标签:存在 href mode base info size 写入 hbase 爬取
2,学习spark视频:https://www.bilibili.com/video/av62881491 第59到65集
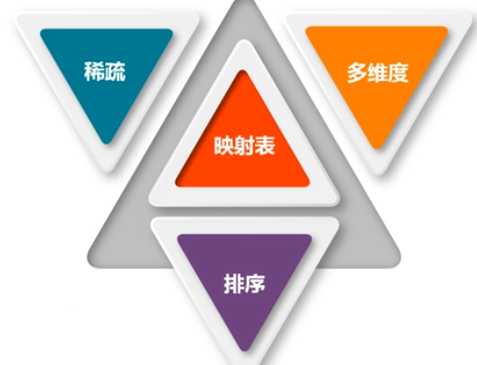
keys的功能:Pair RDD指键值对RDD

values的功能:

sortByKey()方法:常用,根据key进行排序,默认升序排序(默认参数为true)
sortBy()方法:根据value进行排序

文件数据读写:
1,本地数据文件读写:输入错误语句,不会报错,只有遇到一次动作类型操作才会报错(惰性机制)
读操作:当读取的是一个目录时,会把目录下所有文件都读进去生成一个RDD
写操作:指定的目录中writeback文件必须是不存在的,执行写操作时才创建
写入后会在指定目录下会生成的,当只有一个分区时,只会生成part-00000开头文件和_SUCCESS开头文件
2,hdfs文件内容读写:与读取本地文件的操作一致
3,JSON文件内容读写:scala中与json解析操作有关的库(scala.util.parsing.json.JSON)

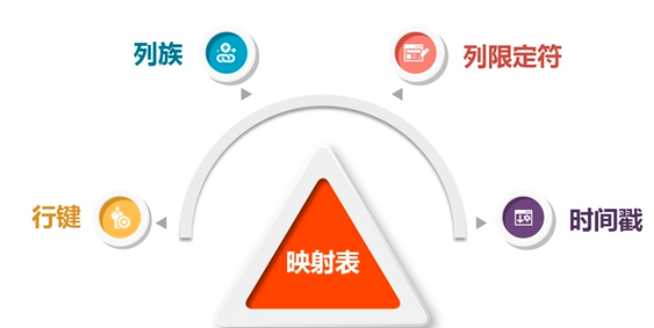
4,读取HBASE数据:HBASE通过(表名,行键,列族,列限定符)确定一个单元格,一个数据
3,遇到的问题:对用spark读写HBASE的数据不太熟练,按照教程没有执行通过
4,明天计划继续学习Spark和学习爬取动态数据
标签:存在 href mode base info size 写入 hbase 爬取
原文地址:https://www.cnblogs.com/lq13035130506/p/12267309.html