标签:mamicode ide mapping normal load inf 模型训练 单元 网络层
由于验证数据集不参与模型训练,当训练数据不够用时,预留大量的验证数据显得太奢侈。一种改善的方法是\(K\)折交叉验证(\(K\)-fold cross-validation)。在\(K\)折交叉验证中,我们把原始训练数据集分割成\(K\)个不重合的子数据集,然后我们做\(K\)次模型训练和验证。每一次,我们使用一个子数据集验证模型,并使用其他\(K-1\)个子数据集来训练模型。在这\(K\)次训练和验证中,每次用来验证模型的子数据集都不同。最后,我们对这\(K\)次训练误差和验证误差分别求平均。
高阶多项式函数模型参数更多,模型函数的选择空间更大,所以高阶多项式函数比低阶多项式函数的复杂度更高。因此,高阶多项式函数比低阶多项式函数更容易在相同的训练数据集上得到更低的训练误差。给定训练数据集,模型复杂度和误差之间的关系通常如图3.4所示。给定训练数据集,如果模型的复杂度过低,很容易出现欠拟合;如果模型复杂度过高,很容易出现过拟合。应对欠拟合和过拟合的一个办法是针对数据集选择合适复杂度的模型。
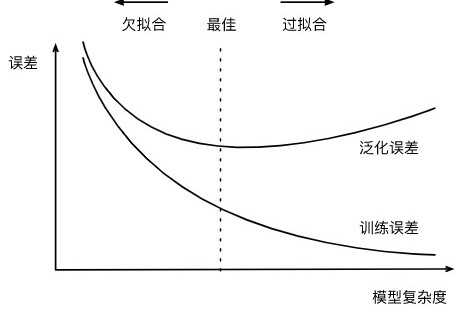
一般来说,如果训练数据集中样本数过少,特别是比模型参数数量(按元素计)更少时,过拟合更容易发生。此外,泛化误差不会随训练数据集里样本数量增加而增大。因此,在计算资源允许的范围之内,我们通常希望训练数据集大一些,特别是在模型复杂度较高时,例如层数较多的深度学习模型。
权重衰减是应对过拟合问题的常用方法
丢弃法也可以来应对过拟合问题,下面介绍的丢弃法特指倒置丢弃法
丢弃法是指在训练时,对于每一隐藏层有一定的概率丢弃该隐藏层中的隐藏单元。
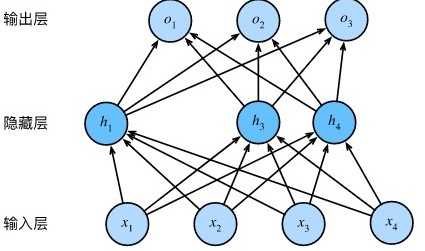
mlp中描述了一个单隐藏层的多层感知机。其中输入个数为4,隐藏单元个数为5,且隐藏单元\(h_i\)(\(i=1, \ldots, 5\))的计算表达式为
\[h_i = \phi\left(x_1 w_{1i} + x_2 w_{2i} + x_3 w_{3i} + x_4 w_{4i} + b_i\right),\]
这里\(\phi\)是激活函数,\(x_1, \ldots, x_4\)是输入,隐藏单元\(i\)的权重参数为\(w_{1i}, \ldots, w_{4i}\),偏差参数为\(b_i\)。当对该隐藏层使用丢弃法时,该层的隐藏单元将有一定概率被丢弃掉。设丢弃概率为\(p\),
那么有\(p\)的概率\(h_i\)会被清零,有\(1-p\)的概率\(h_i\)会除以\(1-p\)做拉伸。丢弃概率是丢弃法的超参数。具体来说,设随机变量\(\xi_i\)为0和1的概率分别为\(p\)和\(1-p\)。使用丢弃法时我们计算新的隐藏单元\(h_i'\)
\[h_i' = \frac{\xi_i}{1-p} h_i.\]
由于\(E(\xi_i) = 1-p\),因此
\[E(h_i') = \frac{E(\xi_i)}{1-p}h_i = h_i.\]
即丢弃法不改变其输入的期望值。让我们对图3.3中的隐藏层使用丢弃法,一种可能的结果如图3.5所示,其中\(h_2\)和\(h_5\)被清零。这时输出值的计算不再依赖\(h_2\)和\(h_5\),在反向传播时,与这两个隐藏单元相关的权重的梯度均为0。由于在训练中隐藏层神经元的丢弃是随机的,即\(h_1, \ldots, h_5\)都有可能被清零,输出层的计算无法过度依赖\(h_1, \ldots, h_5\)中的任一个,从而在训练模型时起到正则化的作用,并可以用来应对过拟合。在测试模型时,我们为了拿到更加确定性的结果,一般不使用丢弃法。
import d2lzh as d2l
from mxnet import autograd, gluon, init, nd
from mxnet.gluon import loss as gloss, nn
def dropout(X, drop_prob):
assert 0 <= drop_prob <= 1
keep_prob = 1 - drop_prob
# 这种情况下把全部元素都丢弃
if keep_prob == 0:
return X.zeros_like()
mask = nd.random.uniform(0, 1, X.shape) < keep_prob
return mask * X / keep_prob
# 定义模型参数
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
W1 = nd.random.normal(scale=0.01, shape=(num_inputs, num_hiddens1))
b1 = nd.zeros(num_hiddens1)
W2 = nd.random.normal(scale=0.01, shape=(num_hiddens1, num_hiddens2))
b2 = nd.zeros(num_hiddens2)
W3 = nd.random.normal(scale=0.01, shape=(num_hiddens2, num_outputs))
b3 = nd.zeros(num_outputs)
params = [W1, b1, W2, b2, W3, b3]
for param in params:
param.attach_grad()
# 定义模型
drop_prob1, drop_prob2 = 0.2, 0.5
def net(X):
X = X.reshape((-1, num_inputs))
H1 = (nd.dot(X, W1) + b1).relu()
if autograd.is_training(): # 只在训练模型时使用丢弃法
H1 = dropout(H1, drop_prob1) # 在第一层全连接后添加丢弃层
H2 = (nd.dot(H1, W2) + b2).relu()
if autograd.is_training():
H2 = dropout(H2, drop_prob2) # 在第二层全连接后添加丢弃层
return nd.dot(H2, W3) + b3
# 训练和测试模型
num_epochs, lr, batch_size = 5, 0.5, 256
loss = gloss.SoftmaxCrossEntropyLoss()
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size,
params, lr)输出
epoch 1, loss 1.1702, train acc 0.550, test acc 0.747
epoch 2, loss 0.5923, train acc 0.780, test acc 0.833
epoch 3, loss 0.4924, train acc 0.820, test acc 0.850
epoch 4, loss 0.4471, train acc 0.837, test acc 0.861
epoch 5, loss 0.4227, train acc 0.844, test acc 0.858# 参数设置
drop_prob1, drop_prob2 = 0.2, 0.5
num_epochs, lr, batch_size = 5, 0.5, 256
# 设置模型
net = nn.Sequential()
net.add(nn.Dense(256, activation="relu"),
nn.Dropout(drop_prob1), # 在第一个全连接层后添加丢弃层
nn.Dense(256, activation="relu"),
nn.Dropout(drop_prob2), # 在第二个全连接层后添加丢弃层
nn.Dense(10))
net.initialize(init.Normal(sigma=0.01))
# 训练和测试模型
trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': lr})
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, None,
None, trainer)输出
epoch 1, loss 1.2295, train acc 0.531, test acc 0.797
epoch 2, loss 0.6045, train acc 0.778, test acc 0.823
epoch 3, loss 0.4945, train acc 0.820, test acc 0.849
epoch 4, loss 0.4510, train acc 0.834, test acc 0.856
epoch 5, loss 0.4199, train acc 0.847, test acc 0.864注:在每轮epoch中,都有很多组batch,这些组训练时使用的是同一组参数,但是神经网络的结构是不同的。最后得到的参数是所有训练结果的平均,所以基本上每个隐藏单元的参数仍不会为0。
正向传播是指对神经网络沿着从输入层到输出层的顺序,依次计算并存储模型的中间变量(包括输出)。
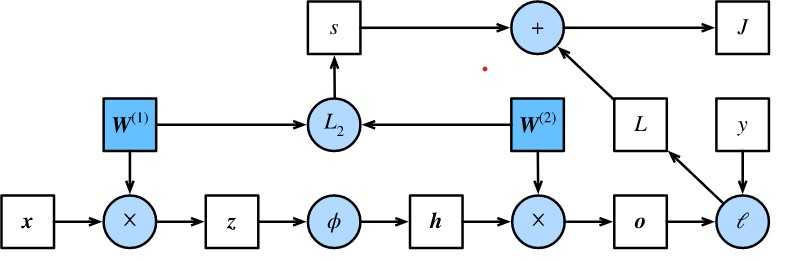
反向传播指的是计算神经网络参数梯度的方法。总的来说,反向传播依据微积分中的链式法则,沿着从输出层到输入层的顺序,依次计算并存储目标函数有关神经网络各层的中间变量以及参数的梯度。对输入或输出\(\mathsf{X}, \mathsf{Y}, \mathsf{Z}\)为任意形状张量的函数\(\mathsf{Y}=f(\mathsf{X})\)和\(\mathsf{Z}=g(\mathsf{Y})\),通过链式法则,我们有
\[\frac{\partial \mathsf{Z}}{\partial \mathsf{X}} = \text{prod}\left(\frac{\partial \mathsf{Z}}{\partial \mathsf{Y}}, \frac{\partial \mathsf{Y}}{\partial \mathsf{X}}\right),\]
其中\(\text{prod}\)运算符将根据两个输入的形状,在必要的操作(如转置和互换输入位置)后对两个输入做乘法。
回顾一下本节中样例模型,它的参数是\(\boldsymbol{W}^{(1)}\)和\(\boldsymbol{W}^{(2)}\),因此反向传播的目标是计算\(\partial J/\partial \boldsymbol{W}^{(1)}\)和\(\partial J/\partial \boldsymbol{W}^{(2)}\)。我们将应用链式法则依次计算各中间变量和参数的梯度,其计算次序与前向传播中相应中间变量的计算次序恰恰相反。首先,分别计算目标函数\(J=L+s\)有关损失项\(L\)和正则项\(s\)的梯度
\[\frac{\partial J}{\partial L} = 1, \quad \frac{\partial J}{\partial s} = 1.\]
其次,依据链式法则计算目标函数有关输出层变量的梯度\(\partial J/\partial \boldsymbol{o} \in \mathbb{R}^q\):
\[ \frac{\partial J}{\partial \boldsymbol{o}} = \text{prod}\left(\frac{\partial J}{\partial L}, \frac{\partial L}{\partial \boldsymbol{o}}\right) = \frac{\partial L}{\partial \boldsymbol{o}}. \]
接下来,计算正则项有关两个参数的梯度:
\[\frac{\partial s}{\partial \boldsymbol{W}^{(1)}} = \lambda \boldsymbol{W}^{(1)},\quad\frac{\partial s}{\partial \boldsymbol{W}^{(2)}} = \lambda \boldsymbol{W}^{(2)}.\]
现在,我们可以计算最靠近输出层的模型参数的梯度\(\partial J/\partial \boldsymbol{W}^{(2)} \in \mathbb{R}^{q \times h}\)。依据链式法则,得到
\[ \frac{\partial J}{\partial \boldsymbol{W}^{(2)}} = \text{prod}\left(\frac{\partial J}{\partial \boldsymbol{o}}, \frac{\partial \boldsymbol{o}}{\partial \boldsymbol{W}^{(2)}}\right) + \text{prod}\left(\frac{\partial J}{\partial s}, \frac{\partial s}{\partial \boldsymbol{W}^{(2)}}\right) = \frac{\partial J}{\partial \boldsymbol{o}} \boldsymbol{h}^\top + \lambda \boldsymbol{W}^{(2)}. \]
沿着输出层向隐藏层继续反向传播,隐藏层变量的梯度\(\partial J/\partial \boldsymbol{h} \in \mathbb{R}^h\)可以这样计算:
\[ \frac{\partial J}{\partial \boldsymbol{h}} = \text{prod}\left(\frac{\partial J}{\partial \boldsymbol{o}}, \frac{\partial \boldsymbol{o}}{\partial \boldsymbol{h}}\right) = {\boldsymbol{W}^{(2)}}^\top \frac{\partial J}{\partial \boldsymbol{o}}. \]
由于激活函数\(\phi\)是按元素运算的,中间变量\(\boldsymbol{z}\)的梯度\(\partial J/\partial \boldsymbol{z} \in \mathbb{R}^h\)的计算需要使用按元素乘法符\(\odot\):
\[ \frac{\partial J}{\partial \boldsymbol{z}} = \text{prod}\left(\frac{\partial J}{\partial \boldsymbol{h}}, \frac{\partial \boldsymbol{h}}{\partial \boldsymbol{z}}\right) = \frac{\partial J}{\partial \boldsymbol{h}} \odot \phi'\left(\boldsymbol{z}\right). \]
最终,我们可以得到最靠近输入层的模型参数的梯度\(\partial J/\partial \boldsymbol{W}^{(1)} \in \mathbb{R}^{h \times d}\)。依据链式法则,得到
\[ \frac{\partial J}{\partial \boldsymbol{W}^{(1)}} = \text{prod}\left(\frac{\partial J}{\partial \boldsymbol{z}}, \frac{\partial \boldsymbol{z}}{\partial \boldsymbol{W}^{(1)}}\right) + \text{prod}\left(\frac{\partial J}{\partial s}, \frac{\partial s}{\partial \boldsymbol{W}^{(1)}}\right) = \frac{\partial J}{\partial \boldsymbol{z}} \boldsymbol{x}^\top + \lambda \boldsymbol{W}^{(1)}. \]
在训练深度学习模型时,正向传播和反向传播之间相互依赖。下面我们仍然以本节中的样例模型分别阐述它们之间的依赖关系。
一方面,正向传播的计算可能依赖于模型参数的当前值,而这些模型参数是在反向传播的梯度计算后通过优化算法迭代的。例如,计算正则化项\(s = (\lambda/2) \left(\|\boldsymbol{W}^{(1)}\|_F^2 + \|\boldsymbol{W}^{(2)}\|_F^2\right)\)依赖模型参数\(\boldsymbol{W}^{(1)}\)和\(\boldsymbol{W}^{(2)}\)的当前值,而这些当前值是优化算法最近一次根据反向传播算出梯度后迭代得到的。
另一方面,反向传播的梯度计算可能依赖于各变量的当前值,而这些变量的当前值是通过正向传播计算得到的。举例来说,参数梯度\(\partial J/\partial \boldsymbol{W}^{(2)} = (\partial J / \partial \boldsymbol{o}) \boldsymbol{h}^\top + \lambda \boldsymbol{W}^{(2)}\)的计算需要依赖隐藏层变量的当前值\(\boldsymbol{h}\)。这个当前值是通过从输入层到输出层的正向传播计算并存储得到的。
因此,在模型参数初始化完成后,我们交替地进行正向传播和反向传播,并根据反向传播计算的梯度迭代模型参数。既然我们在反向传播中使用了正向传播中计算得到的中间变量来避免重复计算,那么这个复用也导致正向传播结束后不能立即释放中间变量内存。这也是训练要比预测占用更多内存的一个重要原因。另外需要指出的是,这些中间变量的个数大体上与网络层数线性相关,每个变量的大小跟批量大小和输入个数也是线性相关的,它们是导致较深的神经网络使用较大批量训练时更容易超内存的主要原因。
当神经网络的层数较多时,模型的数值稳定性容易变差。假设一个层数为\(L\)的多层感知机的第\(l\)层\(\boldsymbol{H}^{(l)}\)的权重参数为\(\boldsymbol{W}^{(l)}\),输出层\(\boldsymbol{H}^{(L)}\)的权重参数为\(\boldsymbol{W}^{(L)}\)。为了便于讨论,不考虑偏差参数,且设所有隐藏层的激活函数为恒等映射(identity mapping)\(\phi(x) = x\)。给定输入\(\boldsymbol{X}\),多层感知机的第\(l\)层的输出\(\boldsymbol{H}^{(l)} = \boldsymbol{X} \boldsymbol{W}^{(1)} \boldsymbol{W}^{(2)} \ldots \boldsymbol{W}^{(l)}\)。此时,如果层数\(l\)较大,\(\boldsymbol{H}^{(l)}\)的计算可能会出现衰减或爆炸。举个例子,假设输入和所有层的权重参数都是标量,如权重参数为0.2和5,多层感知机的第30层输出为输入\(\boldsymbol{X}\)分别与\(0.2^{30} \approx 1 \times 10^{-21}\)(衰减)和\(5^{30} \approx 9 \times 10^{20}\)(爆炸)的乘积。类似地,当层数较多时,梯度的计算也更容易出现衰减或爆炸。
如果将每个隐藏单元的参数都初始化为相同的值,在某些情况下,隐藏层本质上可能只有1个隐藏单元在发挥作用,所以需要将神经网络的模型参数,特别是权重参数进行随机初始化。
MXNet默认的随机初始化方法:权重参数每个元素随机采样于-0.07到0.07之间的均匀分布,偏差参数全部清零。
Xavier随机初始化假设某全连接层的输入个数为\(a\),输出个数为\(b\),Xavier随机初始化将使该层中权重参数的每个元素都随机采样于均匀分布
\[U\left(-\sqrt{\frac{6}{a+b}}, \sqrt{\frac{6}{a+b}}\right).\]
它的设计主要考虑到,模型参数初始化后,每层输出的方差不该受该层输入个数影响,且每层梯度的方差也不该受该层输出个数影响。
标签:mamicode ide mapping normal load inf 模型训练 单元 网络层
原文地址:https://www.cnblogs.com/haricotvert/p/12271094.html