标签:网站 代码 detail strip() ring 过程 type json 数据格式
经过几天的学习,今天终于完成了首都之窗的数据爬取,现在进行一下总结:
首都之窗的爬取我进行里两步:
一,使用selenium模拟浏览器翻页,爬取列表页上的信息,主要是各个详情页的url(详细说明请看上篇博客)
spider.py

1 # -*- coding: utf-8 -*- 2 import scrapy 3 from bjnew.items import BjnewItem 4 5 class SdzcSpider(scrapy.Spider): 6 name = ‘sdzc‘ 7 def start_requests(self): 8 urls = [ 9 ‘http://www.beijing.gov.cn/hudong/hdjl/com.web.search.mailList.flow‘ 10 ] 11 for url in urls: 12 yield scrapy.Request(url=url, meta={‘type‘: ‘0‘}, callback=self.parse_page, dont_filter=True) 13 14 def parse_page(self, response): 15 16 print(response.flags) 17 if int(response.flags[0]) == 0: 18 return 19 items = response.xpath(‘//*[@id="mailul"]/div‘) 20 print(response.xpath(‘//*[@id="page_span2"]/span[2]/text()‘).extract_first().strip()) 21 for it in items: 22 item = BjnewItem() 23 title = it.xpath(‘./div[1]/a/span/text()‘).extract_first().strip() 24 print(title) 25 zl0 = it.xpath(‘./div[1]/a/font/text()‘).extract_first().strip(‘·【‘) 26 zl = zl0.strip(‘】‘) 27 # print(zl) 28 info0 = it.xpath(‘./div[1]/a/@onclick‘).extract_first() 29 if len(info0) == 34: 30 info = info0[19:32] 31 else: 32 info = info0[19:27] 33 # print(info) 34 state = it.xpath(‘./div/div/div/div/text()‘).extract_first().strip() 35 # print(state) 36 if zl == "咨询": 37 url = "http://www.beijing.gov.cn/hudong/hdjl/com.web.consult.consultDetail.flow?originalId=" + info 38 elif zl == "建议": 39 url = "http://www.beijing.gov.cn/hudong/hdjl/com.web.suggest.suggesDetail.flow?originalId=" + info 40 elif zl == "投诉": 41 url = "http://www.beijing.gov.cn/hudong/hdjl/com.web.complain.complainDetail.flow?originalId=" + info 42 print(url) 43 item[‘url‘] = url 44 item[‘title‘] = title 45 item[‘zl‘] = zl 46 item[‘info‘] = info 47 item[‘state‘] = state 48 yield item 49 yield scrapy.Request(url=response.url, meta={‘type‘: ‘1‘}, callback=self.parse_page, dont_filter=True)
二、仍然使用scrapy框架进行爬取,从昨天爬取的json文件中读取各个详情页的url进行爬取,
几点说明:
1、昨天爬了5600多页,3万多条的数据,但是今天查看网页发现少了几十页,应该是网站删除了,所以在代码中做了以下判断
1 # 通过title判断网页是否存在 2 if pan == "-首都之窗-北京市政务门户网站": 3 yield
2、在爬取过程中,出现了以下错误

原因是这个网页,只有提问,没有回答,本想写一个判断将他爬下来,但是在列表页里找不到该网页,原因是只是删除了列表页里的连接,但是原网页并没有删除,所以也就没有爬取
最后完整的代码:
1 # -*- coding: utf-8 -*- 2 import scrapy 3 import json 4 from beijing4.items import Beijing4Item 5 6 class BjSpider(scrapy.Spider): 7 8 name = ‘bj‘ 9 allowed_domains = [‘beijing.gov.cn‘] 10 # 从文件里读取详情页的url 11 def start_requests(self): 12 with open(‘F:/Users/Lenovo/json/info.json‘, ‘r‘, encoding=‘utf8‘)as fp: 13 json_data = json.load(fp) 14 # print(json_data) 15 for i in range(len(json_data)): 16 yield scrapy.Request(url=json_data[i][‘url‘]) 17 # 详情页解析方法 18 def parse(self, response): 19 item = Beijing4Item() 20 # 获取网页title,判断网页是否存在 21 pan = response.xpath(‘/html/head/title/text()‘).extract_first() 22 # print(pan) 23 if pan == "-首都之窗-北京市政务门户网站": 24 yield 25 # 由于不同类型网页解析不一样 26 else: 27 if response.url.find("com.web.suggest.suggesDetail.flow") >= 0: 28 title = response.xpath("/html/body/div[2]/div/div[2]/div[1]/div[1]/div[2]/strong/text()").extract_first().strip() 29 print(title) 30 question = response.xpath(‘/html/body/div[2]/div/div[2]/div[1]/div[3]/text()‘).extract_first().strip() 31 print(question) 32 questioner0 = response.xpath(‘/html/body/div[2]/div/div[2]/div[1]/div[2]/div[1]/text()‘).extract_first().strip(‘来信人: ‘) 33 questioner = questioner0.strip() 34 print(questioner) 35 q_time = response.xpath(‘/html/body/div[2]/div/div[2]/div[1]/div[2]/div[2]/text()‘).extract_first().strip(‘时间:‘) 36 print(q_time) 37 s_q_num = response.xpath(‘/html/body/div[2]/div/div[2]/div[1]/div[2]/div[3]/label/text()‘).extract_first().strip() 38 print(s_q_num) 39 answerer0 = response.xpath(‘/html/body/div[2]/div/div[2]/div[2]/div/div[1]/div[1]/div[2]/text()‘).extract() 40 answerer = ‘‘.join([r.strip() for r in answerer0]) 41 print(answerer) 42 a_time = response.xpath(‘/html/body/div[2]/div/div[2]/div[2]/div/div[1]/div[1]/div[3]/text()‘).extract_first().strip(‘答复时间:‘) 43 print(a_time) 44 answer = ‘‘.join(response.xpath(‘/html/body/div[2]/div/div[2]/div[2]/div/div[1]/div[2]‘).xpath(‘string(.)‘).extract_first().strip().split()) 45 print(answer) 46 item[‘kind‘] = ‘建议‘ 47 item[‘title‘] = title 48 item[‘question‘] = question 49 item[‘questioner‘] = questioner 50 item[‘q_time‘] = q_time 51 item[‘s_q_num‘] = s_q_num 52 item[‘answerer‘] = answerer 53 item[‘a_time‘] = a_time 54 item[‘answer‘] = answer 55 yield item 56 57 elif response.url.find("com.web.consult.consultDetail.flow") >= 0: 58 title = response.xpath(‘//*[@id="f_baner"]/div[1]/div[1]/div[2]/strong/text()‘).extract_first().strip() 59 print(title) 60 question = response.xpath(‘//*[@id="f_baner"]/div[1]/div[3]/text()‘).extract_first().strip() 61 # print(question) 62 questioner0 = response.xpath(‘//*[@id="f_baner"]/div[1]/div[2]/div[1]/text()‘).extract_first().strip( 63 ‘来信人: ‘) 64 questioner = questioner0.strip() 65 # print(questioner) 66 q_time = response.xpath(‘//*[@id="f_baner"]/div[1]/div[2]/div[2]/text()‘).extract_first().strip(‘时间:‘) 67 # print(q_time) 68 s_q_num = response.xpath(‘//*[@id="f_baner"]/div[1]/div[2]/div[3]/label/text()‘).extract_first().strip() 69 # print(s_q_num) 70 answerer0 = response.xpath(‘//*[@id="f_baner"]/div[2]/div/div[1]/div[1]/div[2]/text()‘).extract() 71 answerer = ‘‘.join([r.strip() for r in answerer0]) 72 # print(answerer) 73 a_time = response.xpath(‘//*[@id="f_baner"]/div[2]/div/div[1]/div[1]/div[3]‘ 74 ‘/text()‘).extract_first().strip(‘答复时间:‘) 75 # print(a_time) 76 answer = ‘‘.join(response.xpath(‘//*[@id="f_baner"]/div[2]/div/div[1]/div[2]‘).xpath(‘string(.)‘).extract_first().strip().split()) 77 print(answer) 78 item[‘kind‘] = ‘咨询‘ 79 item[‘title‘] = title 80 item[‘question‘] = question 81 item[‘questioner‘] = questioner 82 item[‘q_time‘] = q_time 83 item[‘s_q_num‘] = s_q_num 84 item[‘answerer‘] = answerer 85 item[‘a_time‘] = a_time 86 item[‘answer‘] = answer 87 yield item 88 89 elif response.url.find("com.web.complain.complainDetail.flow") >= 0: 90 title = response.xpath(‘//*[@id="Dbanner"]/div[1]/div[1]/div[2]/strong/text()‘).extract_first().strip() 91 print(title) 92 question = response.xpath(‘//*[@id="Dbanner"]/div[1]/div[3]/text()‘).extract_first().strip() 93 print(question) 94 questioner0 = response.xpath(‘//*[@id="Dbanner"]/div[1]/div[2]/div[1]/text()‘).extract_first().strip( 95 ‘来信人: ‘) 96 questioner = questioner0.strip() 97 print(questioner) 98 q_time = response.xpath(‘//*[@id="Dbanner"]/div[1]/div[2]/div[2]/text()‘).extract_first().strip(‘时间:‘) 99 print(q_time) 100 s_q_num = response.xpath(‘//*[@id="Dbanner"]/div[1]/div[2]/div[3]/label/text()‘).extract_first().strip() 101 print(s_q_num) 102 answerer0 = response.xpath(‘//*[@id="Dbanner"]/div[2]/div[1]/div[1]/div[1]/div[2]/span/text()‘).extract() 103 answerer = ‘‘.join([r.strip() for r in answerer0]) 104 print(answerer) 105 a_time = response.xpath(‘//*[@id="Dbanner"]/div[2]/div[1]/div[1]/div[1]/div[3]/text()‘).extract_first().strip(‘答复时间:‘) 106 print(a_time) 107 answer = ‘‘.join(response.xpath(‘//*[@id="Dbanner"]/div[2]/div[1]/div[1]/div[2]‘).xpath(‘string(.)‘).extract_first().strip().split()) 108 print(answer) 109 item[‘kind‘] = ‘投诉‘ 110 item[‘title‘] = title 111 item[‘question‘] = question 112 item[‘questioner‘] = questioner 113 item[‘q_time‘] = q_time 114 item[‘s_q_num‘] = s_q_num 115 item[‘answerer‘] = answerer 116 item[‘a_time‘] = a_time 117 item[‘answer‘] = answer 118 yield item
爬取阶段的任务就完成了,因为在将数据存到json文件中时,就对数据格式进行了设置所以数据清洗就简单多了,最后的数据格式如下:
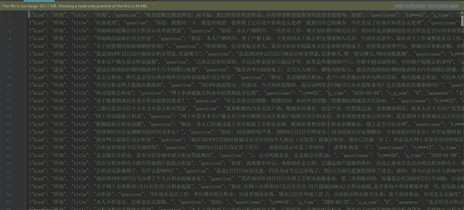
还有一点就是,昨天爬取了5600个网页,花了4个多小时,今天爬了3万多个网页花了1个小时左右,想来原因是用了selenium的原因。
接下来就是图形展示了。
标签:网站 代码 detail strip() ring 过程 type json 数据格式
原文地址:https://www.cnblogs.com/KYin/p/12275019.html
