标签:速度 vma 概述 意义 lin ima 不能 一个 info
一.概述
word2vec用于处理文本字符串,类似的功能如sklearn的CountVectorizer,TfidfVectorizer,HashingVectorizer
CountVectorizer用每个词出现的次数做为向量的值,如特征空间内宫n个词,特征向量i中如果第j个word出现了n次则 S = [s00,……snn] sij=n
TfidfVectorizer用每个word的对tf-idf值表示第ij向量值
HashingVectorizer是使用word的hash值
以上方法虽然计算速度快,但是不能表示出词的意义如‘man‘,‘woman‘对于以上三个模型来说是完全不同的两个word,正确的向量空间子结构
Vking - Vqueen = Vman - Vwoman
Vpairs - Vfrance = Vgernab - Vberlin
二.NNLM
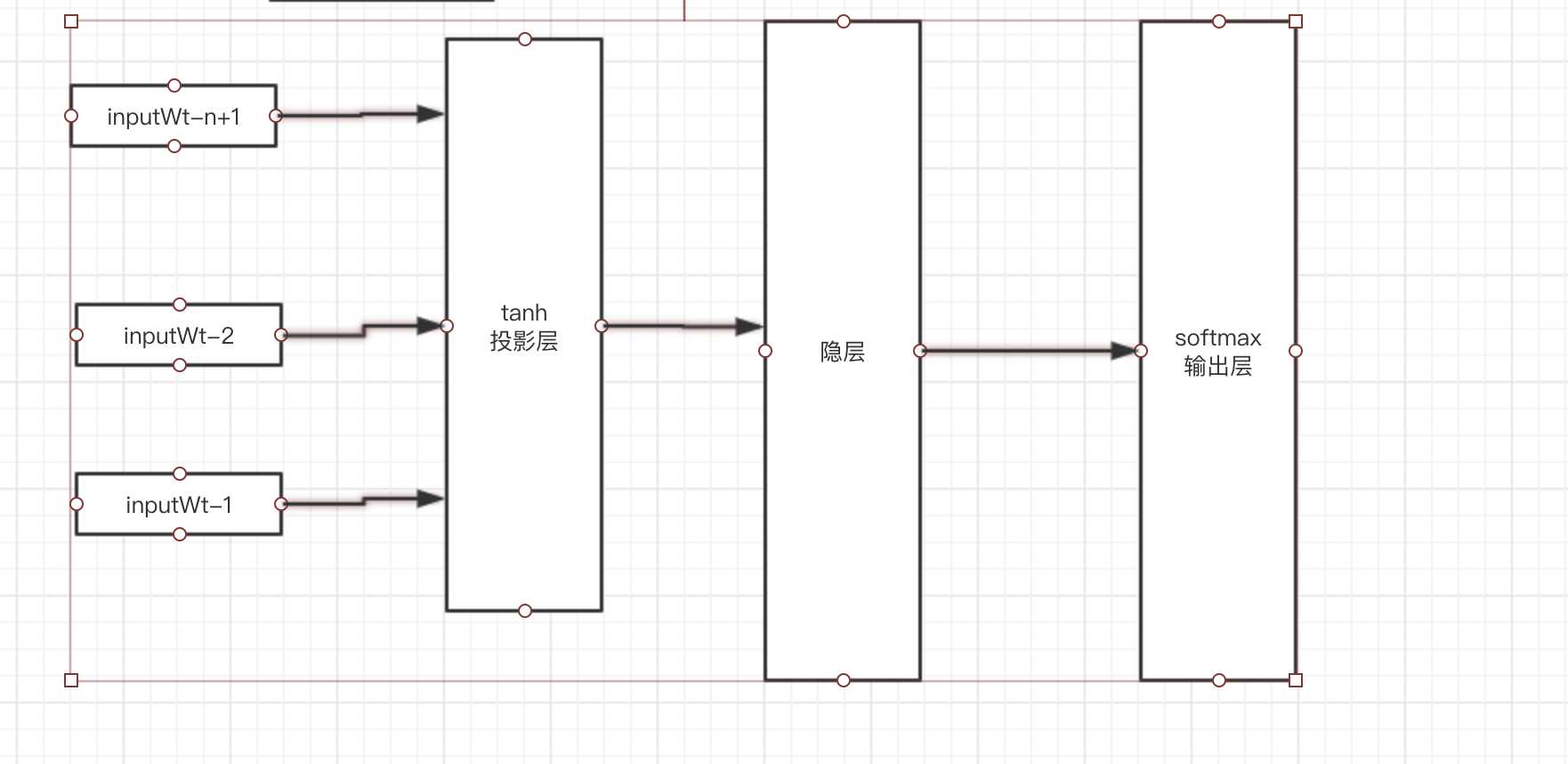
对于向量空间V,存在n个words
随机初始化稠密向量(layers*10W)V0,每个词用one-hot表示乘以V0得到一个NNLM的输入,
在投影层将相邻的三个向量拼接起来,每个向量没3*layers*1,激活函数为tanh
输出层使用softmax
输出层的最终目的为计算每三个相邻的word的下一个word的概率最高。
1.CBOW(连续词袋)
无隐层
使用双向上下文窗口
上下文词序无关
投影层简化为求和
使用上下文推断中间的词
2.skip-Gram
无隐层
投影层也可省略
每个词向量作为log-linear模型的输入
使用中间的词推断上下文
标签:速度 vma 概述 意义 lin ima 不能 一个 info
原文地址:https://www.cnblogs.com/yangyang12138/p/12306151.html