标签:top enc cond requests join base star gecko ret
python采集某市政百姓信件内容
#coding:utf-8 import requests from lxml import etree import time import pymysql import datetime import urllib import json from IPython.core.page import page conn = pymysql.connect( host="localhost", user="root", port=3306, password="123456", database="bjxj") gg=2950 def db(conn, reqcontent,reqname,reqtime,resname,restime,rescontent,reqtype,isreply): cursor = conn.cursor() # cursor.execute( # "INSERT INTO xinjian(name) VALUES (%s)", # [name]) if isreply == False : isreply = 0 restime1 = ‘‘ else : isreply = 1 restime1 = restime[0] print(reqcontent) print(reqname) print(reqtime) print(resname) #print(restime) print(rescontent) print(reqtype) print(isreply) cursor.execute("INSERT INTO aaa (reqcontent,reqname,reqtime,resname,rescontent,reqtype,isreply,restime) VALUES (%s,%s,%s,%s,%s,%s,%s,%s);", [reqcontent,reqname,reqtime,resname,rescontent,reqtype,isreply,restime1]) conn.commit() cursor.close() def dbservice(conn,username,sp,image,pr): cursor = conn.cursor() #https://search.jd.com/Search?keyword=%E5%8C%96%E5%A6%86&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E5%8C%96%E5%A6%86&stock=1&page=3&s=59&click=0 #https://search.jd.com/Search?keyword=%E5%8C%96%E5%A6%86&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E5%8C%96%E5%A6%86&stock=1&page=5&s=113&click=0 global gg created=datetime.datetime.now().strftime(‘%Y-%m-%d %H:%M:%S‘) created2=datetime.datetime.now().strftime(‘%Y-%m-%d %H:%M:%S‘) num=512 cid=319 image1="http:"+image image="http://localhost:8089/pic/phone/"+str(gg)+".jpg" print(image1) urllib.request.urlretrieve(image1,‘e:/JDpic/‘+str(gg)+‘.jpg‘) print(username) cursor.execute("INSERT INTO tb_item(title,id,sell_point,price,num,image,cid,created,updated) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s);", [username,gg,sp,pr,num,image,cid,created,created2]) conn.commit() cursor.close() gg=gg+1 def crow_first(n): url=‘https://search.jd.com/Search?keyword=%E5%8C%96%E5%A6%86&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&stock=1&page=‘+str(n)+‘&s=‘+str(1+(n-1)*30)+‘&click=0&scrolling=y‘ print(url) head = {‘authority‘: ‘search.jd.com‘, ‘method‘: ‘GET‘, ‘path‘: ‘/s_new.php?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E6%89%8B%E6%9C%BA&cid2=653&cid3=655&page=4&s=84&scrolling=y&log_id=1529828108.22071&tpl=3_M&show_items=7651927,7367120,7056868,7419252,6001239,5934182,4554969,3893501,7421462,6577495,26480543553,7345757,4483120,6176077,6932795,7336429,5963066,5283387,25722468892,7425622,4768461‘, ‘scheme‘: ‘https‘, ‘referer‘: ‘https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E6%89%8B%E6%9C%BA&cid2=653&cid3=655&page=3&s=58&click=0‘, ‘user-agent‘: ‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36‘, ‘x-requested-with‘: ‘XMLHttpRequest‘, ‘Cookie‘:‘qrsc=3; pinId=RAGa4xMoVrs; xtest=1210.cf6b6759; ipLocation=%u5E7F%u4E1C; _jrda=5; TrackID=1aUdbc9HHS2MdEzabuYEyED1iDJaLWwBAfGBfyIHJZCLWKfWaB_KHKIMX9Vj9_2wUakxuSLAO9AFtB2U0SsAD-mXIh5rIfuDiSHSNhZcsJvg; shshshfpa=17943c91-d534-104f-a035-6e1719740bb6-1525571955; shshshfpb=2f200f7c5265e4af999b95b20d90e6618559f7251020a80ea1aee61500; cn=0; 3AB9D23F7A4B3C9B=QFOFIDQSIC7TZDQ7U4RPNYNFQN7S26SFCQQGTC3YU5UZQJZUBNPEXMX7O3R7SIRBTTJ72AXC4S3IJ46ESBLTNHD37U; ipLoc-djd=19-1607-3638-3638.608841570; __jdu=930036140; user-key=31a7628c-a9b2-44b0-8147-f10a9e597d6f; areaId=19; __jdv=122270672|direct|-|none|-|1529893590075; PCSYCityID=25; mt_xid=V2_52007VwsQU1xaVVoaSClUA2YLEAdbWk5YSk9MQAA0BBZOVQ0ADwNLGlUAZwQXVQpaAlkvShhcDHsCFU5eXENaGkIZWg5nAyJQbVhiWR9BGlUNZwoWYl1dVF0%3D; __jdc=122270672; shshshfp=72ec41b59960ea9a26956307465948f6; rkv=V0700; __jda=122270672.930036140.-.1529979524.1529984840.85; __jdb=122270672.1.930036140|85.1529984840; shshshsID=f797fbad20f4e576e9c30d1c381ecbb1_1_1529984840145‘ } r = requests.get(url, headers=head) r.encoding=‘utf-8‘ html = r.content html1 = etree.HTML(html) #print(html1) datas=html1.xpath(‘//li[contains(@class,"gl-item")]‘) s2=0 for data in datas: s2=s2+1; p_price = data.xpath(‘div/div[@class="p-price"]/strong/i/text()‘) p_comment = data.xpath(‘div/div[@class="p-commit"]/strong/a/text()‘) p_name = data.xpath(‘div/div[@class="p-name p-name-type-2"]/a/em/text()‘) p_sell_point = data.xpath(‘div/div[@class="p-name p-name-type-2"]/a/i/text()‘) p_image= data.xpath("div[@class=‘gl-i-wrap‘]/div[@class=‘p-img‘]/a/img/@source-data-lazy-img") dbservice(conn,"".join(p_name),"".join(p_sell_point),"".join(p_image),"".join(p_price)) if len(p_price) == 0: p_price = data.xpath(‘div/div[@class="p-price"]/strong/@data-price‘) print(s2) def shijinOU(json1,url,i): print(i) head = { ‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36‘, ‘method‘: ‘POST‘, ‘Content-Type‘: ‘application/json;charset=UTF-8‘, } data_json = json.dumps(json1) r = requests.post(url,data = data_json,headers=head) html = r.content.decode("utf-8") print("Status code:",r.status_code) new_data = json.loads(html) print("6666:" + html) for s in range(0,6): print(new_data[‘mailList‘][s]) if new_data[‘mailList‘][s][‘letter_type‘] == ‘咨询‘ : reqname = new_data[‘mailList‘][s][‘letter_title‘] reqtime = new_data[‘mailList‘][s][‘create_date‘] resname = new_data[‘mailList‘][s][‘org_id‘] isreply = new_data[‘mailList‘][s][‘isReply‘] reqtype = new_data[‘mailList‘][s][‘letter_type‘] #print(isreply) #print("询问标题:" + reqname + "询问时间:" + reqtime + "回答部门:" + resname + "是否回答:") zixunTiqu(new_data[‘mailList‘][s][‘original_id‘],reqname,reqtime,resname,isreply,reqtype) #if new_data[‘mailList‘][s][‘letter_type‘] == ‘建议‘ : #break #if new_data[‘mailList‘][s][‘letter_type‘] == ‘投诉‘ : def zixunTiqu(AH,reqname,reqtime,resname,isreply,reqtype): #print("询问标题:"+reqname+"询问时间:"+reqtime+"回答部门:"+resname+"是否回答:"+isreply) head = { ‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36‘, ‘method‘: ‘GET‘ } url2 = ‘http://www.beijing.gov.cn/hudong/hdjl/com.web.consult.consultDetail.flow?originalId=‘+AH r = requests.get(url2, headers=head) print(r.status_code) html = r.content.decode("utf-8") #print("777"+html) html1 = etree.HTML(html) #print(html) datas=html1.xpath(‘.//form[@id="f_baner"]/div‘) result = ‘‘ data = datas[0].xpath(‘//div[@class="col-xs-12 col-md-12 column p-2 text-muted mx-2"]//text()‘)[0] result = result + data.replace(‘\r‘, ‘‘).replace(‘\t‘, ‘‘).replace(‘\n‘, ‘ ‘) print("问题详细情况:" + result.strip() + "?") reqcontent = result.strip() restime = datas[1].xpath("//div/div/div[@class=‘col-xs-12 col-md-12 column o-border-bottom my-2‘]/div[@class=‘col-xs-12 col-md-12 column o-border-bottom2‘]/div[@class=‘col-xs-12 col-sm-3 col-md-3 my-2 ‘]//text()") print(restime) rescontents = datas[1].xpath("//div/div[@class=‘col-xs-12 col-md-12 column o-border-bottom my-2‘]/div[@class=‘col-xs-12 col-md-12 column p-4 text-muted my-3‘]//text()") #print(rescontents) resc = ‘‘ for rescontent in rescontents: resc = resc+rescontent.replace(‘\r‘, ‘‘).replace(‘\t‘, ‘‘).replace(‘\n‘, ‘‘) print(resc) db(conn, result.strip(),reqname,reqtime,resname,restime,resc,reqtype,isreply) if __name__==‘__main__‘: for i in range(0,100): print(‘***************************************************‘) page = 6*i fuck = {"PageCond/begin":page, "PageCond/length":6, "PageCond/isCount":"true", "keywords":"","orgids":"", "startDate":"","endDate":"", "letterType":"","letterStatue":"" } shijinOU(fuck,"http://www.beijing.gov.cn/hudong/hdjl/com.web.search.mailList.mailList.biz.ext",i) #sbreak #print(fuck)
结果:
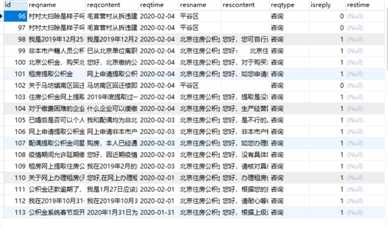
标签:top enc cond requests join base star gecko ret
原文地址:https://www.cnblogs.com/1502762920-com/p/12274772.html