标签:执行 进程 cli 其他 速度 mic graph cpu sch
Spark最初由美国加州伯克利大学的AMP实验室于2009年开发,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。
Spark特点
Spark具有如下几个主要特点:
运行速度快:Spark使用先进的DAG(Directed Acyclic Graph,有向无环图)执行引擎,以支持循环数据流与内存计算,基于内存的执行速度可比Hadoop MapReduce快上百倍,基于磁盘的执行速度也能快十倍;
容易使用:Spark支持使用Scala、Java、Python和R语言进行编程,简洁的API设计有助于用户轻松构建并行程序,并且可以通过Spark Shell进行交互式编程;
通用性:Spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件,这些组件可以无缝整合在同一个应用中,足以应对复杂的计算;
运行模式多样:Spark可运行于独立的集群模式中,或者运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源。
Spark的五大特性(重要)

Spark相对于Hadoop的优势
Hadoop虽然已成为大数据技术的事实标准,但其本身还存在诸多缺陷,最主要的缺陷是其MapReduce计算模型延迟过高,无法胜任实时、快速计算的需求,因而只适用于离线批处理的应用场景。
回顾Hadoop的工作流程,可以发现Hadoop存在如下一些缺点:
表达能力有限。计算都必须要转化成Map和Reduce两个操作,但这并不适合所有的情况,难以描述复杂的数据处理过程;
磁盘IO开销大。每次执行时都需要从磁盘读取数据,并且在计算完成后需要将中间结果写入到磁盘中,IO开销较大;
延迟高。一次计算可能需要分解成一系列按顺序执行的MapReduce任务,任务之间的衔接由于涉及到IO开销,会产生较高延迟。而且,在前一个任务执行完成之前,其他任务无法开始,难以胜任复杂、多阶段的计算任务。
Spark主要具有如下优点:
Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比MapReduce更灵活;
Spark提供了内存计算,中间结果直接放到内存中,带来了更高的迭代运算效率;
Spark基于DAG的任务调度执行机制,要优于MapReduce的迭代执行机制。
Spark最大的特点就是将计算数据、中间结果都存储在内存中,大大减少了IO开销
Spark提供了多种高层次、简洁的API,通常情况下,对于实现相同功能的应用程序,Spark的代码量要比Hadoop少2-5倍。
但Spark并不能完全替代Hadoop,主要用于替代Hadoop中的MapReduce计算模型。实际上,Spark已经很好地融入了Hadoop生态圈,并成为其中的重要一员,它可以借助于YARN实现资源调度管理,借助于HDFS实现分布式存储。
Spark生态系统
Spark的生态系统主要包含了Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX 等组件,各个组件的具体功能如下:
Spark Core:Spark Core包含Spark的基本功能,如内存计算、任务调度、部署模式、故障恢复、存储管理等。Spark建立在统一的抽象RDD之上,使其可以以基本一致的方式应对不同的大数据处理场景;通常所说的Apache Spark,就是指Spark Core;
Spark SQL:Spark SQL允许开发人员直接处理RDD,同时也可查询Hive、HBase等外部数据源。Spark SQL的一个重要特点是其能够统一处理关系表和RDD,使得开发人员可以轻松地使用SQL命令进行查询,并进行更复杂的数据分析;
Spark Streaming:Spark Streaming支持高吞吐量、可容错处理的实时流数据处理,其核心思路是将流式计算分解成一系列短小的批处理作业。Spark Streaming支持多种数据输入源,如Kafka、Flume和TCP套接字等;
MLlib(机器学习):MLlib提供了常用机器学习算法的实现,包括聚类、分类、回归、协同过滤等,降低了机器学习的门槛,开发人员只要具备一定的理论知识就能进行机器学习的工作;
GraphX(图计算):GraphX是Spark中用于图计算的API,可认为是Pregel在Spark上的重写及优化,Graphx性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。
Spark基本概念
在具体讲解Spark运行架构之前,需要先了解几个重要的概念:
RDD:是弹性分布式数据集(Resilient Distributed Dataset)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型;
DAG:是Directed Acyclic Graph(有向无环图)的简称,反映RDD之间的依赖关系;
Executor:是运行在工作节点(Worker Node)上的一个进程,负责运行任务,并为应用程序存储数据;
应用:用户编写的Spark应用程序;
任务:运行在Executor上的工作单元;
作业:一个作业包含多个RDD及作用于相应RDD上的各种操作;
阶段:是作业的基本调度单位,一个作业会分为多组任务,每组任务被称为“阶段”,或者也被称为“任务集”。
Spark结构设计
Spark运行架构包括集群资源管理器(Cluster Manager)、运行作业任务的工作节点(Worker Node)、每个应用的任务控制节点(Driver)和每个工作节点上负责具体任务的执行进程(Executor)。其中,集群资源管理器可以是Spark自带的资源管理器,也可以是YARN或Mesos等资源管理框架。
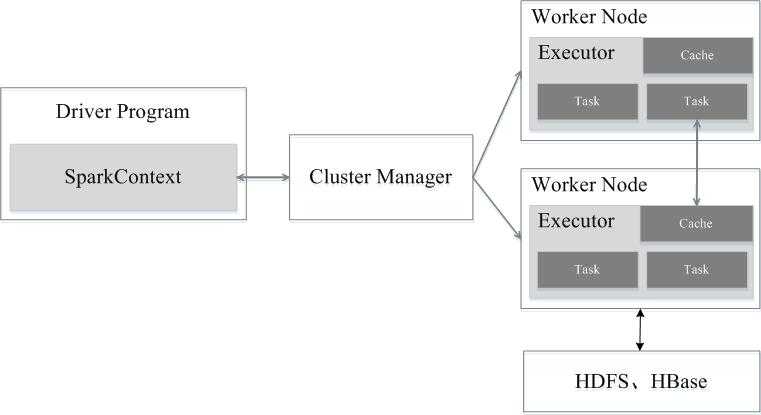
Spark各种概念之间的关系
在Spark中,一个应用(Application)由一个任务控制节点(Driver)和若干个作业(Job)构成,一个作业由多个阶段(Stage)构成,一个阶段由多个任务(Task)组成。当执行一个应用时,任务控制节点会向集群管理器(Cluster Manager)申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行任务,运行结束后,执行结果会返回给任务控制节点,或者写到HDFS或者其他数据库中。
窄依赖和宽依赖
Spark中RDD的高效与DAG(有向无环图)图有着莫大的关系,
在DAG调度中需要对计算过程划分Stage,
而划分的依据就是就是RDD之间的依赖关系。
针对不同的转换函数,RDD之间的依赖关系分为窄依赖(narrow dependency)
和宽依赖(Wide Depencency,也称为Shuffle Depencency)。
窄依赖:
指父RDD的每个分区只被子RDD的一个分区所使用,子RDD分区通常对应常数个父RDD分区,即一个父rdd的数据到一个子rdd或多个父rdd的数据到一个子rdd(一对一或多对一)
宽依赖:
是指父RDD的每个分区都可能被多个子RDD分区所使用,子RDD分区通常对应所有的父RDD分区,即一个父rdd的数据到多个子rdd(一对多)
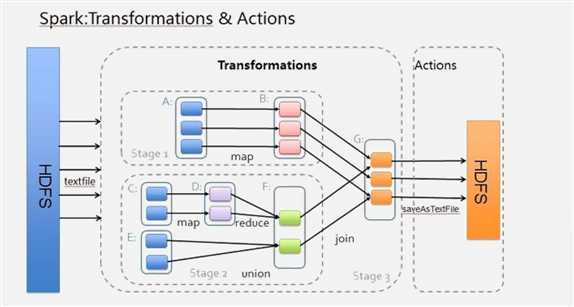
相比于依赖,窄依赖对优化很有利,主要基于以下4点:
1.依赖往往对应着Shuffle操作,需要在运行过程中将同一个父RDD的分区传入到不同的子RDD分区中,中间可能涉及多个节点之间的数据传输;而窄依赖的每个父RDD的分区只会传入到一个子RDD分区中,通常可以在一个节点内完成转换。
2.当RDD分区丢失时(某个节点故障),Spark会对数据进行重算
3.对于窄依赖,由于父RDD的一个分区只对应一个子RDD分区,这样只需要重算和子RDD分区对应的父RDD分区即可,所以这个重算对数据的利用率是100%的
4.对于依赖,重算的父RDD分区对应多个子RDD分区的,这样实际上父RDD中只有一部分的数据是被用于恢复这个丢失的子RDD分区的,另一部分对应子RDD的其他未丢失分区,这就造成了多余的计算;更一般的,宽依赖中子RDD分区通常来自多个父RDD分区,极端情况下,所有的父RDD分区都要进行重新计算。
区分这两种依赖很有用,首先,窄依赖允许在一个集群节点上以流水线的方式计算所有父分区,
而宽依赖则需要首先计算好所有父分区数据,然后在节点之间进行Shuffle,这与MapReduce类似。
第二窄依赖能够更有效地进行失效节点的恢复,即只需要重新计算丢失分区的父分区,而且不同节点之间可以并行计算;而对于一个宽依赖的Lineage图,单个节点失效可能导致这个RDD的所有祖先丢失部分分区,因而需要整体重新计算。
补充:
1.spark pipline的计算模式图
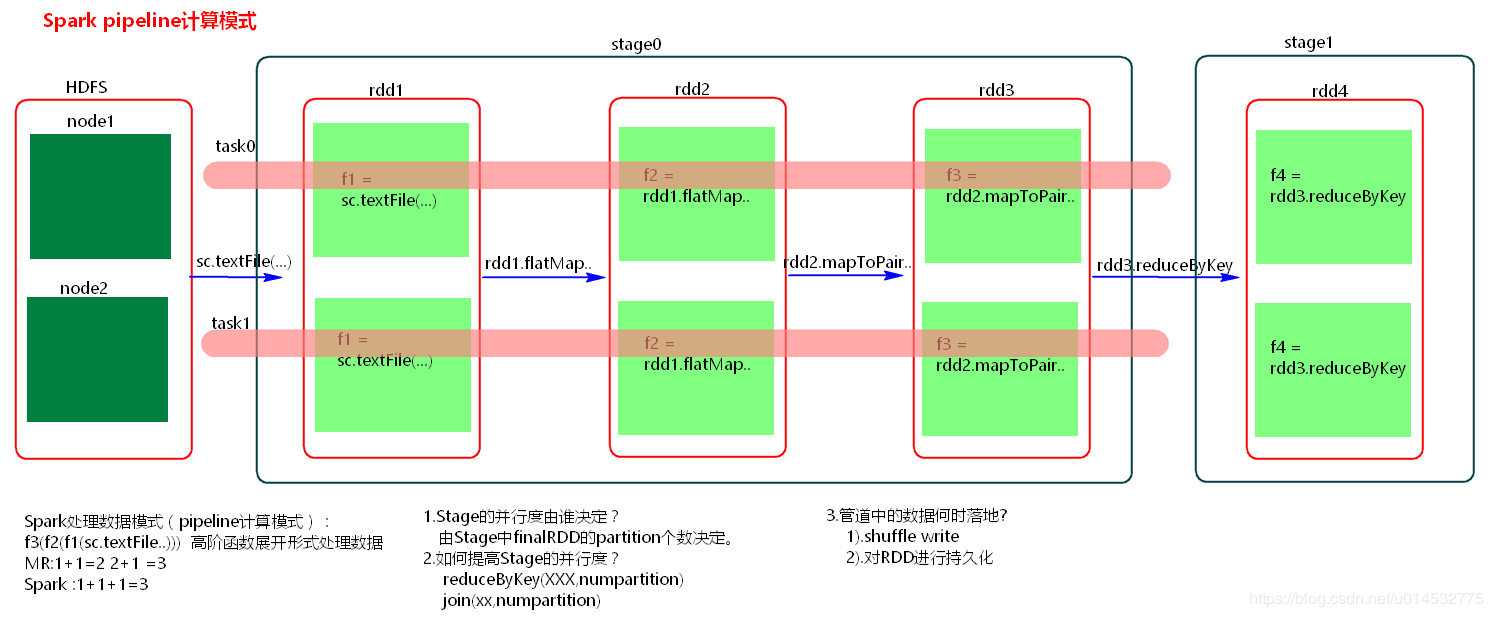
2.spark基于内存计算比mapreduce基于磁盘计算快的原因是:
比如都是从hdfs读取1G数据,spark一次只读取一条,将这一条数据一直进行计算(一条道走到黑),直到shuffle之前,将数据落到磁盘,这中间计算都是在内存中通过pipline,速度很快,一条数据计算完成之后,接着在进行第二条数据,依次类推,直到把1G数据都计算完保存在磁盘中,之后再读磁盘数据进行reduceBykey的操作;
而mapreduce的操作流程是一次性的将1G数据加载到内存中进行计算,每个流程计算完之后持久化到磁盘,下个流程开始时再从磁盘读数据再进行处理,等于每一步都要跟磁盘打交道,远比都在内存中处理的慢。
Executor的优点
与Hadoop MapReduce计算框架相比,Spark所采用的Executor有两个优点:
1、利用多线程来执行具体的任务(Hadoop MapReduce采用的是进程模型),减少任务的启动开销;
2、Executor中有一个BlockManager存储模块,会将内存和磁盘共同作为存储设备,当需要多轮迭代计算时,可以将中间结果存储到这个存储模块里,下次需要时,就可以直接读该存储模块里的数据,而不需要读写到HDFS等文件系统里,因而有效减少了IO开销;或者在交互式查询场景下,预先将表缓存到该存储系统上,从而可以提高读写IO性能。
Spark运行基本流程
Spark的基本运行流程如下:
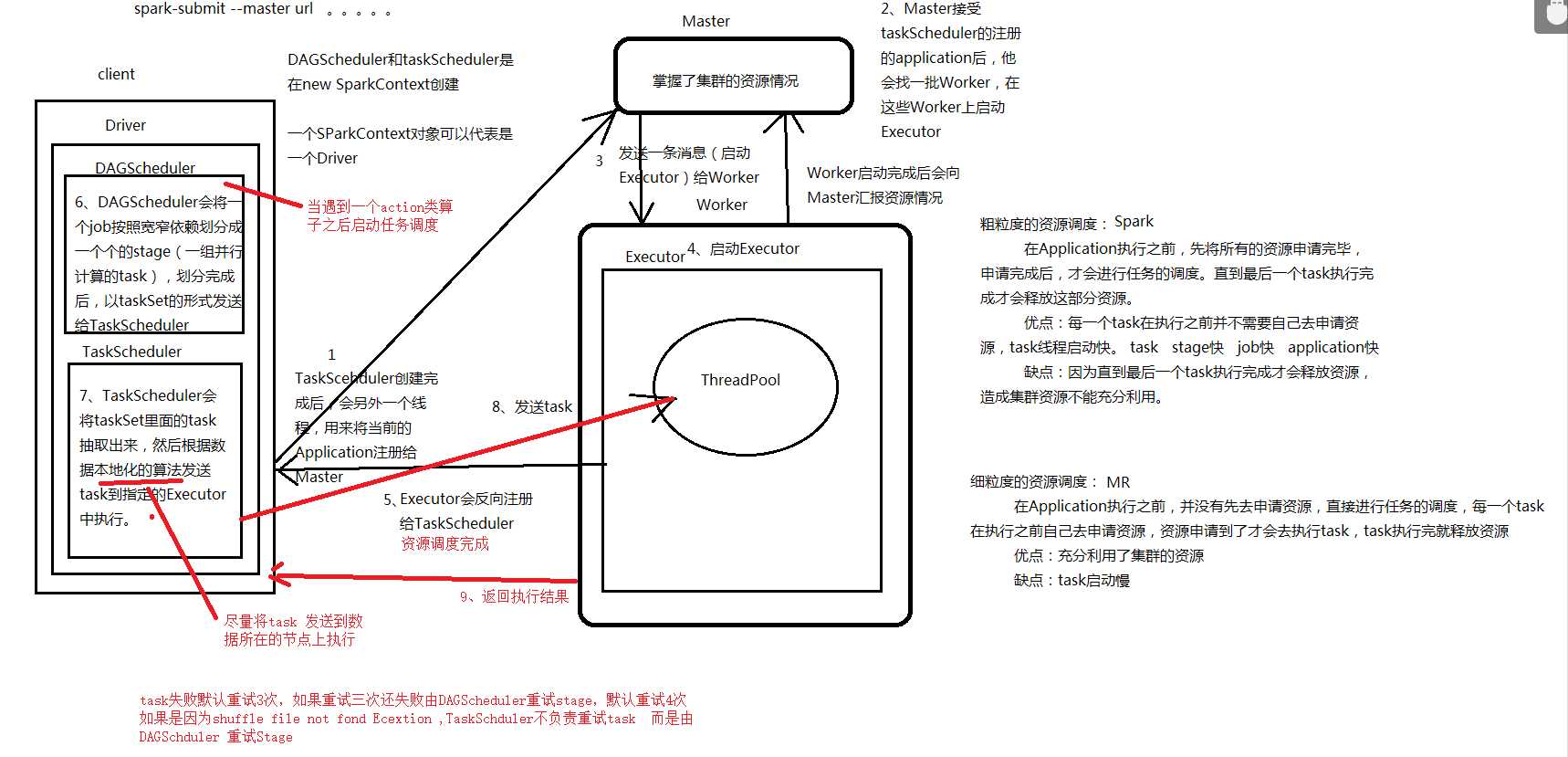
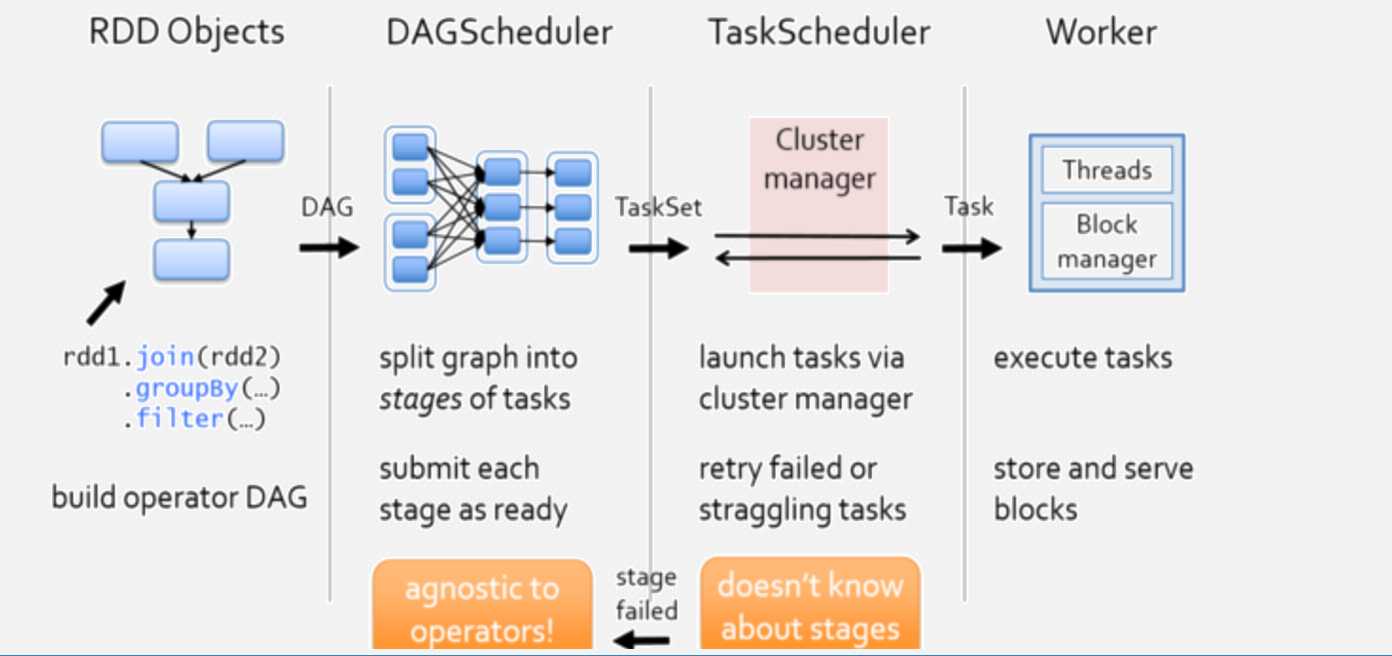
1、当一个Spark应用被提交时,首先需要为这个应用构建起基本的运行环境,即由任务控制节点(Driver)创建一个SparkContext,由SparkContext负责和资源管理器(Cluster Manager)的通信以及进行资源的申请、任务的分配和监控等。SparkContext会向资源管理器注册并申请运行Executor的资源;
2、资源管理器为Executor分配资源,并启动Executor进程,Executor运行情况将随着“心跳”发送到资源管理器上;
3、SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAG调度器(DAGScheduler)进行解析,将DAG图分解成多个“阶段”(每个阶段都是一个任务集),并且计算出各个阶段之间的依赖关系,然后把一个个“任务集”提交给底层的任务调度器(TaskScheduler)进行处理;Executor向SparkContext申请任务,任务调度器将任务分发给Executor运行,同时,SparkContext将应用程序代码发放给Executor;
4、任务在Executor上运行,把执行结果反馈给任务调度器,然后反馈给DAG调度器,运行完毕后写入数据并释放所有资源。
Spark运行架构的特点
Spark运行架构具有以下特点:
1、每个应用都有自己专属的Executor进程,并且该进程在应用运行期间一直驻留。Executor进程以多线程的方式运行任务,减少了多进程任务频繁的启动开销,使得任务执行变得非常高效和可靠;
2、Spark运行过程与资源管理器无关,只要能够获取Executor进程并保持通信即可;
3、Executor上有一个BlockManager存储模块,类似于键值存储系统(把内存和磁盘共同作为存储设备),在处理迭代计算任务时,不需要把中间结果写入到HDFS等文件系统,而是直接放在这个存储系统上,后续有需要时就可以直接读取;在交互式查询场景下,也可以把表提前缓存到这个存储系统上,提高读写IO性能;
4、任务采用了数据本地化和推测执行等优化机制。数据本地化是尽量将计算移到数据所在的节点上进行,即“计算向数据靠拢”,因为移动计算比移动数据所占的网络资源要少得多。而且,Spark采用了延时调度机制,可以在更大的程度上实现执行过程优化。比如,拥有数据的节点当前正被其他的任务占用,那么,在这种情况下是否需要将数据移动到其他的空闲节点呢?答案是不一定。因为,如果经过预测发现当前节点结束当前任务的时间要比移动数据的时间还要少,那么,调度就会等待,直到当前节点可用。
Spark的部署模式
Spark支持的三种典型集群部署方式,即standalone、Spark on Mesos和Spark on YARN;然后,介绍在企业中是如何具体部署和应用Spark框架的,在企业实际应用环境中,针对不同的应用场景,可以采用不同的部署应用方式,或者采用Spark完全替代原有的Hadoop架构,或者采用Spark和Hadoop一起部署的方式。
Spark三种部署方式
Spark应用程序在集群上部署运行时,可以由不同的组件为其提供资源管理调度服务(资源包括CPU、内存等)。比如,可以使用自带的独立集群管理器(standalone),或者使用YARN,也可以使用Mesos。因此,Spark包括三种不同类型的集群部署方式,包括standalone、Spark on Mesos和Spark on YARN。
1.standalone模式
与MapReduce1.0框架类似,Spark框架本身也自带了完整的资源调度管理服务,可以独立部署到一个集群中,而不需要依赖其他系统来为其提供资源管理调度服务。在架构的设计上,Spark与MapReduce1.0完全一致,都是由一个Master和若干个Slave构成,并且以槽(slot)作为资源分配单位。不同的是,Spark中的槽不再像MapReduce1.0那样分为Map 槽和Reduce槽,而是只设计了统一的一种槽提供给各种任务来使用。
2.Spark on Mesos模式
Mesos是一种资源调度管理框架,可以为运行在它上面的Spark提供服务。Spark on Mesos模式中,Spark程序所需要的各种资源,都由Mesos负责调度。由于Mesos和Spark存在一定的血缘关系,因此,Spark这个框架在进行设计开发的时候,就充分考虑到了对Mesos的充分支持,因此,相对而言,Spark运行在Mesos上,要比运行在YARN上更加灵活、自然。目前,Spark官方推荐采用这种模式,所以,许多公司在实际应用中也采用该模式。
3. Spark on YARN模式
Spark可运行于YARN之上,与Hadoop进行统一部署,即“Spark on YARN”,其架构如图所示,资源管理和调度依赖YARN,分布式存储则依赖HDFS。
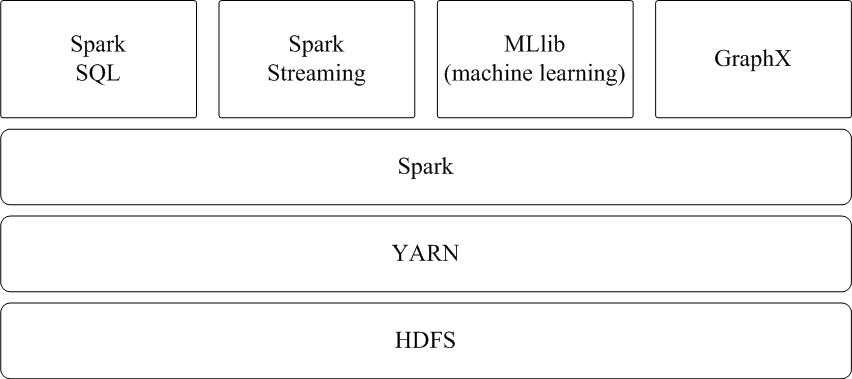
Hadoop和Spark的统一部署
一方面,由于Hadoop生态系统中的一些组件所实现的功能,目前还是无法由Spark取代的,比如,Storm可以实现毫秒级响应的流计算,但是,Spark则无法做到毫秒级响应。另一方面,企业中已经有许多现有的应用,都是基于现有的Hadoop组件开发的,完全转移到Spark上需要一定的成本。因此,在许多企业实际应用中,Hadoop和Spark的统一部署是一种比较现实合理的选择。
由于Hadoop MapReduce、HBase、Storm和Spark等,都可以运行在资源管理框架YARN之上,因此,可以在YARN之上进行统一部署。这些不同的计算框架统一运行在YARN中,可以带来如下好处:
计算资源按需伸缩;
不用负载应用混搭,集群利用率高;
共享底层存储,避免数据跨集群迁移。
标签:执行 进程 cli 其他 速度 mic graph cpu sch
原文地址:https://www.cnblogs.com/wyh-study/p/12294636.html