标签:info 作者 价值 需要 further head font 样本 针对
文章名《How to Fine-Tune BERT for Text Classification》,2019,复旦大学
如何在文本分类中微调BERT模型?
摘要:预训练语言模型已经被证明在学习通用语言表示方面有显著效果,作为一种最先进的预训练语言模型,BERT在多项理解任务中取得了惊人的成果。在本文中,作者针对文本分类任务的BERT微调方法,给出了微调模式的一般解决方案。最后,提出的解决方案在8个广泛研究的文本分类数据集上获取了最新的结果。
作者认为尽管BERT在多项自热语言理解任务中获得了令人惊人的结果,但其潜在的能力依然没有被探索出来,几乎很少有研究工作在增强BERT性能方面,所以研究如何最大化限度的利用BERT在文本分类中的任务,探索了几种微调的方法,并进行了详细的分析。
进行了如下散步操作:1)进一步在开放域预训练BERT;2)采用多任务方式可选择性地微调BERT;3)在目标任务上微调BERT。同时研究了fine-tuning技术对Bert在长文本任务、隐藏层选择、隐藏层学习率、知识遗忘、少样本学习问题上的影响。
1. 微调策略:不同网络层包含不同的特征信息,哪一层更有助于目标任务?这是一个考虑的方向
2. 进一步预训练:在目标域进一步得到预训练模型
3. 多任务微调:多任务可以挖掘共享信息,同时对所有任务进行微调是否,使用多任务策略对结果有帮助。
使用框架:
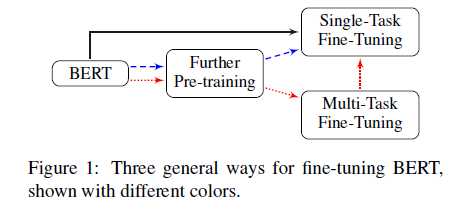
该文的重点放在了是否进行Further Pre-training和Multi-Task Fine-Truning,在实际文本分类过程中,模型微调的策略可以从以下几个方法开展:
1. 处理文本的长度。1)Truncation methods,head+tail方法被证明是有效的,具有最佳的性能;2)Hierarchical methods,先将长文本切割成 K = L / 510 个片段,之后分别取不同片段的向量表示。
2. 不同网络层的特征学则。IMDb 数据集中进行,最后显示只使用最后一层的输出取得了最佳性能。
3. 灾难性遗忘。使用BERT时尽量使用小的学习率,模型能够有效、快速收敛,2e-5
4. 不同层次的学习率衰减。模型底层用于捕捉详细、通用的特征信息,需要更低的学习率来寻求最优解;顶层更直接与任务相关,需要更大的学习率加速学习,这一点时借鉴ULMFit中的三角学习率。
5. 进一步预训练。BERT是在通用域训练得到的,但实际的任务局限在一个单一的领域,为了更好地适应下游任务,作者在BERT又在训练集、领域文本和交叉域文本进行一定步数的Pretraining,实验结果也显示出一定优势。在训练集做Pretraining时,作者指出,训练的步数太少达不到效果,太多会造成灾难性遗忘,选择100K作为一个训练步数是合理的。
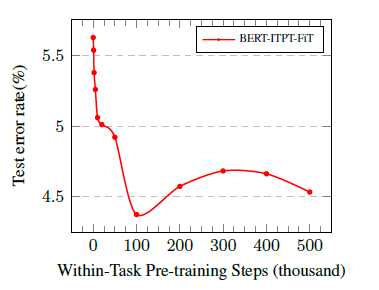
6. 在领域内的Pretraing具有较好的效果
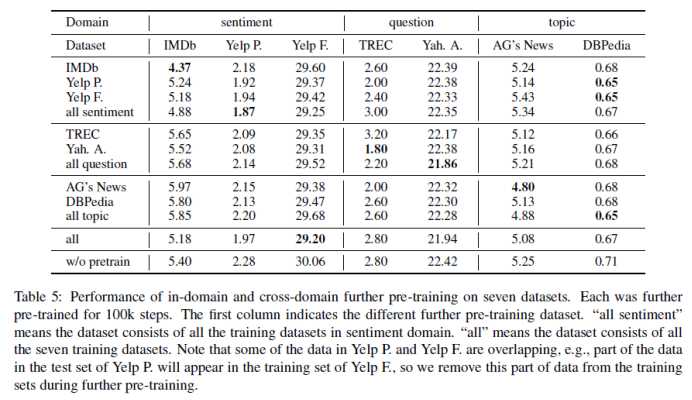
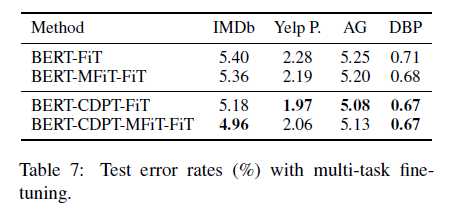
7. 多任务实验效果,在交叉领域中得到的模型也有最佳的性能
有价值结论:
1)BERT的顶层输出对文本分类更加有用;
2)适当的分层递减学习策略能够有助于BERT克服灾难性遗忘;
3)任务内的进一步预训练模式可以显著提高对任务处理的性能;
4)先进行多任务微调对单个任务微调有帮助,但没有进一步在训练集中预训练的方式提升大
5)BERT可以利用小数据改进任务
《How to Fine-Tune BERT for Text Classification》-阅读心得
标签:info 作者 价值 需要 further head font 样本 针对
原文地址:https://www.cnblogs.com/demo-deng/p/12283165.html