标签:image 最优 alt 复杂 size font || mic iso
前面介绍了三种采样求均值的算法
——MC
——TD
——TD(lamda)
下面我们基于这几种方法来 迭代优化agent
传统的强化学习算法
||
ν
ν
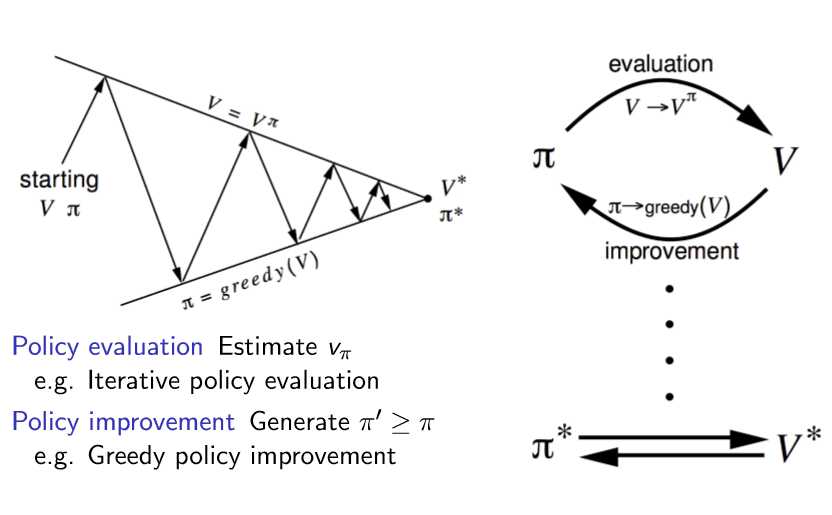
已经知道完整MDP——使用价值函数V(s)
没有给出完整MDP——使用价值函数Q(s,a)
可见我们的目标就是确定下来最优策略和最优价值函数
|
|——有完整MDP && 用DP解决复杂度较低
| ====》 使用贝尔曼方程和贝尔曼最优方程求解
|——没有完整MDP(ENV未知) or 知道MDP但是硬解MDP问题复杂度太高
| ====》 policy evaluation使用采样求均值的方法
| |—— ON-POLICY MC
| |—— ON-POLICY TD
| |____ OFF-POLICY TD
on policy :基于策略A采样获取episode,并且被迭代优化的策略也是A
off policy :基于策略A采样获取episode,而被迭代优化的策略是B

标签:image 最优 alt 复杂 size font || mic iso
原文地址:https://www.cnblogs.com/dynmi/p/12308173.html