好像也没有BeautifulSoup快,所以小编就选用了pyquery和BeautifulSoup两个方法实现爬取数据。
首先,先查看网站,看到每月的数据,对应的url与月份有关,因此定义函数用于获取每月的数据,输入变量为月份。
下面的函数为pyquery的方法。
import requests from pyquery import PyQuery as pq from bs4 import BeautifulSoup import csv headers = { ‘user-agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36‘ } def get_data_pyquery(month): # 构造请求url url = ‘https://www.basketball-reference.com/leagues/NBA_2014_games-{}.html‘.format(month) result = requests.get(url, headers=headers).text doc = pq(result) # 用于存储表头 header = [] # 解析html for thead in doc.find(‘thead tr th‘).items(): text = thead.text() # 忽略空白符 # print(text) if(len(text)>2): header.append(text) # 存储数据 # print(header) data_all = [] for tr in doc(‘tbody tr‘).items(): data = [] try: data.append(tr.find(‘th‘).text()) for i in ([t.text() for t in tr(‘td‘).items()]):
# 用于清除‘OT’不想关的数据 if i and not(‘OT‘ in i): data.append(i) # print(data) data_all.append(data) # print(data_all) except: print(‘有点错误,已忽略‘) return header,data_all
下面的为BeautifulSoup:
def get_data_bs4(month): url = ‘https://www.basketball-reference.com/leagues/NBA_2014_games-{}.html‘.format(month) result = requests.get(url).text soup = BeautifulSoup(result,"lxml") data_all = [] for i in range(len(soup.tbody.find_all("tr"))): data = [] # 添加时间 data.append(soup.tbody.find_all("tr")[i].find_all("th")[0].getText()) for j in range(len(soup.find_all("tr")[i].find_all("td"))): data.append(soup.find_all("tr")[i].find_all("td")[j].getText()) # 添加没次的数据 data_all.append(data) # print(data_all) return data_all
这种方法有待完善,爬取的数据不是很全,有纰漏。(小编懒,不改了)
小编着重 用pyquery的方法。
接下来上主函数:
def get_csv(): i = 0 a = 0 months = [‘october‘,‘november‘,‘december‘,‘january‘,‘february‘,‘march‘,‘april‘,‘may‘,‘june‘] with open(‘NBA13_14.csv‘, ‘w‘)as f: writer = csv.writer(f) for month in months: header,data = get_data_pyquery(month) if i == 0: writer.writerow(header) i += 1 writer.writerows(data) a += 1 print("第{}个月份 写入完毕".format(a)) print("NBA 2012-2014 共{}月份的数据写入完毕!!".format(str(i)))
输出结果: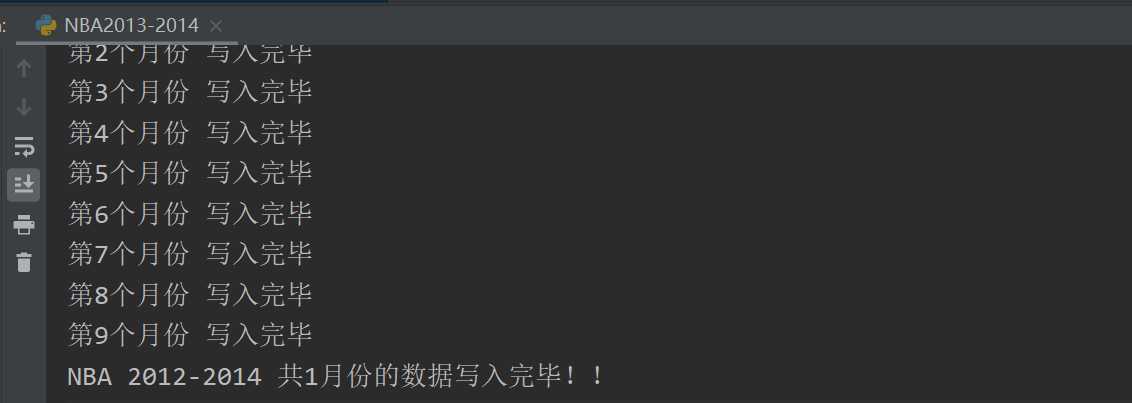
上述代码得到csv格式,注意:
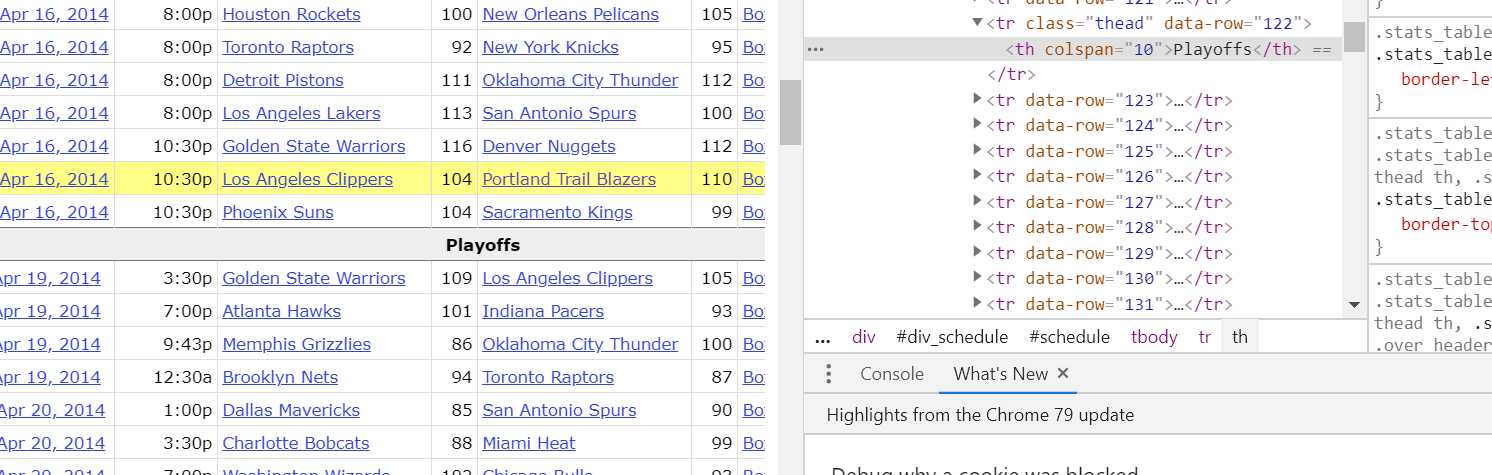
在4月份的数据中,有一行不符合规则:
小编用的try,except,直接忽略错误,但同时Playoffs也写入到了文件中。
Playoffs,在得到的csv表格中,删除即可。
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
下面获取上一个赛季的比赛记录,这里的代码需要重新写:
一开始,小编还是按照网址:view-source:https://www.basketball-reference.com/leagues/NBA_2013_standings.html
右击检查,查找对应的源代码,如果直接查看网页源代码的化,确实可以看到对应的代码。于是小编就按照看到的写,最后发现数据对不上。
小编查看对应的源代码,发现: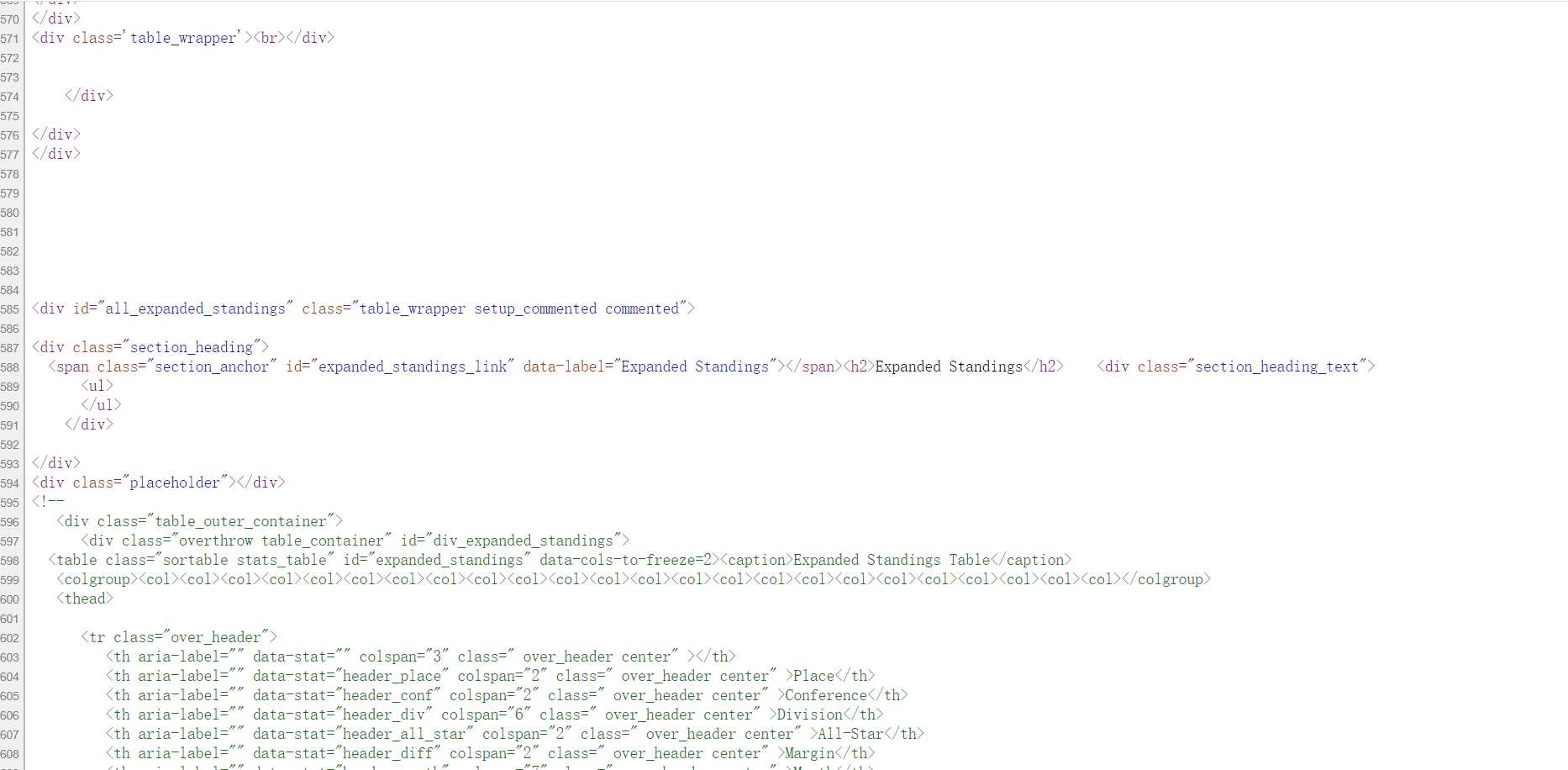
小编发现,想爬取的数据都在 注释里面。那想必是网页在加载的过程中有JS的动态渲染。这是小编想用selenium或这splash访问,结果都是TimeOuts,出现延迟。
这是,Embed this Table。弹出来了JS代码的一个链接。发现里面的网址对应代码有想要的数据。与原来的对比了一下,HTML结构一致,那么就可以进行爬取了。
下面直接上代码,小编用的Beautifulsoup,当然pyquery也可以,感兴趣的可以自己试一下。
from bs4 import BeautifulSoup import requests import csv headers = { ‘user-agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36‘ } def get_data_bs4(url): html = requests.get(url).text soup = BeautifulSoup(html, ‘lxml‘) # 要插入的数据 data_all = [] header = [] tr = soup.find_all(name=‘tr‘)[1] for th in tr.find_all(name=‘th‘): header.append(th.string) # print(header) data_all.append(header) # 下面来获取数据 tbody = soup.find(name=‘tbody‘) for tr in tbody.find_all(name=‘tr‘): data = [] data.append(tr.th.string) for td in tr.find_all(name=‘td‘): data.append(td.string) data_all.append(data) return data_all def get_csv(data_all): with open(‘NBA12-13.csv‘, ‘w‘) as f: writer = csv.writer(f) for i, data in enumerate(data_all): writer.writerow(data) print("第 {} 名数据下载完毕".format(i + 1)) print("文件下载完毕") if __name__ == ‘__main__‘: url = ‘https://widgets.sports-reference.com/wg.fcgi?css=1&site=bbr&url=%2Fleagues%2FNBA_2013_standings.html&div=div_expanded_standings‘ data = get_data_bs4(url) get_csv(data)
完毕!!!!!
标签:直接 对比 win64 name def 取数 windows 错误 cgi
原文地址:https://www.cnblogs.com/a-runner/p/12261995.html