标签:batch 叠加 att ret 提高 ini 回归 表示 for
多层感知机在单层神经网络的基础上引入了一到多个隐藏层。多层感知机的隐藏层中的神经元和输入层中各个输入完全连接,输出层中的神经元和隐藏层中的各个神经元也完全连接。
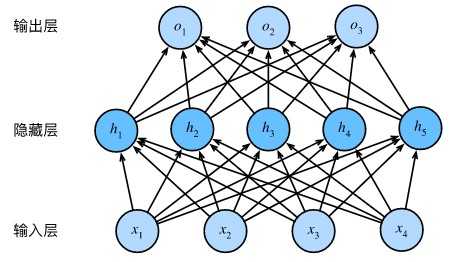
若对每个全连接层做仿射变换,无论添加多少隐藏层都仍然等价于仅含输出层的单层神经网络。
具体来说,给定一个小批量样本\(\boldsymbol{X} \in \mathbb{R}^{n \times d}\),其批量大小为\(n\),输入个数为\(d\)。假设多层感知机只有一个隐藏层,其中隐藏单元个数为\(h\)。记隐藏层的输出(也称为隐藏层变量或隐藏变量)为\(\boldsymbol{H}\),有\(\boldsymbol{H} \in \mathbb{R}^{n \times h}\)。因为隐藏层和输出层均是全连接层,可以设隐藏层的权重参数和偏差参数分别为\(\boldsymbol{W}_h \in \mathbb{R}^{d \times h}\)和 \(\boldsymbol{b}_h \in \mathbb{R}^{1 \times h}\),输出层的权重和偏差参数分别为\(\boldsymbol{W}_o \in \mathbb{R}^{h \times q}\)和\(\boldsymbol{b}_o \in \mathbb{R}^{1 \times q}\)。
我们先来看一种含单隐藏层的多层感知机的设计。其输出\(\boldsymbol{O} \in \mathbb{R}^{n \times q}\)的计算为
\[ \begin{aligned} \boldsymbol{H} &= \boldsymbol{X} \boldsymbol{W}_h + \boldsymbol{b}_h,\\boldsymbol{O} &= \boldsymbol{H} \boldsymbol{W}_o + \boldsymbol{b}_o, \end{aligned} \]
也就是将隐藏层的输出直接作为输出层的输入。如果将以上两个式子联立起来,可以得到
\[ \boldsymbol{O} = (\boldsymbol{X} \boldsymbol{W}_h + \boldsymbol{b}_h)\boldsymbol{W}_o + \boldsymbol{b}_o = \boldsymbol{X} \boldsymbol{W}_h\boldsymbol{W}_o + \boldsymbol{b}_h \boldsymbol{W}_o + \boldsymbol{b}_o. \]
从联立后的式子可以看出,虽然神经网络引入了隐藏层,却依然等价于一个单层神经网络:其中输出层权重参数为\(\boldsymbol{W}_h\boldsymbol{W}_o\),偏差参数为\(\boldsymbol{b}_h \boldsymbol{W}_o + \boldsymbol{b}_o\)。不难发现,即便再添加更多的隐藏层,以上设计依然只能与仅含输出层的单层神经网络等价。
上述问题的根源在于全连接层只是对数据做仿射变换(affine transformation),而多个仿射变换的叠加仍然是一个仿射变换。解决问题的一个方法是引入非线性变换,例如对隐藏变量使用按元素运算的非线性函数进行变换,然后再作为下一个全连接层的输入。这个非线性函数被称为激活函数(activation function)。下面我们介绍几个常用的激活函数。
ReLU(rectified linear unit)函数提供了一个很简单的非线性变换。给定元素\(x\),该函数定义为
\[\text{ReLU}(x) = \max(x, 0).\]
可以看出,ReLU函数只保留正数元素,并将负数元素清零。
sigmoid函数可以将元素的值变换到0和1之间:
\[\text{sigmoid}(x) = \frac{1}{1 + \exp(-x)}.\]
sigmoid函数在早期的神经网络中较为普遍,但它目前逐渐被更简单的ReLU函数取代。当输入接近0时,sigmoid函数接近线性变换。
tanh(双曲正切)函数可以将元素的值变换到-1和1之间:
\[\text{tanh}(x) = \frac{1 - \exp(-2x)}{1 + \exp(-2x)}.\]
当输入接近0时,tanh函数接近线性变换。虽然该函数的形状和sigmoid函数的形状很像,但tanh函数在坐标系的原点上对称。
依据链式法则,tanh函数的导数
\[\text{tanh}'(x) = 1 - \text{tanh}^2(x).\]
当输入为0时,tanh函数的导数达到最大值1;当输入越偏离0时,tanh函数的导数越接近0。
多层感知机就是含有至少一个隐藏层的由全连接层组成的神经网络,且每个隐藏层的输出通过激活函数进行变换。多层感知机的层数和各隐藏层中隐藏单元个数都是超参数。以单隐藏层为例并沿用本节之前定义的符号,多层感知机按以下方式计算输出:
\[ \begin{aligned} \boldsymbol{H} &= \phi(\boldsymbol{X} \boldsymbol{W}_h + \boldsymbol{b}_h),\\boldsymbol{O} &= \boldsymbol{H} \boldsymbol{W}_o + \boldsymbol{b}_o, \end{aligned} \]
其中\(\phi\)表示激活函数。在分类问题中,我们可以对输出\(\boldsymbol{O}\)做softmax运算,并使用softmax回归中的交叉熵损失函数。
在回归问题中,我们将输出层的输出个数设为1,并将输出\(\boldsymbol{O}\)直接提供给线性回归中使用的平方损失函数。
%matplotlib inline
import d2lzh as d2l
from mxnet import nd
from mxnet.gluon import loss as gloss
# 获取和读取数据
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 定义模型初始参数
num_inputs, num_outputs, num_hiddens = 784, 10, 128
# 每一层都需要定义初始参数
W1 = nd.random.normal(scale=0.01, shape=(num_inputs, num_hiddens))
b1 = nd.zeros(num_hiddens)
W2 = nd.random.normal(scale=0.01, shape=(num_hiddens, num_hiddens))
b2 = nd.zeros(num_hiddens)
W3 = nd.random.normal(scale=0.01, shape=(num_hiddens, num_outputs))
b3 = nd.zeros(num_outputs)
params = [W1, b1, W2, b2, W3, b3]
for param in params:
param.attach_grad()
# 定义激活函数
def relu(X):
return nd.maximum(X, 0)
# 定义神经网络模型(隐藏层层数)
def net(X):
X = X.reshape((-1, num_inputs))
H1 = relu(nd.dot(X, W1) + b1)
H2 = relu(nd.dot(H1, W2) + b2)
return nd.dot(H2, W3) + b3
# 定义损失函数
loss = gloss.SoftmaxCrossEntropyLoss()
# 训练模型
num_epochs, lr = 10, 0.5
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, params, lr)输出
hidden layer = 128
epoch 1, loss 1.2605, train acc 0.505, test acc 0.770
epoch 2, loss 0.5973, train acc 0.772, test acc 0.829
epoch 3, loss 0.4864, train acc 0.818, test acc 0.850
epoch 4, loss 0.4363, train acc 0.838, test acc 0.863
epoch 5, loss 0.4073, train acc 0.850, test acc 0.862
hidden layer = 256
epoch 1, loss 1.1123, train acc 0.569, test acc 0.787
epoch 2, loss 0.5368, train acc 0.797, test acc 0.843
epoch 3, loss 0.4575, train acc 0.831, test acc 0.839
epoch 4, loss 0.4215, train acc 0.842, test acc 0.866
epoch 5, loss 0.3838, train acc 0.856, test acc 0.866
hidden layer = 300
epoch 1, loss 1.2227, train acc 0.523, test acc 0.787
epoch 2, loss 0.5820, train acc 0.782, test acc 0.835
epoch 3, loss 0.4756, train acc 0.823, test acc 0.835
epoch 4, loss 0.4274, train acc 0.841, test acc 0.862
epoch 5, loss 0.4042, train acc 0.849, test acc 0.865
hidden layer = 128
epoch 1, loss 0.3863, train acc 0.856, test acc 0.866
epoch 2, loss 0.3637, train acc 0.866, test acc 0.866
epoch 3, loss 0.3468, train acc 0.872, test acc 0.869
epoch 4, loss 0.3374, train acc 0.873, test acc 0.871
epoch 5, loss 0.3221, train acc 0.881, test acc 0.874
epoch 6, loss 0.3156, train acc 0.882, test acc 0.877
epoch 7, loss 0.3073, train acc 0.886, test acc 0.879
epoch 8, loss 0.3004, train acc 0.887, test acc 0.885
epoch 9, loss 0.2892, train acc 0.892, test acc 0.883
epoch 10, loss 0.2827, train acc 0.894, test acc 0.880注:提高训练准确度方法增加隐藏层/隐藏单元数量 vs 增加训练次数
import d2lzh as d2l
from mxnet import gluon, init
from mxnet.gluon import loss as gloss, nn
# 定义模型
net = nn.Sequential()
net.add(nn.Dense(256, activation='relu'),
nn.Dense(10)) # 在这里可以添加隐藏层
net.initialize(init.Normal(sigma=0.01))
#读取数据并训练模型
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
loss = gloss.SoftmaxCrossEntropyLoss()
trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': 0.5})
num_epochs = 5
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, None,
None, trainer)标签:batch 叠加 att ret 提高 ini 回归 表示 for
原文地址:https://www.cnblogs.com/haricotvert/p/12267986.html