标签:use rtt mat mes 通过 基础 width 使用命令 mapred
sqoop是apache旗下,用于关系型数据库和hadoop之间传输数据的工具,sqoop可以用在离线分析中,将保存在mysql的业务数据传输到hive数仓,数仓分析完得到结果,再通过sqoop传输到mysql,最后通过web+echart来进行图表展示,更加直观的展示数据指标。
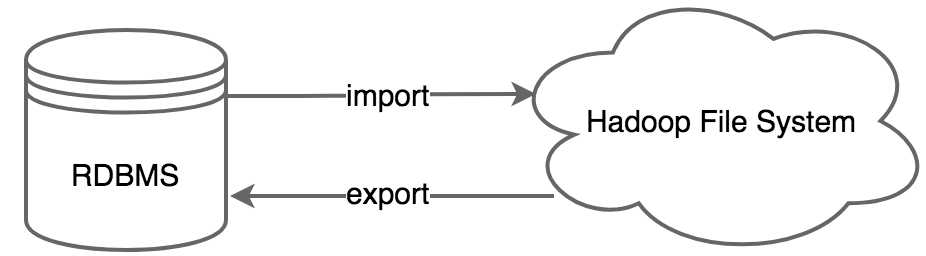
如下图所示,sqoop中有导入和导出的概念,参照物都是hadoop文件系统,其中关系型数据库可以是mysql、oracle和db2,hadoop文件系统中可以是hdfs、hive和hbase等。执行sqoop导入和导出,其本质都是转化成了mr任务去执行。
目前sqoop提供了两个版本,1.4.x的为sqoop1,1.99x的为sqoop2,前者因为安装简单,得到了大量使用,后者虽然引进了安全机制、web ui,rest api等更加方便使用的特性,但是安装过程繁琐暂时不记录。
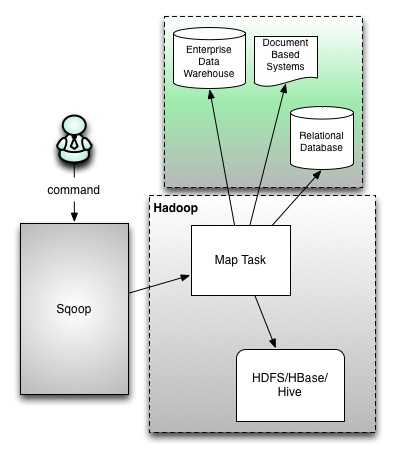
以下是sqoop1的结构图,它只提供一个sqoop客户端,使用命令行方式来执行导入/导出任务,最终任务都会被转化为mr,实现数据在hdfs/hbase/hive和rdbms/企业数据仓库之间的转换。
sqoop的安装相对简单,只需选择对应的sqoop解压到安装目录即可,一般将sqoop安装到已经安装了mysql和hive的节点上。这里mysql版本为5.7.28,hive版本为cdh的1.1.0。
(1)解压sqoop安装包,sqoop版本为1.4.6。
[root@node01 /kkb/soft]# tar -zxvf sqoop-1.4.6-cdh5.14.2.tar.gz -C /kkb/install/
(2)修改sqoop根目录/conf下的sqoop-env.sh文件,配置环境相关的参数。刚安装后需要复制模版文件,命名为sqoop-env.sh,因为此次sqoop安装后要实现关系型数据库跟hadoop、hive和hbase的数据传输,因此在里面配置hadoop、hive和hbase的安装路径。
# Set Hadoop-specific environment variables here. #Set path to where bin/hadoop is available export HADOOP_COMMON_HOME=/kkb/install/hadoop-2.6.0-cdh5.14.2 #Set path to where hadoop-*-core.jar is available export HADOOP_MAPRED_HOME=/kkb/install/hadoop-2.6.0-cdh5.14.2 #set the path to where bin/hbase is available export HBASE_HOME=/kkb/install/hbase-1.2.0-cdh5.14.2 #Set the path to where bin/hive is available export HIVE_HOME=/kkb/install/hive-1.1.0-cdh5.14.2
(3)复制数据库驱动包到sqoop的lib目录,如图拷贝mysql-connector-java-5.1.38.jar和java-json.jar。

(4)配置sqoop环境变量,也可以不配置,直接进入sqoop的bin目录下执行sqoop脚本也行。
接下来使用安装的sqoop,实现sqoop导入和导出,还可以创建sqoop job来完成作业,另外记录。
下面可以使用sqoop来获取数据库的信息。
# list-databases获取mysql中数据库,list-tables可以查看某个数据库下的表
[root@node01 /kkb/install/sqoop-1.4.6-cdh5.14.2/lib]# sqoop list-databases --connect jdbc:mysql://node01:3306 --username root --password 123456
(1)不指定导出目录和分隔符。
mysql中提前准备好数据,测试导入到hdfs。使用dbeaver工具,在mysql中创建数据库sqooptest,并建表Person,数据如下。
id|name |age|score|position| --|------|---|-----|--------| 1|messi | 32| 55|前锋 | 2|herry | 40| 30|前锋 | 3|clyang| 33| 3|中场 | 4|ronald| 35| 45|左前锋 |
使用如下命令,将Person表中的数据import到hdfs。
# import 导入
# --connect 指定mysql连接地址,数据库为sqooptest
# --username mysql用户名
# --password mysql密码
# --table 指定要导出的表Person
# --m 指定map task数,默认是4个
[hadoop@node01 ~]$ sqoop import --connect jdbc:mysql://node01:3306/sqooptest --username root --password 123456 --table Person --m 1
导出后提示保存了4条记录,即刚才mysql中的四条数据。

导出到hdfs后,默认保存位置为/user/hadoop/数据库表名,如下图所示。查看导出的内容,发现跟mysql中的一致,并且字段值之间使用逗号隔开。

(2)指定导出目录和分隔符,mysql中数据依然使用上面的,另外终端执行sqoop命令时可以使用反斜杠‘\‘转义字符来隔开各个参数,类似终端中使用scala的竖线‘|‘。
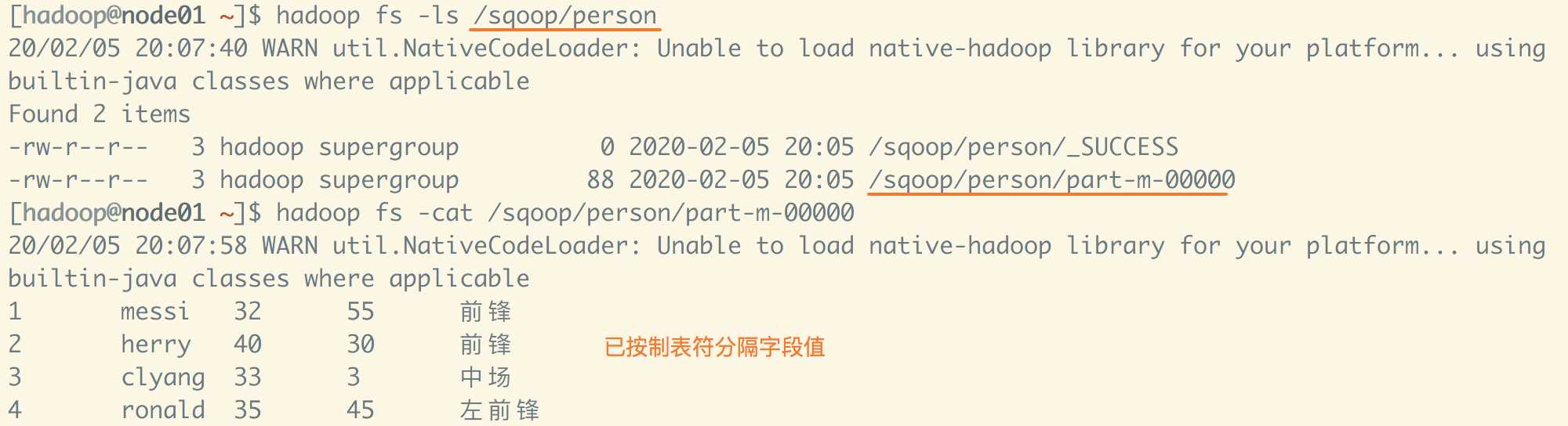
[hadoop@node01 ~]$ sqoop import > --connect jdbc:mysql://node01:3306/sqooptest \ > --username root > --password 123456 > --table Person > --target-dir /sqoop/person \ # 指定导出目录 > --delete-target-dir \ # 如果导出目录存在,就先删除 > --fields-terminated-by ‘\t‘ \ # 指定字段数据分隔符 > --m 1
导出后,进入指定目录查看,发现成功导出到指定目录,并用制表符分隔开。
(3)导入表的数据子集,可以通过指定where参数,将符合条件的子集导入到hdfs。
[hadoop@node01 ~]$ sqoop import > --connect jdbc:mysql://node01:3306/sqooptest \ > --username root --password 123456 > --table Person > --target-dir /sqoop/person_where > --delete-target-dir > --where "name = ‘messi‘" \ # where指定条件 > --m 1
查看hdfs上数据,结果ok,只导出了name=messi的数据。

(4)可以使用--query,指定sql查询条件过滤数据,再导入到hdfs。
[hadoop@node01 ~]$ sqoop import > --connect jdbc:mysql://node01:3306/sqooptest \ > --username root > --password 123456 > --target-dir /sqoop/person_sql > --delete-target-dir > --query ‘select * from Person where age>20 and $CONDITIONS‘ \ # 指定查询条件,并添加$CONDITIONS变量 > --m 2
执行后,发现报错,提示并行import时,需要指定split-by的字段。

重新指定split-by的字段为表的id字段,再次执行,ok。
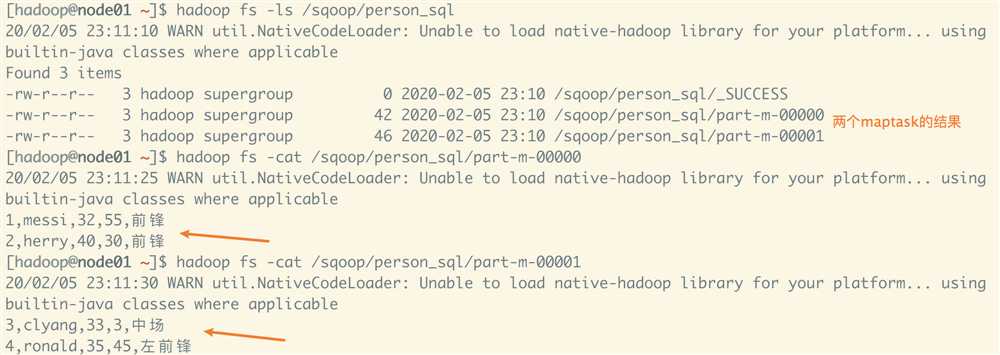
[hadoop@node01 ~]$ sqoop import > --connect jdbc:mysql://node01:3306/sqooptest \ > --username root > --password 123456 > --target-dir /sqoop/person_sql > --delete-target-dir > --query ‘select * from Person where age>20 and $CONDITIONS‘ \ > --split-by ‘id‘ > --m 2
查看hdfs,产生两个maptask文件,可以看出是根据id分组后并行执行的结果。
(5)增量导入,有时候不需要导入表中的全部数据,只需要导入部分数据就可以。如增加行,就导入(append模式),或者某行时间戳有变化,就导入(lastmodified模式)。
append模式:
sqoop命令。
[hadoop@node01 ~]$ sqoop import > --connect jdbc:mysql://node01:3306/sqooptest \ > --username root > --password 123456 > --table Person > --incremental append \ # append模式 > --check-column id \ # 检查列为id列 > --last-value 4 \ # id列上一个记录的值为4 > --target-dir /sqoop/increment > --m 1
mysql中添加一行数据,id为5,添加后执行上面的命令。
id|name |age|score|position| --|------|---|-----|--------| 1|messi | 32| 55|前锋 | 2|herry | 40| 30|前锋 | 3|clyang| 33| 3|中场 | 4|ronald| 35| 45|左前锋 | 5|kaka | 45| 2|右前锋 |
执行没有报错,查看hdfs中内容,发现只导入了新增id为5的这行数据。

lastmodified模式:
这个模式是基于时间列的增量数据导入,mysql中新准备一张包含时间列的表和数据,如下所示。
id|name |salary|time | --|------|------|-------------------| 1 |clyang| 12000|2020-01-25 10:00:00| 2 |messi | 23000|2020-01-25 10:30:00| 3 |ronald| 22000|2020-01-25 10:45:00| 4 |herry | 21000|2020-01-25 11:15:00|
sqoop导入命令,使用lastmodified模式来导入新增数据。
[hadoop@node01 ~]$ sqoop import > --connect jdbc:mysql://node01:3306/sqooptest \ > --username root > --password 123456 > --table Man > --incremental lastmodified \ # lasmodified模式 > --check column time \ # 检查列为时间列 > --last-value ‘2020-01-25 10:00:00‘ \ # 指定上一个时间点 > --target-dir /sqoop/increment1 > --m 1
执行完成后,时间点在10点以后的数据,都导入到了hdfs。

现在对表的数据进行修改,新增并修改数据,测试能否导入。
# 修改id=4的salary为8888,并新增一列id=5
id|name |salary|time | --|------|------|-------------------| 1 |clyang| 12000|2020-01-25 10:00:00| 2 |messi | 23000|2020-01-25 10:30:00| 3 |ronald| 22000|2020-01-25 10:45:00| 4 |herry | 8888|2020-01-25 11:15:00| 5 |kaka | 6666|2020-01-25 11:45:00|
sqoop命令,修改时间执行。
[hadoop@node01 ~]$ sqoop import > --connect jdbc:mysql://node01:3306/sqooptest \ > --username root > --password 123456 > --table Man > --incremental lastmodified \ # lasmodified模式 > --check column time \ # 检查列为时间列 > --last-value ‘2020-01-25 10:30:00‘ \ # 指定上一个时间点 > --target-dir /sqoop/increment1 > --m 1
执行后报错,提示需要添加--append或-merge-key,因为导出目录已经存在了。
20/02/06 11:16:34 ERROR tool.ImportTool: Import failed: --merge-key or --append is required when using --incremental lastmodified and the output directory exists.
命名添加--append后执行没有报错,查看目录下内容。
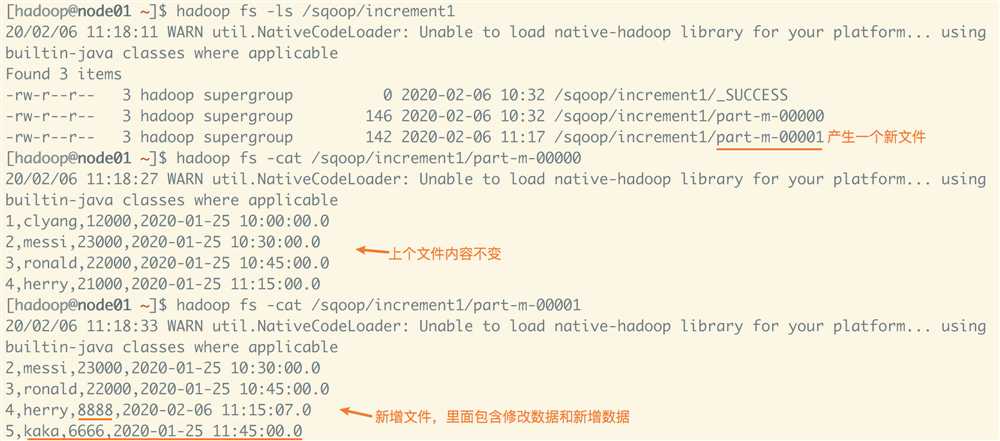
继续修改数据测试。
# 修改id为5的数据,并添加id为6的数据
id|name |salary|time | --|-------|------|-------------------| 1 |clyang | 12000|2020-01-25 10:00:00| 2 |messi | 23000|2020-01-25 10:30:00| 3 |ronald | 22000|2020-01-25 10:45:00| 4 |herry | 8888|2020-01-25 11:15:00| 5 |kaka | 9999|2020-01-25 11:50:00| 6 |beckham| 23000|2020-01-25 12:00:00|
测试--merge-key的使用,sqoop命令行最后添加--merge-key id后执行没有报错。
[hadoop@node01 ~]$ sqoop import > --connect jdbc:mysql://node01:3306/sqooptest \ > --username root > --password 123456 > --table Man > --incremental lastmodified \ # lasmodified模式 > --check column time \ # 检查列为时间列 > --last-value ‘2020-01-25 10:30:00‘ \ # 指定上一个时间点 > --target-dir /sqoop/increment1 > --m 1 > --merge-key id
目录下内容发现只有一个文件,并且sqoop里导出的时间在10:30以后,但依然有10点的数据在里面,说明经历了reduce阶段进行合并。

导出数据到hive前,需要将hive中的一个包(hive-exec-1.1.0-cdh5.14.2.jar)拷贝到sqoop的lib目录。
[hadoop@node01 /kkb/install/hive-1.1.0-cdh5.14.2/lib]$ cp hive-exec-1.1.0-cdh5.14.2.jar /kkb/install/sqoop-1.4.6-cdh5.14.2/lib/
(1)手动创建hive表后导入
先手动在hive中建一个接收数据的表,这里指定的分隔符和sqoop导出时的分隔符要一致。
# 创建数据库 hive (default)> create database sqooptohive; OK Time taken: 0.185 seconds hive (default)> use sqooptohive; OK Time taken: 0.044 seconds # 创建表 hive (sqooptohive)> create external table person(id int,name string,age int,score int,position string)row format delimited fields terminated by ‘\t‘; OK Time taken: 0.263 seconds hive (sqooptohive)> show tables; OK tab_name person
sqoop导出数据到hive表中。
[hadoop@node01 ~]$ sqoop import > --connect jdbc:mysql://node01:3306/sqooptest \ > --username root > --password 123456 > --table Person > --fields-terminated-by ‘\t‘ \ # 这里需要和hive中分隔指定的一样 > --delete-target-dir > --hive-import \ # 导入hive > --hive-table sqooptohive.person \ #hive表 > --hive-overwrite \ # 覆盖hive表中已有数据 > --m 1
查看hive表数据,发现导入ok。

(2)导入时自动创建hive表
也可以不需要提前创建hive表,会自动创建。
[hadoop@node01 ~]$ sqoop import > --connect jdbc:mysql://node01:3306/sqooptest \ > --username root > --password 123456 > --table Person > --hive-import > --hive-database sqooptohive > --hive-table person1 > --m 1
导入后,发现数据库下多了一个表person1,查看数据ok。

也可以将数据导入到hbase,依然使用sqooptest.Person表,导入前集群需启动zookeeper和hbase。
sqoop命令
[hadoop@node01 ~]$ sqoop import > --connect jdbc:mysql://node01:3306/sqooptest \ > --username root > --password 123456 > --table Person > --hbase-table mysqltohbase \ # 指定hbase表名 > --hbase-create-table \ # hbase没有表就创建表 > --column-family f1 \ # 指定列族 > --hbase-row-key id \ # 执行rowkey --m 1
执行完成后,hbase中查看发现新建了一张表,并且成功导入数据。

sqoop导出数据,这里记录从hdfs导出数据,如果是hive导出,也是直接读取hdfs保存目录中的文件进行导出,比较类似。
hdfs中先准备数据
[hadoop@node01 ~]$ hadoop fs -cat /hdfstomysql.txt 20/02/06 14:31:17 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 1 messi 32 50 2 ronald 35 55 3 herry 40 51
mysql中需要先建表,否则会报错。
CREATE TABLE sqooptest.hdfstomysql ( id INT NOT NULL, name varchar(100) NOT NULL, age INT NOT NULL, score INT NOT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_general_ci;
sqoop命令执行导出。
[hadoop@node01 ~]$ sqoop import > --connect jdbc:mysql://node01:3306/sqooptest \ > --username root > --password 123456 > --table hdfstomysql \ # 提前建立好的表 > --export-dir /hdfstomysql.txt \ # hdfs中目录文件 > --input-fields-terminated-by " " # 指定文件数据的分隔符
导出后,发现mysql数据表中有了数据,ok。

以上,就是sqoop的使用入门,记录一下以后使用。
参考博文:
(1)https://blogs.apache.org/sqoop/entry/apache_sqoop_highlights_of_sqoop#comment-1561314193000
(2)https://www.cnblogs.com/youngchaolin/p/12179320.html
标签:use rtt mat mes 通过 基础 width 使用命令 mapred
原文地址:https://www.cnblogs.com/youngchaolin/p/12253859.html