标签:bsp review 信息 假设 icc 需要 长度 preview static
下图展示了如何基于循环神经网络实现语言模型。目的是基于当前的输入与过去的输入序列,预测序列的下一个字符。循环神经网络引入一个隐藏变量??,用????表示??在时间步??的值。????的计算基于????和????−1,可以认为????记录了到当前字符为止的序列信息,利用????对序列的下一个字符进行预测。
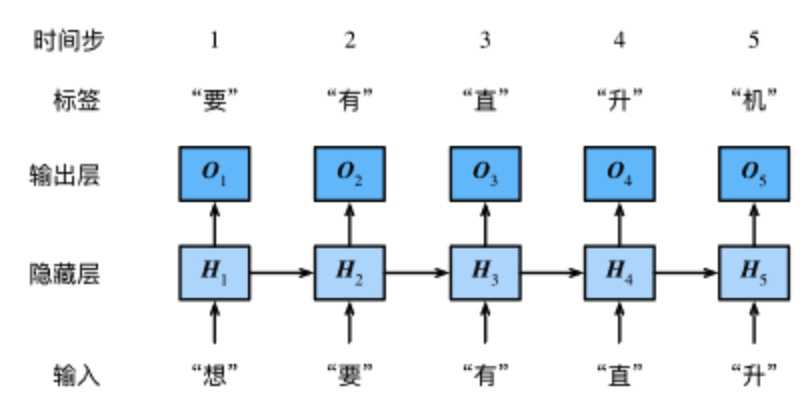
先看循环神经网络的具体构造。假????∈???×??是时间步??的小批量输入,????∈???×?是该时间步的隐藏变量,则:
????=??(?????????+????−1????+???).

需要将字符表示成向量,这里采用one-hot向量。假设词典大小是??,每次字符对应一个从0到??−1的唯一的索引,则该字符的向量是一个长度为??的向量,若字符的索引是??,则该向量的第??个位置为1,其他位置为0。下面分别展示了索引为0和2的one-hot向量,向量长度等于词典大小。
循环神经网络中较容易出现梯度衰减或梯度爆炸,这会导致网络几乎无法训练。裁剪梯度(clip gradient)是一种应对梯度爆炸的方法。假设我们把所有模型参数的梯度拼接成一个向量 ??,并设裁剪的阈值是??。裁剪后的梯度
![]()
的??2范数不超过??。
以下函数基于前缀prefix(含有数个字符的字符串)来预测接下来的num_chars个字符。这个函数稍显复杂,其中我们将循环神经单元rnn设置成了函数参数,这样在后面小节介绍其他循环神经网络时能重复使用这个函数。
我们通常使用困惑度(perplexity)来评价语言模型的好坏。回忆一下“softmax回归”一节中交叉熵损失函数的定义。困惑度是对交叉熵损失函数做指数运算后得到的值。特别地,
显然,任何一个有效模型的困惑度必须小于类别个数。在本例中,困惑度必须小于词典大小vocab_size。
跟之前章节的模型训练函数相比,这里的模型训练函数有以下几点不同:
标签:bsp review 信息 假设 icc 需要 长度 preview static
原文地址:https://www.cnblogs.com/jaww/p/12308158.html