标签:分发 apach 责任 apache 核数 指定 info png 了解
官方文档:https://hadoop.apache.org/docs/stable/,目前官方已经是3.x,但yarn机制没有太大变化
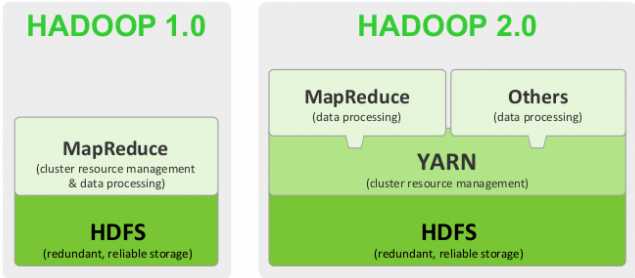
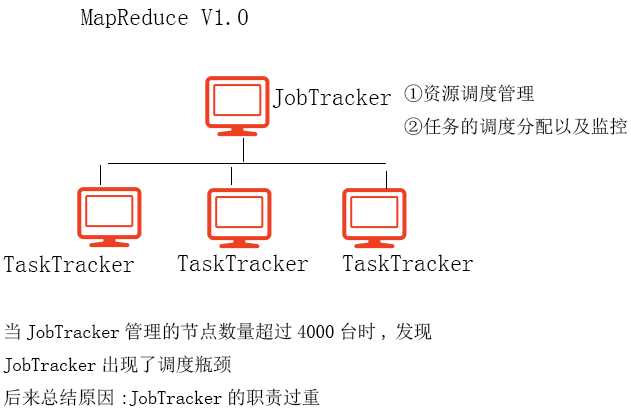
在Hadoop1.0中,没有yarn,所有的任务调度和资源管理都是MapReduce自己来做,所以在Hadoop1.0中,最核心的节点是JobTracker。在整个MapReduce集群中,JobTracker的性能基本决定了整个集群的性能。经过试验,发现在Hadoop1.0中,JobTracker所能管理的节点数量最多不要超过4000,一旦超过4000个节点,则整个集群的性能会成倍下降。
在Hadoop2.0中,为了解决性能下降的问题,引入了yarn来进行管理,从Hadoop2.0开始,MapReduce变成了一个纯粹的计算框架,不再负责管理
Yarn组件包括:
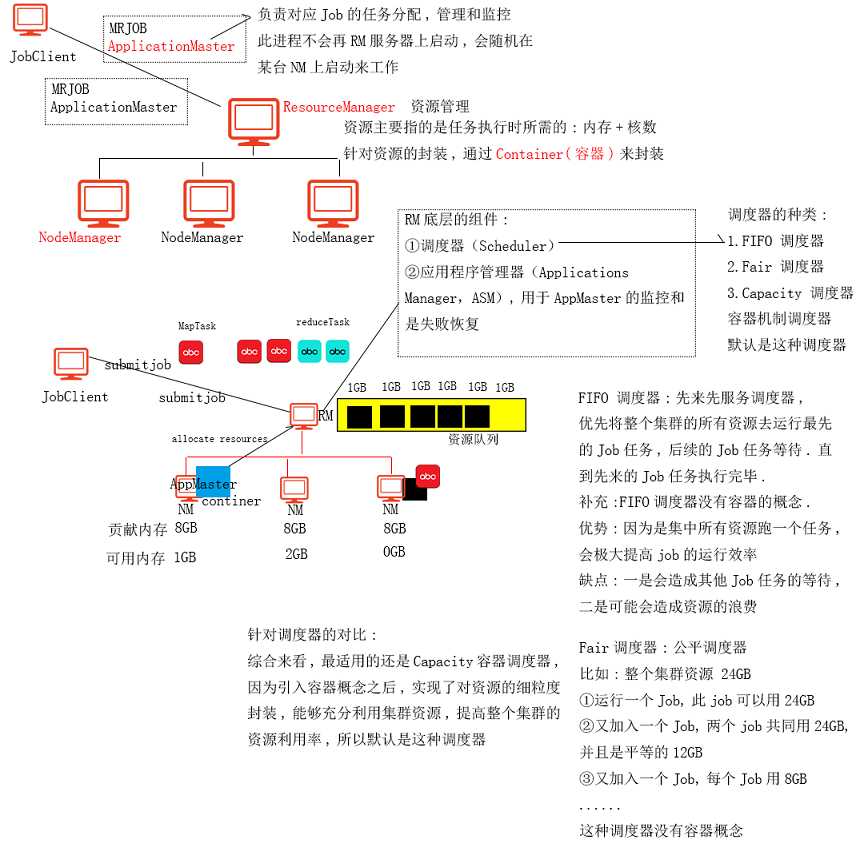
1)ResourceManager-资源管理:负责资源的监控和分配
①ApplicationsManager:负责为任务分配资源
②Schedular:负责将任务以及资源发给ApplicationMaster
2)ApplicationMaster:负责任务调度和监控,并不是一个主进程,在启动Yarn的时候,不会单独占用一个节点
3)NodeManager:任务执行:功能和原来的TaskTracker一致
执行流程:
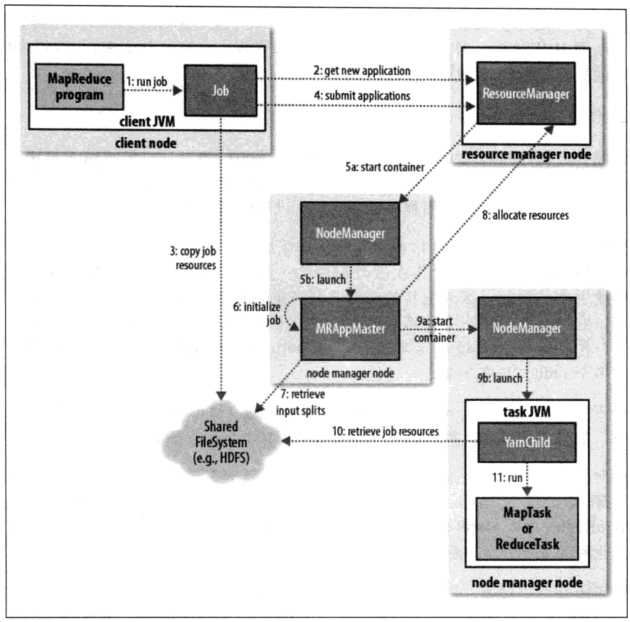
① JobClient执行run job阶段,检测各种job运行环境参数
② 向ResourceManager申请job id
③ 将Job的运算资源,上传到HDFS
④ submit job
⑤
a:start container,启动容器,这一步的容器的资源封装,限定的是AppMaster进程
b:根据容器的资源描述情况,启动AppMaster进程(用于负责对应Job的任务分配和监控)
⑥~⑦:初始化job,统计出当前job的MapTask数量和ReduceTask数量
⑧:AppMaster向RM申请资源,RM收到请求后,会为对应的Job创建一个资源队列
⑨
a:在具体的NM上启动容器
b:根据容器启动对应的工作进程
⑩ 获取job的运算资源
? 在进程中运行MapTask或ReduceTask

①将Job任务提交到RM
②在RM中,子组件ResourceManager会为提交的job任务分配执行所需要的资源,资源主要包含这个任务执行所需要的内存、cpu核数,将分配的资源封装到一个Container对象中。如果不指定,则默认每一个任务分配1G内存及1核CPU
③ApplicationsManager将Container及Job任务交给Schedular,然后Schedular负责将Container和Job交给ApplicationMaster
④ApplicationMaster接收到任务后,将Job拆分成多个MapTask以及ReduceTask,将MapTask以及Reduce Task分发到NodeManager上执行。
⑤NodeManager会启动JVM子进程执行对应的任务,会为每一个MapTask或ReduceTask都启动一个JVM子进程
⑥NodeManager会向ApplicationMaster汇报任务的执行情况,并且向ApplicationsManager汇报资源使用情况
⑦如果执行成功,则NodeManager向ApplicationMaster返回任务成功的信号,并且向ApplicationsManager发送信号回收资源
⑧如果执行失败,则NodeManager向ApplicationMaster返回任务失败的信号,并且依然会向ApplicationManager发送信号回收资源;ApplicationMaster收到失败信号,会重新给这个任务来申请资源,然后试图重新分配这个任务
标签:分发 apach 责任 apache 核数 指定 info png 了解
原文地址:https://www.cnblogs.com/rmxd/p/12273247.html