标签:数据下载 run time 服务 oca 计算 分析 lse 脚本
本次安装的版本是截止2020.1.30最新的版本0.17.0
需要Java 8(8u92 +)以上的版本,否则会有问题
Linux,Mac OS X或其他类似Unix的操作系统(不支持Windows)
Druid包括一组参考配置和用于单机部署的启动脚本:
nano-quickstartmicro-quickstartsmallmediumlargexlargebin/start-nano-quickstartconf/druid/single-server/nano-quickstartbin/start-micro-quickstartconf/druid/single-server/micro-quickstartbin/start-smallconf/druid/single-server/smallbin/start-mediumconf/druid/single-server/mediumbin/start-largeconf/druid/single-server/large启动命令: bin/start-xlarge
配置目录: conf/druid/single-server/xlarge
我们这里做测试使用选择最低配置即可nano-quickstart
访问官网:
http://druid.io/现在也会跳转https://druid.apache.org/
或者直接访问https://druid.apache.org/
点击download进入下载页面:
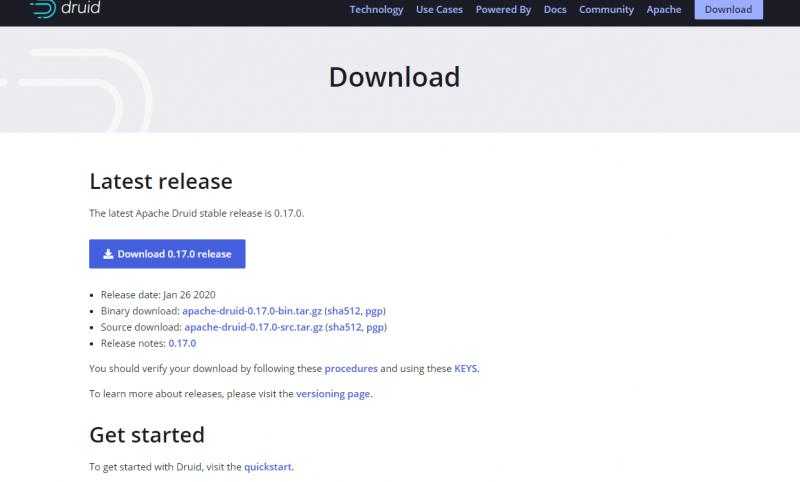
选择最新版本: apache-druid-0.17.0-bin.tar.gz 进行下载
200多M
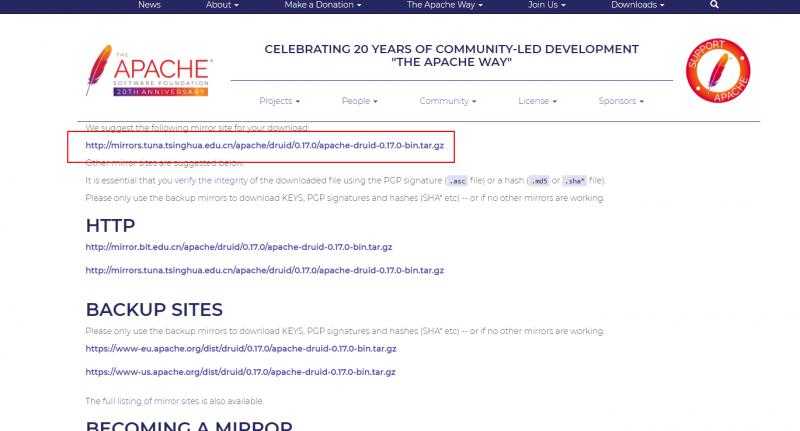
也可以选择下载源码包 用maven进行编译
上传安装包
在终端中运行以下命令来安装Druid:
tar -xzf apache-druid-0.17.0-bin.tar.gz
cd apache-druid-0.17.0安装包里有这几个目录:
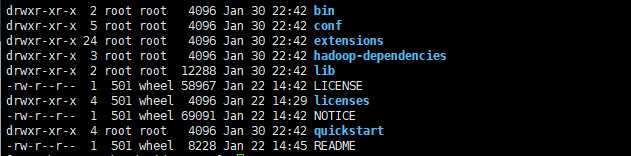
LICENSE和NOTICE文件bin/* -脚本conf/* -单服务器和集群设置的示例配置extensions/* -扩展hadoop-dependencies/* -Druid Hadoop依赖lib/* -Druid库quickstart/* -快速入门教程的配置文件,样本数据和其他文件#进入我们要启动的配置文件位置:
cd conf/druid/single-server/nano-quickstart/
_common 公共配置

是druid一些基本的配置,比如元数据库地址 各种路径等等
其他的是各个节点的配置
比较类似,比如broker
cd broker/
jvm配置
main配置
runtime运行时相关的配置
回到主目录
启动的conf在
cd conf/supervise/single-server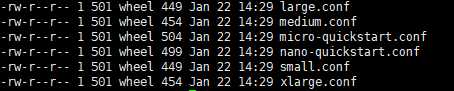
里面是不同配置启动不同的脚本
回到主目录
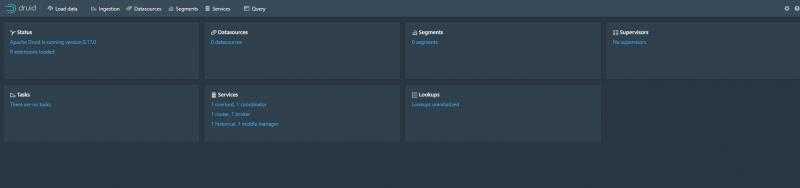
./bin/start-nano-quickstart启动成功:

访问
localhost:8888
看到管理页面
如果要修改端口,需要修改配置的端口和主目录下的
vi bin/verify-default-ports Druid提供了一个示例数据文件,其中包含2015年9月12日发生的Wiki的示例数据。
此样本数据位于quickstart/tutorial/wikiticker-2015-09-12-sampled.json.gz
示例数据大概是这样:
{
"timestamp":"2015-09-12T20:03:45.018Z",
"channel":"#en.wikipedia",
"namespace":"Main",
"page":"Spider-Man's powers and equipment",
"user":"foobar",
"comment":"/* Artificial web-shooters */",
"cityName":"New York",
"regionName":"New York",
"regionIsoCode":"NY",
"countryName":"United States",
"countryIsoCode":"US",
"isAnonymous":false,
"isNew":false,
"isMinor":false,
"isRobot":false,
"isUnpatrolled":false,
"added":99,
"delta":99,
"deleted":0,
}Druid加载数据分为以下几种:
我们这样演示一下加载示例文件数据

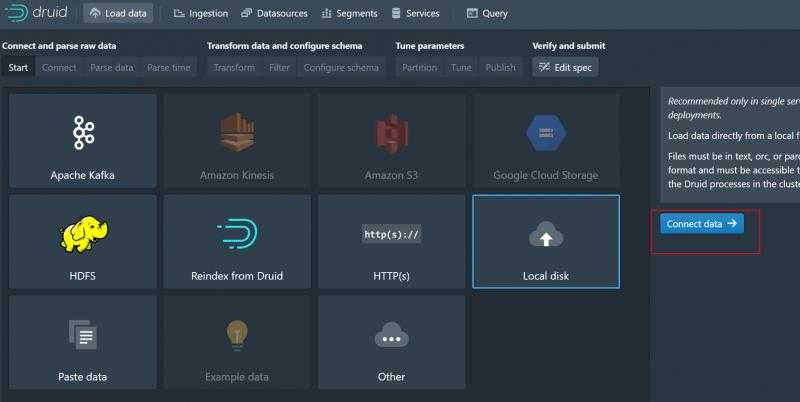
Base directory输入quickstart/tutorial/
File filter输入 wikiticker-2015-09-12-sampled.json.gz
然后点击apply预览 就可以看见数据了 点击Next:parse data解析数据
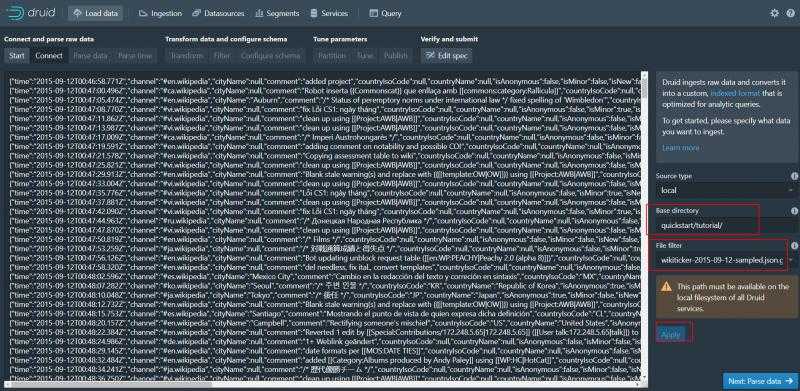
可以看到json数据已经被解析了 继续解析时间
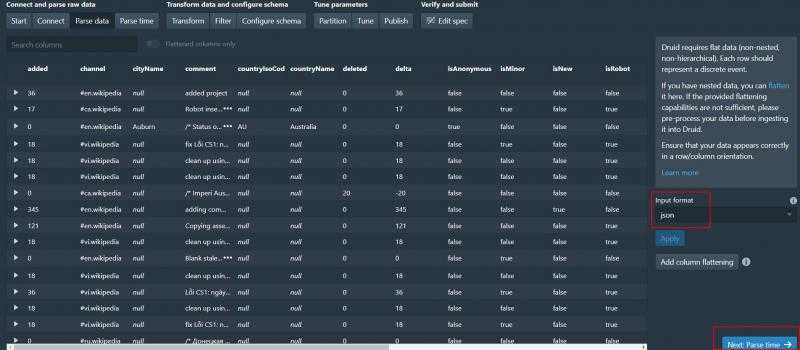
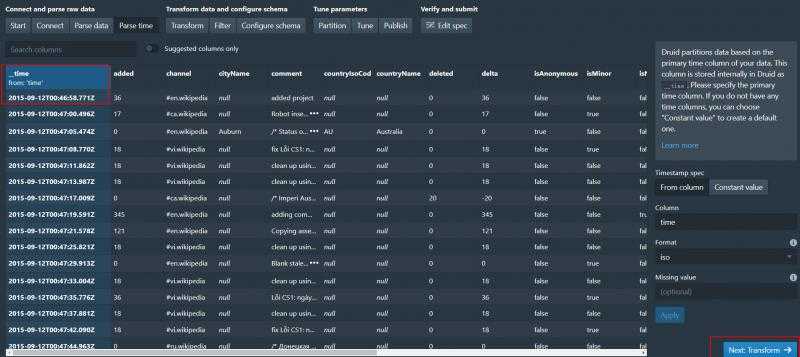
解析时间成功 之后两步是transform和filter 这里不做演示了 直接next
这一步会让我们确认Schema 可以做一些修改
由于数据量较小 我们直接关掉Rollup 直接下一步
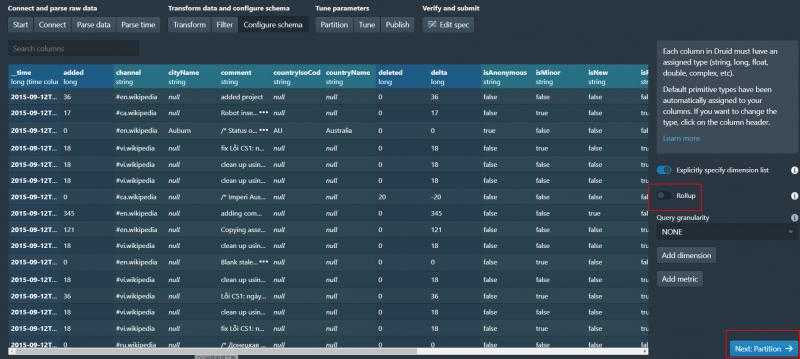
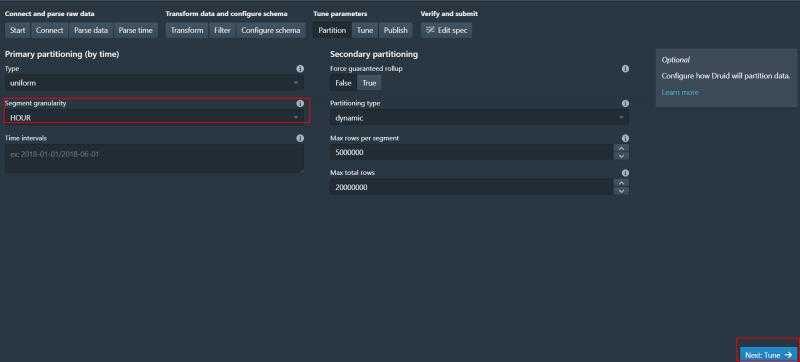
这里可以设置数据分段 我们选择hour next
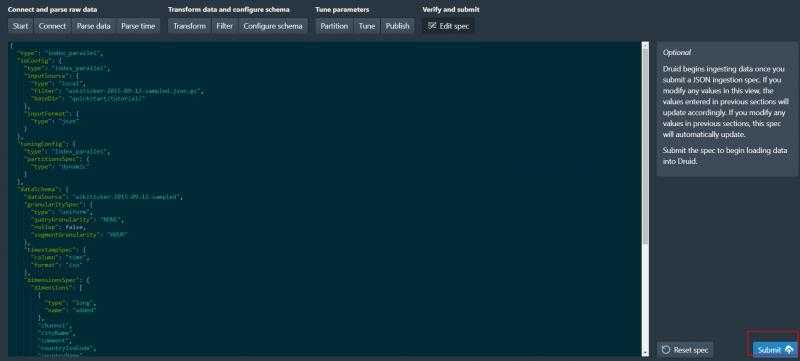
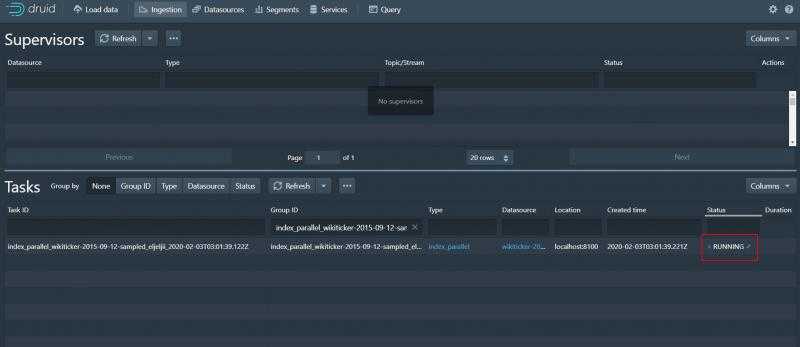
等待任务成功
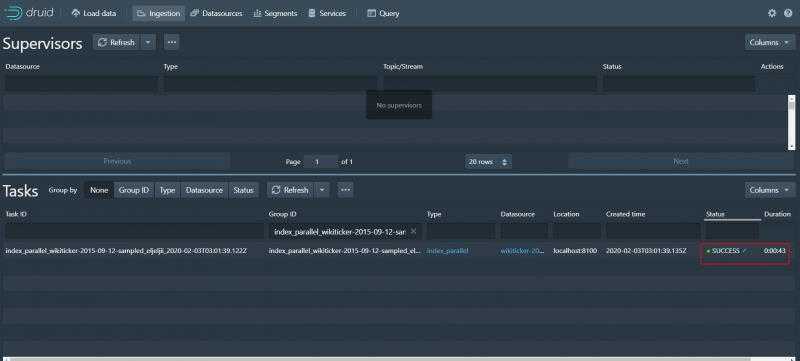
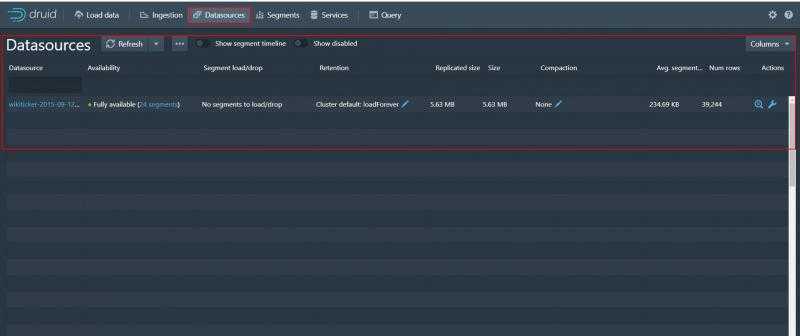
选择datasources 可以看到我们加载的数据
可以看到数据源名称 Fully是完全可用 还有大小等各种信息
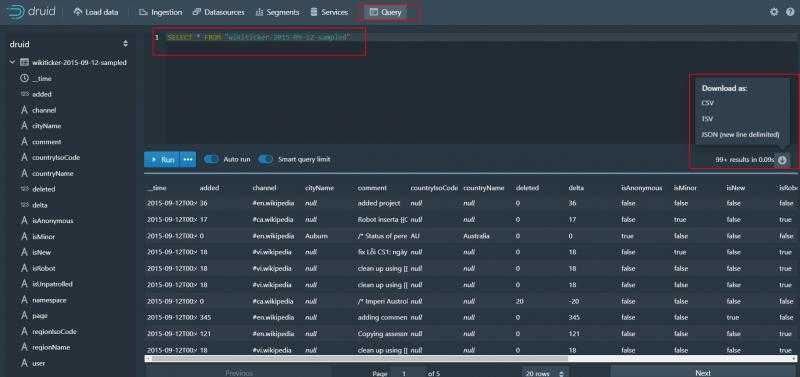
点击query按钮
我们可以写sql查询数据了 还可以将数据下载
Druid相关博文
静下心来,努力的提升自己,永远都没有错。更多实时计算相关博文,欢迎关注实时流式计算

Druid入门(1)—— 快速入门实时分析利器-Druid_0.17
标签:数据下载 run time 服务 oca 计算 分析 lse 脚本
原文地址:https://www.cnblogs.com/tree1123/p/12289827.html