标签:dig size 用户 根据 bug man innodb 信息 ati
谈到服务器性能,可能第一个从脑中蹦出来的是:查询速度?这确实是我们最常接触的方面,但性能其实还包括例如CPU利用率、可扩展性等很多方面。通过总结发现,不管修改的是哪一方面,最终都在影响一个量:时间。因此不妨将性能定义为:完成任务所需时间的度量(性能即响应时间)。那什么是优化呢?如果认为优化是降低CPU使用率 那么此时可能你的任务需要更长的时间来完成。如果认为是提升了每次查询(select,update,delete,insert等)的量,这其实只是吞吐量的优化,此时你的CPU的压力可能已经增大了。因此我们只能假设性能优化是在一定的工作负载下尽可能的降低响应时间。最后我们将实际的讨论两种类型的性能剖析:基于执行时间的分析和基于等待的分析
基于执行时间的分析:什么任务的执行时间最长
基于等待的分析:判断任务在什么地方被阻塞的时间最长
1、剖析全局性能
性能优化的前提当然是我们得知道哪出了问题,通常可以通过慢日志和pt_query_digest进行分析,对于应用程序我们则可以使用new Relic、xhprof、xdebug、Ifp(Instrumentation-for-php)来进行检测。当然对于性能分析我们不能时时进行检测,因为大量检测IO本身对应用会有影响。可以通过以下语句来控制频率:
<?php $profile_enable = mt_rand(0, 100) > 99;
此时利用该标志可以让1%的请求为我们提供检测样本
2、剖析局部性能
在经过全局剖析后,通常能定位出具体问题点,接下来就对具体问题进行分析;在实战过程主要使用:show status; show profile; 检查慢日志条目
2.1 show profile
该工具默认为禁用状态,需要手动开启(该工具提供的功能在新版本中由Performance Schema来实现,简化了使用)

开启后 该工具会将查询请求记录至一张临时表中,
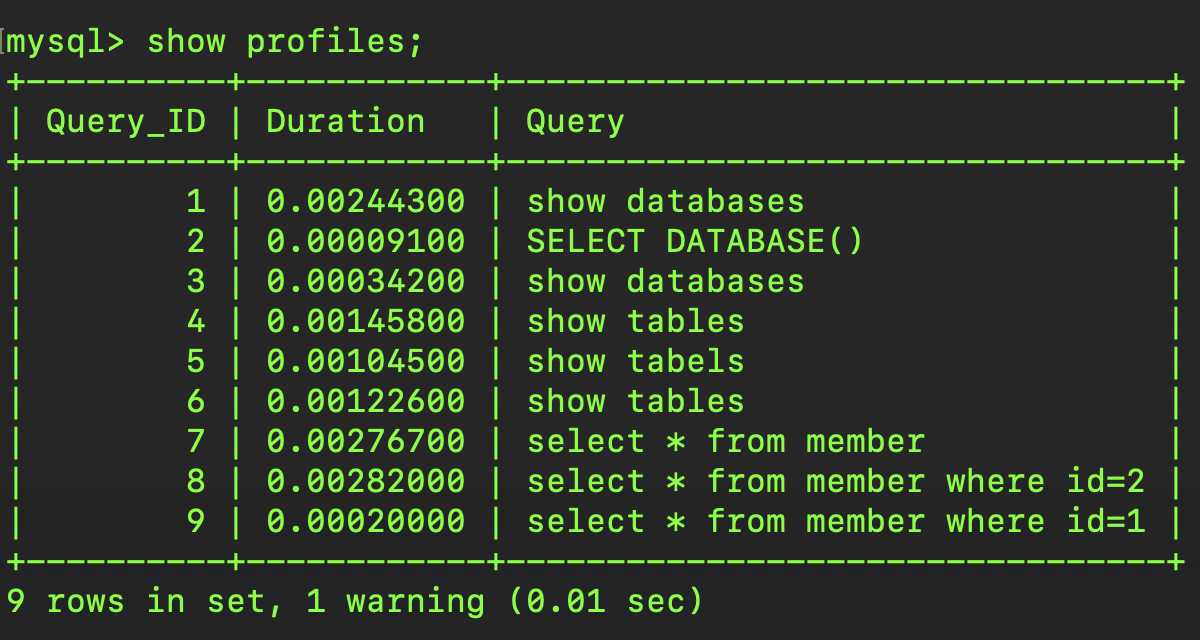
该工具详细记录了每次查询请求的执行时间,但对于一些执行较快的语句精度似乎还有欠缺,于是我们使用:
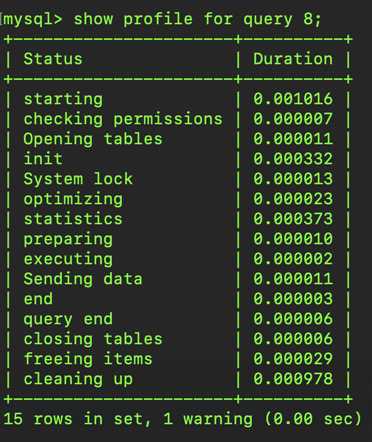
通过该结果我们可以看到第8号查询(select * from member where id=2)的所有时间消耗,经过对比,发现的主要时间花在了starting、cleaning up过程,不过这样不是很直观,因为每条语句执行后经过上述分析返回的内容不尽相同,有什么办法可以更方便的看到信息呢?没错就是INFORMATION_SCHEMA.PROFILING
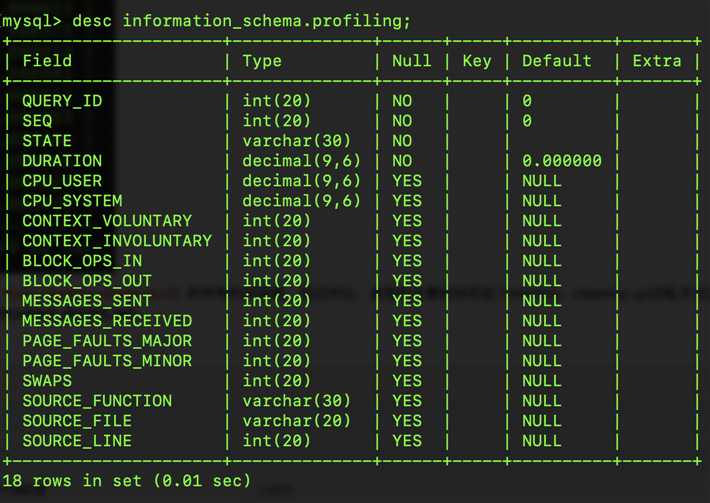
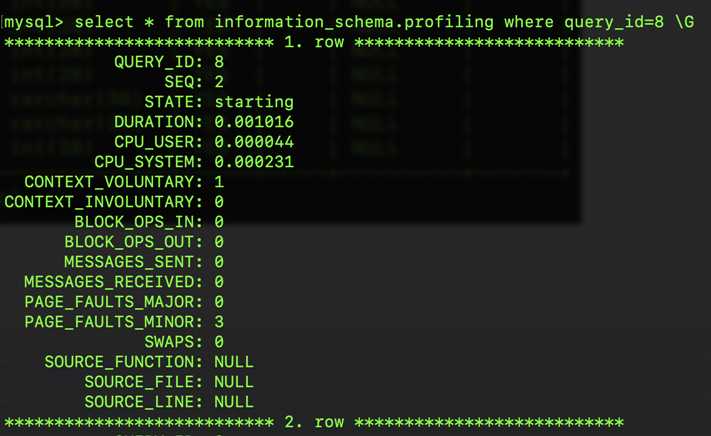
set @query_id = 8;
select
state,
sum(duration) total_time,
round(100 * sum(duration) / (select sum(duration) from information_schema.profiling where query_id=@query_id), 2) percent,
count(*) call_times,
sum(duration)/count(*) avg_time
from information_schema.profiling where query_id=@query_id group by state order by total_time desc
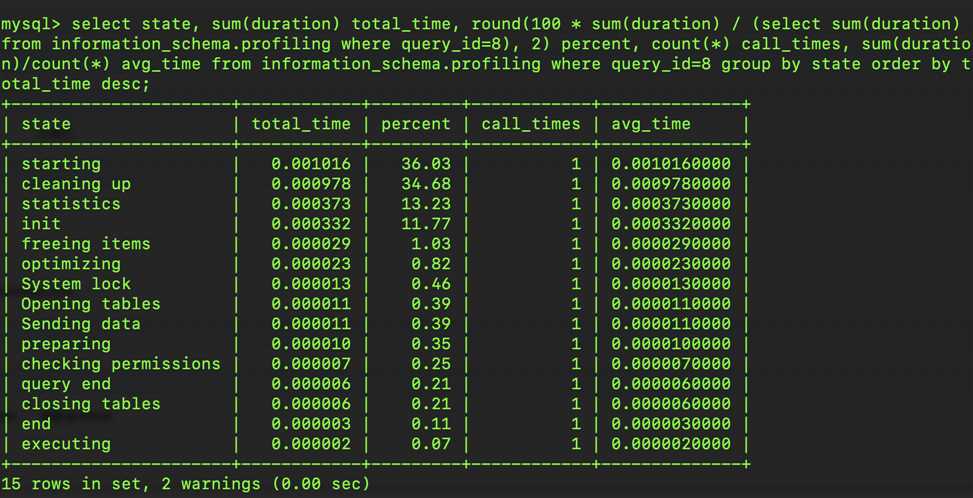
从上述结果看,和之前的分析大致一直,之后我们就可以根据实际情况进行优化调整 当然根据优化原则,一些占比比较低的是没有必要优化的。该结果帮我们定位到了问题,但并没有告诉我们是什么原因导致的,因此还需要进一步进行分析。
2.2 show status
show status并不算一个剖析工具,它是一个计数器,该命令返回的计数器既有服务器级别的也有回话级别的,因此需要注意区分,具体的参考官方文档说明。show global status则显示的是服务器级别的计数器。show status中仅有一项表示操作时间(innodb_row_lock_time),而且也是全局的。虽然不能给出消耗了多少时间,但是我们通过观察一些有用的计数器还是可以得到一些非常有用的信息。例如:句柄计数器(handler counter)、临时文件和表计数器
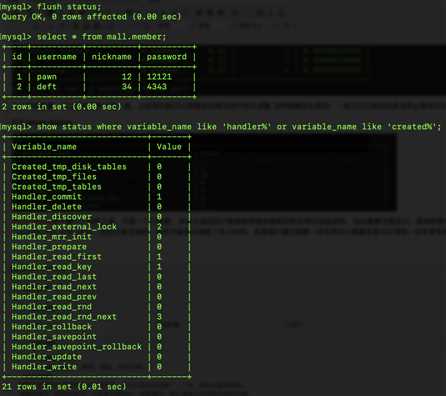
其中created_tmp*表示使用到的临时表的情况 当然因为本次查询相对简单 并没有使用使用到临时表。handler_read_rnd_next表示没有使用索引的读操作。上述部分结果似乎我们通过explain也可以得到,但explain是通过估算得到的结果,而上述结果是经过实际测量得到的。而且explain无法告诉我们临时表是否是磁盘表,这和内存临时表性能的差别是很大的
2.3 慢查询日志
2.4 使用performance schema

该结果指示了系统主要的等待原因
2.5 区别单条查询问题还是服务器问题
使用 show global status
该方法实际是以较高频率执行show global status 来捕获数据,可通过Threads_running、Threads_connected、Questions和Queries的波动来发现问题。例如:
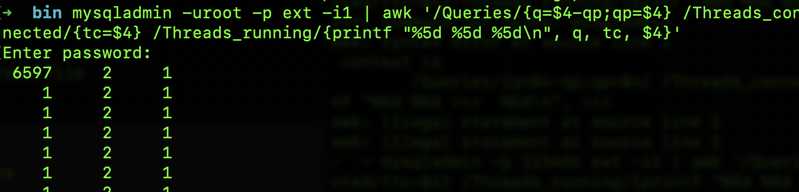
如果这三个数据的趋势对于服务器级别的偶尔停顿的敏感性很高,一般发生此类问题时,根据原因的不同和应用连接数据库方式的不同,每秒的查询数(queries)一般会下跌,而其他两个则至少有一个会出现尖刺。
使用 show processlist
这个方式是不停的捕获 show processlist的输出来观察是否有大量线程处于不正常的状态或者其他不正常的特征。例如查询很少长时间处于"statistics"状态,该状态一般指服务器在查询优化阶段如何确定表关联的顺序(通常很快),也很少见到大量线程报告当前连接用户是"Unauthenticateduser"未经验证的用户,这只是在连接握手的中间过程中的状态,当客户端等待输入用于登陆的用户信息的时候才会出现。

如果要查看不同的列,修改grep的模式即可。当然该结果也可以通过查询information_schema.processlist来获取。其中大量线程处于"freeing items"状态是出现了大量有问题查询的明显特征和指示
使用慢日志发现问题 需要开启慢日志并在全局级别色值long_query_time为0,并且要确认所有的连接都采用了新的设置。如果因为某些原因,不能设置慢日志记录所有的查询,也可通过tcpdump和pt_query_digest工具来模拟。要注意找到吞吐量突然下降时间段的日志。查询是在完成阶段才写入到慢日志查询,所以堆积会造成大量查询处于完成阶段。

awk ‘/^# Time:/{print $3, $4, c;c=0}/^# User/{c++}‘ nagexiaopangzis-MacBook-Pro-slow.log
2.6 使用 user_statistics
在MySQL中我们通常可以对一些表的监测找到数据库最花费时间的地方,什么表或索引使用频率比较高或者那些索引创建后并未有使用:
show tables from information_schema like ‘%_statistics‘;
该命令根据实际情况主要展示出一下表:
statistics
client_statistics
index_statistics
table_statistics
thread_statistics
user_statistics
标签:dig size 用户 根据 bug man innodb 信息 ati
原文地址:https://www.cnblogs.com/2019PawN/p/12271592.html