标签:div size detach learning 默认 randn 更新 准备 highlight
import torch
import matplotlib.pyplot as plt
learning_rate = 0.1
#准备数据 #y = 3x +0.8
x = torch.randn([500,1])
y_true = 3*x + 0.8
#计算预测值
w = torch.rand([],requires_grad=True)
b = torch.tensor(0,dtype=torch.float,requires_grad=True)
for i in range(50):
#梯度默认会累加,梯度手动清零
for j in [w,b]:
if j.grad is not None:
j.grad.data.zero_()
y_predict = x*w +b
#计算损失
loss = (y_predict-y_true).pow(2).mean()
loss.backward()
#更新参数
w.data = w.data - learning_rate * w.grad
b.data = b.data - learning_rate * b.grad
print(i,loss.item())
print(w.data,b.data)
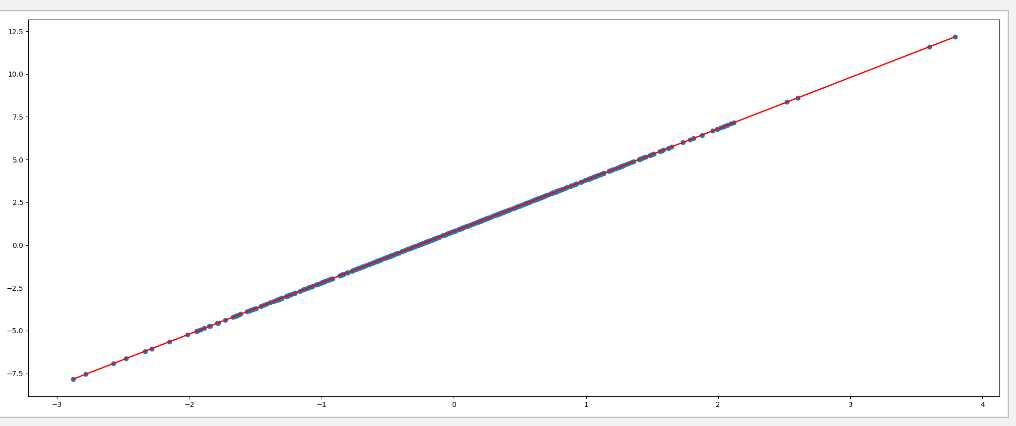
plt.figure(figsize=(20,8))
plt.scatter(x.numpy(),y_true.numpy())
y_predict = x*w + b
plt.plot(x.numpy(),y_predict.detach().numpy(),c="red")
plt.show()
标签:div size detach learning 默认 randn 更新 准备 highlight
原文地址:https://www.cnblogs.com/LiuXinyu12378/p/12299912.html