标签:info idt www enter 技术 期望 计算 and 不同
1.MDP / NFA :马尔可夫模型和不确定型有限状态机的不同
状态自动机:https://www.cnblogs.com/AndyEvans/p/10240790.html
MDP和NFA唯一相似的地方就是它们都有状态转移,抛掉这一点两者就八竿子打不着了。
2.MP -> MRP -> MDP

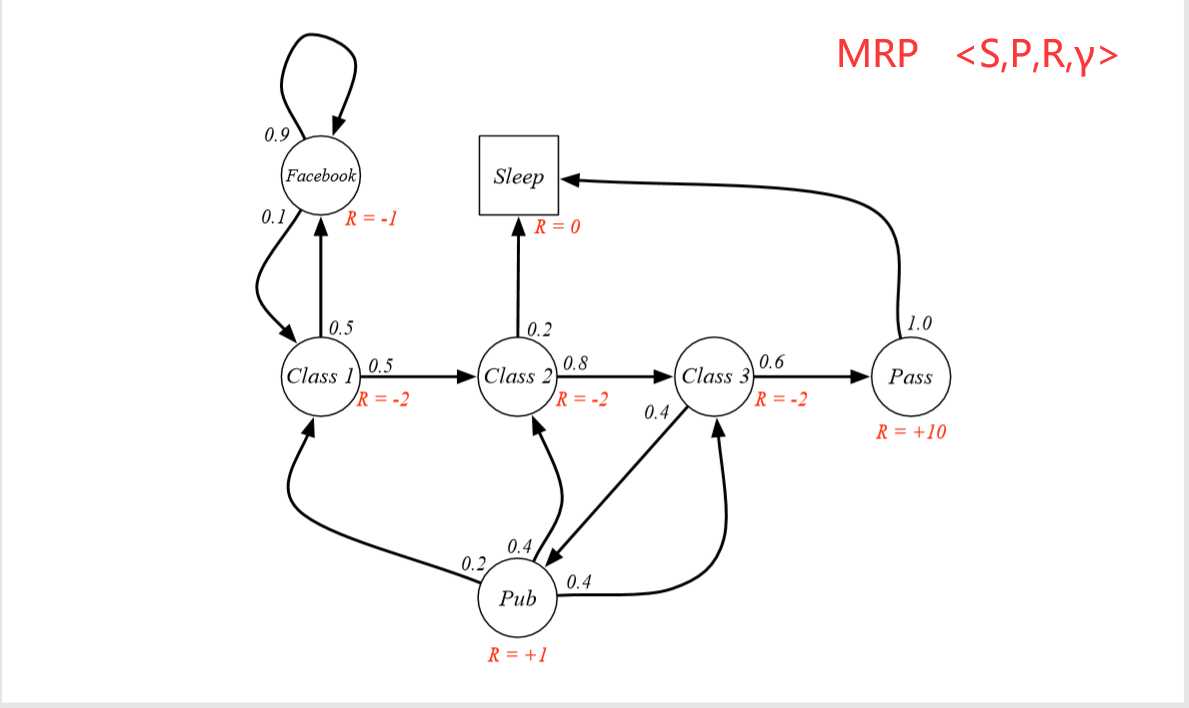

3.计算给定策略下的价值函数 / 贝尔曼期望方程
我们用贝尔曼期望方程求解在某个给定策略π和环境ENV下的价值函数:

具体解法是:(下面是对于V(s)的解法)

从而对于每一个特定的π,都能得到其对应的价值函数。所以我们可以有一组的{ (π1,value_function_of_π1) ,(π2,value_function_of_π2) ...... }
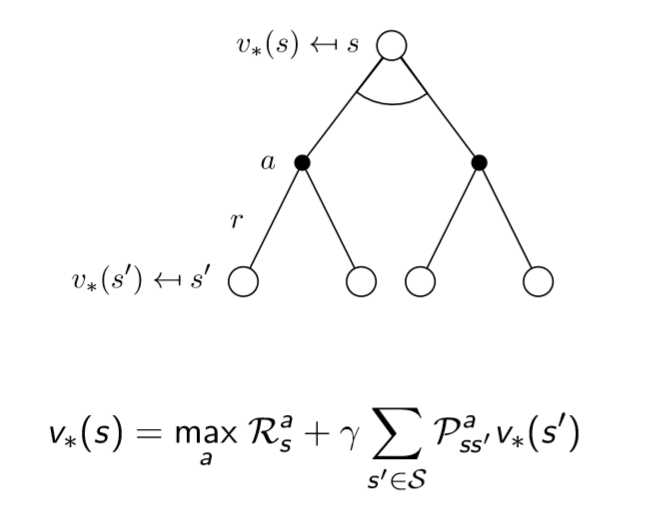
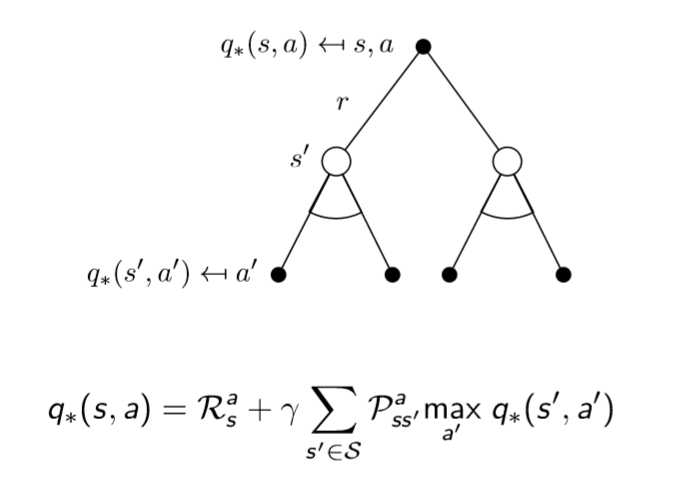
但是我们解决问题的目标是拿到最优的那组,其他的扔掉,解决方法就是使用贝尔曼最优方程确定最优价值函数。
4. 确定最优价值函数 /贝尔曼最优方程
我们的最优价值函数和最优策略是如下定义的,找最优价值函数的过程也就是找最优策略的过程
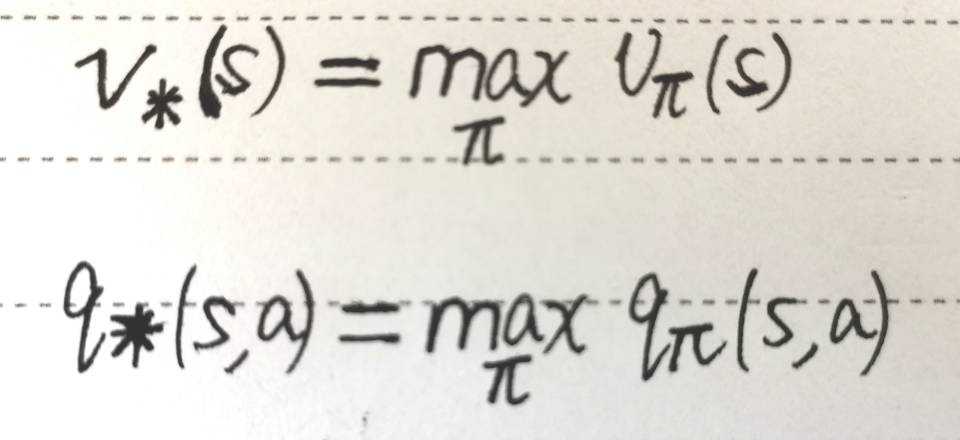
最优价值函数 ==== 一个MDP中的可能的最好的表现
解决一个MDP ==== 确定最优价值函数
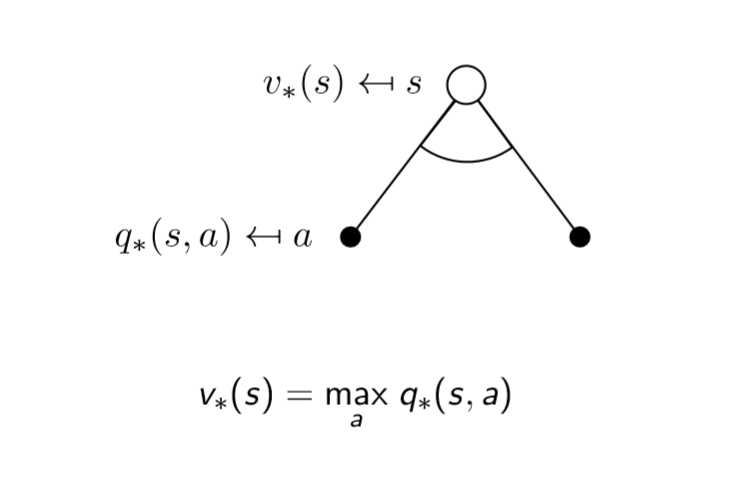
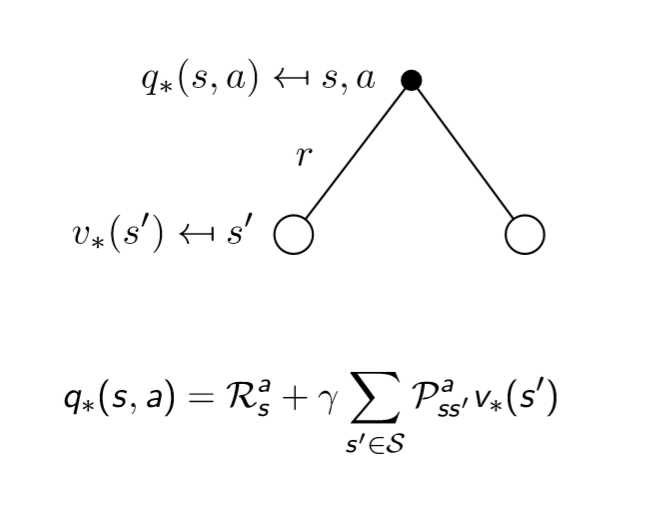
标签:info idt www enter 技术 期望 计算 and 不同
原文地址:https://www.cnblogs.com/dynmi/p/12294436.html