标签:最小 api 文件复制 XML enc 存储管理 内存缓存 ash linux
1、HDFS系统的特点
1.1、特点
- 廉价且稳定的存储解决方案
- 高吞吐量的文件系统
- 超大文件的支持
- 简单一致性的文件系统
- 流式的数据访问方式
- 低时间延迟的数据访问
- 大量的小文件
- 多用户写入,任意修改文件
1.2、不适合使用HDFS的场景
- 低时间延迟的数据访问
- 大量的小文件
- 多用户写入,任意修改文件
2、HDFS文件系统
2.1 HDFS系统组成
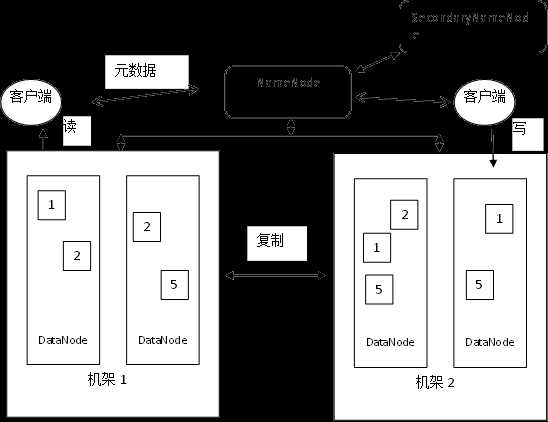
- NameNode:是HDFS系统中的管理节点,它管理文件系统的命名空间、记录每个文件数据块在DataNode上的位置和副本信息、协调客户端对文件的访问、记录命名空间内的改动和空间本身属性的改动。
- NameNode使用事务日志(EditsLog)记录HDFS元数据的变化。使用映像文件存储文件系统的命名空间,包括文件映射,文件属性等。
- DataNode节点是HDFS系统中保存数据的节点,负责所在物理节点的存储管理,一次写入,多次读取。文件由数据块组成,默认的块大小是128MB,数据块以冗余备份的形式分布在不同机架的不同机器上,DataNode定期向NameNode提供其保存的数据块的列表,以便于客户端在获取文件元数据后直接在DataNode上进行读写。
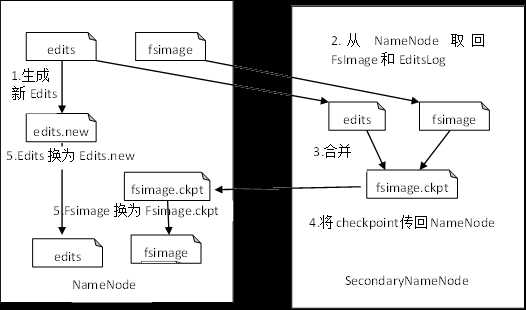
- SecondaryNameNode:在Hadoop中只有一个NameNode,所以存在着单点问题,即当NameNode节点宕机时,整个系统就瘫痪了。为了解决这个问题,在Hadoop中增加了一个SecondaryNameNode节点,它一般运行在单独的计算机上,定期从NameNode节点获取数据,形成NameNode的备份,一旦NameNode出现问题,SecondaryNameNode便可以顶替NameNode。Hadoop1.X中没有真正解决单点问题,到2.X后解决了系统的单点问题,提高了系统的可用性
- 客户端:客户端是Hadoop集群的使用者,他通过HDFS的Shell和API对系统中的文件进行操作。
- 机架(Rack)是容纳组成集群的普通商用计算机(节点)的架子,各节点被分到不同的机架内,这样做的目的是为了管理和施工的需要,也是为了防灾容错的需要
- 数据块:在HDFS中也有数据块的概念,不过要大得多,默认是128MB,与磁盘数据块类似,数据块(Chunk)是Hadoop处理数据的最小单位,一个Hadoop文件被分成若干数据块,根据Hadoop数据管理的策略,数据块被放置在不同的数据节点(DataNode)中,当数据块的副本数小于规定的份数时,Hadoop系统的错误检测与自动恢复技术就会自动把数据块的副本数恢复到正常水平。
2.2 HDFS文件数据的存储组织
- NameNode目录结构
- NameNode使用Linux操作系统的文件系统来存储数据,保存数据的文件夹位置由{dfs.name.dir}来决定,如果配置文件中未设置该项,则文件夹放在Hadoop安装目录下的/home/hadoop/hdfs/name,使用下列命令可列出目录结构:tree –L 2
- DataNode目录结构
- DataNode使用Linux操作系统的文件系统来存储数据,保存数据的文件夹位置由{dfs.data.dir}来决定,如果配置文件中未设置该项,则文件夹放在Hadoop安装目录下的/home/hadoop/hdfs/data
2.3元数据及其备份机制
- Hadoop是典型的主/从架构,集群中有一个NameNode和多个DataNode,数据以数据块的形式保存在DataNode中,在NameNode中则管理着文件系统的命名空间。NameNode也保存着每个数据块的所在节点的信息。这些文件块的映射和文件系统的配置信息都保存在一个叫fsimage的映像文件中,事务日志文件(EditsLog)则记录着对文件系统的元数据的改变。
- Hadoop采取了两种机制来保护NameNode的安全:
- 元数据的持久化
- 增加一个辅助的SecondaryNameNode
- SecondaryNameNode工作原理
2.4数据块备份
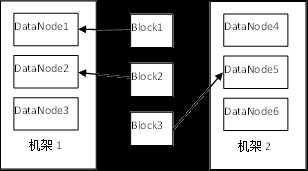
- HDFS能够存储管理超大文件是因为它把大文件存储为一系列数据块(Block),数据块默认大小为128MB,为了容错,数据块被复制多份分布到集群的不同节点上,当DataNode启动时,它会在内存中形成一个数据块与文件的对应关系列表,DataNode周期性地把这个列表发送给NameNode,这就是我们所说的心跳机制,NameNode根据心跳信息知道集群中哪个DataNode存活着,哪个DataNode已经宕掉,当下一次进行文件读写时,不再给宕掉的DataNode节点分配任何新的I/O请求。这样,存储在宕掉的节点中的数据块因宕机而变得不可用,某些数据块的副本数因此而下降到指定值以下,NameNode会不断进行错误检测,检查这些需要复制的数据块,在需要的时候启动自动恢复机制自动地把数据块的副本数恢复到正常水平。
- 数据块备份规则
2.5数据的读取过程
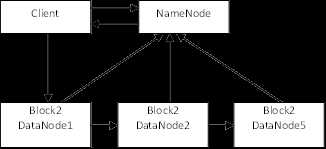
客户端将要读取的文件路径发送给namenode,namenode获取文件的元信息(主要是block的存放位置信息)返回给客户端,客户端根据返回的信息找到相应datanode逐个获取文件的block并在客户端本地进行数据追加合并从而获得整个文件。
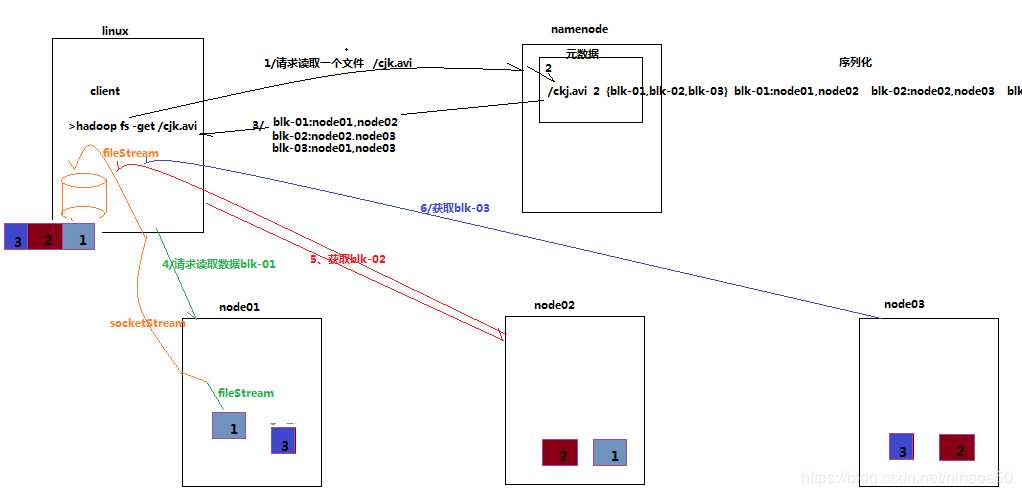
详细步骤解析
- 跟namenode通信查询元数据,namenode找到文件块所在的datanode服务器
- 挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流
- datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
- 客户端以packet为单位接收,现在本地缓存,然后写入目标文件
2.6数据的写入过程
客户端要向HDFS写数据,首先要跟namenode通信以确认可以写文件并获得接收文件block的datanode,然后,客户端按顺序将文件逐个block传递给相应datanode,并由接收到block的datanode负责向其他datanode复制block的副本。
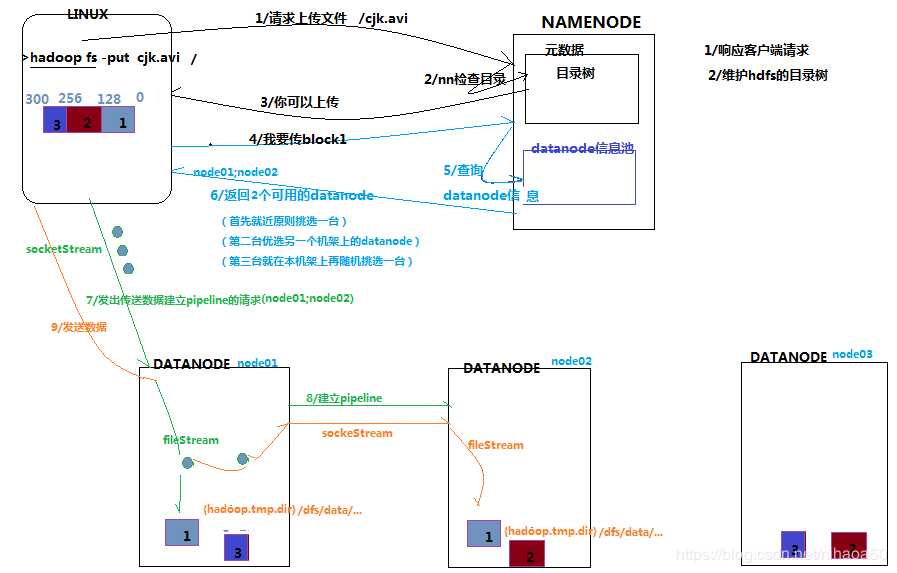
详细步骤解析
- 根namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
- namenode返回是否可以上传
- client请求第一个 block该传输到哪些datanode服务器上
- namenode返回3个datanode服务器ABC
- client请求3台dn中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将真个pipeline建立完成,逐级返回客户端
- client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答
- 当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。
3、HDFS Shell命令
3.1 Shell命令
3.1.1.cat命令
- 用法:hadoop fs -cat URI [URI …]
- 将路径指定文件的内容输出到stdout。
- 示例:
- hadoop fs -cat /user/input.txt
3.1.2. chgrp命令
- 用法:hadoop fs -chgrp [-R] GROUP URI [URI …]
- 改变文件所属的组。使用-R将使改变在目录结构下递归进行。命令的使用者必须是文件的所有者或者超级用户。
- 示例:
- hadoop fs -chgrp group1 /hadoop/hadoopfile
3.1.3.chmod命令
- 用法:hadoop fs -chmod [-R] <MODE[,MODE]... | OCTALMODE> URI [URI …]
- 改变文件的权限。使用-R将使改变在目录结构下递归进行。命令的使用者必须是文件的所有者或者超级用户。
- 示例:
- hadoop fs -chmod 764 /hadoop/hadoopfile
3.1.4. chown命令
- 用法:hadoop fs -chown [-R] [OWNER][:[GROUP]] URI [URI ]
- 改变文件的拥有者。使用-R将使改变在目录结构下递归进行。命令的使用者必须是超级用户。
- 示例:
- hadoop fs -chown user1 /hadoop/hadoopfile
3.1.5. copyFromLocal命令
- 用法:hadoop fs -copyFromLocal <localsrc> URI
- 从本地文件复制到HDFS文件系统中。
- 示例:
- hadoop fs -copyFromLocal /home/hadoop/stdrj49.flv /user
3.1.6. copyToLocal
- 用法:hadoop fs -copyToLocal [-ignorecrc] [-crc] URI <localdst>
- 从HDFS复制文件到本地,-ignorecrc选项可忽略文件校验,-crc选项进行校验并复制校验文件。
- 示例:
- hadoop fs -copyToLocal /user/hadoop/stdrj.flv /home/hadoop/
3.1.7. cp命令
- 用法:hadoop fs -cp URI [URI …] <dest>
- 将文件从源路径复制到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录。
- 示例:
- hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2
- hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2 /user/hadoop/dir
3.1.8. du命令
- 用法:hadoop fs -du URI [URI …]
- 显示目录中所有文件的大小,或者当只指定一个文件时,显示此文件的大小。
- 示例:
- hadoop fs -du /user/hadoop/
3.1.9. dus命令
- 用法:hadoop fs -dus <args>
- 显示文件的大小,与du类似,区别在于对目录操作时显示的是目录下所有文件大小之和
- 示例:
- hadoop fs -dus /user
3.1.10. expunge命令
- 用法:hadoop fs -expunge
- 清空回收站。
3.1.11. get命令
- 用法:hadoop fs -get [-ignorecrc] [-crc] <src> <localdst>
- 复制文件到本地文件系统。可用-ignorecrc选项复制CRC校验失败的文件。使用-crc选项复制文件以及CRC信息。
- 示例:
- hadoop fs -get /user/input.txt /home/hadoop
3.1.12. getmerge命令
- 用法:hadoop fs -getmerge <src> <localdst> [addnl]
- 接受一个源目录和一个目标文件作为输入,并且将源目录中所有的文件连接成本地目标文件。addnl是可选的,用于指定在每个文件结尾添加一个换行符。
- 示例:
- hadoop fs -getmerge /user /home/hadoop/test.txt
- 将HDFS中/user目录下的文件合并,输出到本地文件系统,保存为/home/hadoop/test.txt
3.1.13. ls命令
- 用法:hadoop fs -ls <args>
- 如果是文件,则按照如下格式返回文件信息:
- 文件名 <副本数> 文件大小 修改日期 修改时间 权限 用户ID 组ID
- 如果是目录,则返回它直接子文件的一个列表,就像在Unix中一样。目录返回列表的信息如下:
- 目录名 <dir> 修改日期 修改时间 权限 用户ID 组ID
- 示例:
- hadoop fs -ls /user/input.txt 显示/user/input.txt文件信息
- hadoop fs -ls /user/hadoop/ 显示/user/hadoop/目录下的文件
3.1.14. lsr命令
- 用法:hadoop fs -lsr <args>
- ls命令的递归版本。类似于Unix中的ls -R。
- 示例:
- hadoop fs -lsr /
3.1.15. mkdir命令
- 用法:hadoop fs -mkdir <paths>
- 接受路径指定的URI作为参数,创建这些目录。其行为类似于Unix的mkdir -p,它会创建路径中的各级父目录。
- 示例:
- hadoop fs -mkdir /user/hadoop/dir1 /user/hadoop/dir2
3.1.16. movefromLocal命令
- 用法:hadoop fs -moveFromLocal <src> <dst>
- 将文件或目录从本地文件系统移动到HDFS。
- 示例:
- hadoop@master:~$ hadoop fs -moveFromLocal test.txt /user/hadoop
- hadoop fs -moveFromLocal /home/hadoop/aa.txt /user/hadoop
3.1.17. mv命令
- 用法:hadoop fs -mv URI [URI …] <dest>
- 将文件从源路径移动到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录。不允许在不同的文件系统间移动文件。
- 示例:
- hadoop fs -mv /user/hadoop/aa.txt /user/hadoop/bb.txt
3.1.18. put命令
- 用法:hadoop fs -put <localsrc> ... <dst>
- 从本地文件系统中复制单个或多个源路径到目标文件系统。也支持从标准输入中读取输入写入到目标文件系统中。
- 示例:
- hadoop fs -put /home/hadoop/aa.txt /user/hadoop/
- hadoop fs -put /home/hadoop/ aa.txt /user/hadoop/aa2.txt
3.1.19. rm命令
- 用法:hadoop fs -rm URI [URI …]
- 删除指定的文件。只删除非空目录和文件。
- 示例:
- hadoop fs -rm /user/hadoop/test.txt
3.1.20. rmr命令
- 用法:hadoop fs -rmr URI [URI …]
- delete的递归版本。
- 示例:
- hadoop fs -rmr /usr
3.1.21. setrep命令
- 用法:hadoop fs -setrep [-R] <path>
- 改变一个文件的副本系数。-R选项用于递归改变目录下所有文件的副本系数。
- 示例:
- hadoop fs -setrep -w 3 -R /user/hadoop/dir1
3.1.22. stat命令
- 用法:hadoop fs -stat URI [URI …]
- 返回指定路径的统计信息。
- 示例:
- hadoop fs -stat /user/hadoop/dir1
3.1.23. tail命令
- 用法:hadoop fs -tail [-f] URI
- 将文件尾部1K字节的内容输出到stdout。支持-f选项,行为和Unix中一致。
- 示例:
- hadoop fs -tail /user/input.txt
3.1.24. test命令
- 用法:hadoop fs -test -[ezd] URI
- 选项:
- -e 检查文件是否存在。如果存在则返回0。
- -z 检查文件是否是0字节。如果是则返回0。
- -d 如果路径是个目录,则返回1,否则返回0。
- 示例:
- hadoop fs -test -e /usr/hadoop/file1
3.1.25. text命令
- 用法:hadoop fs -text <src>
- 将源文件输出为文本格式。允许的格式是zip和TextRecordInputStream
- 示例:
- hadoop fs -text /user/hadoop/cc.txt
3.1.26. touchz命令
- 用法:hadoop fs -touchz URI [URI …]
- 创建一个0字节的空文件。
- 示例:
- hadoop fs -touchz /user/hadoop/empty
4、HDFS的高可用性
4.1 高可用性原理
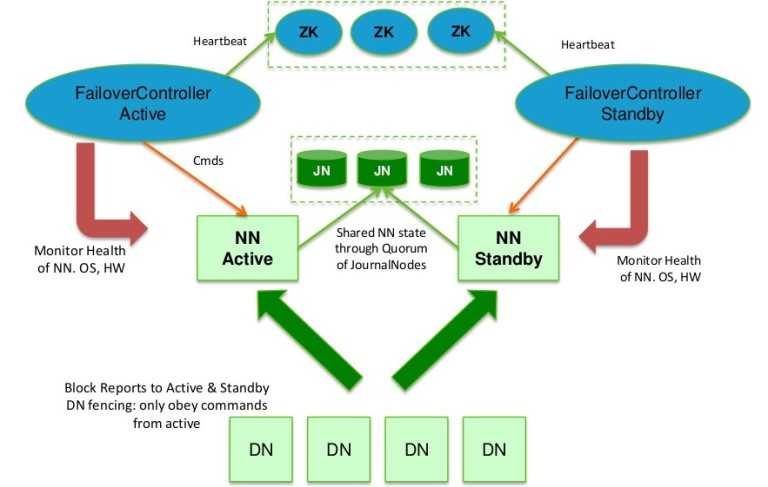
4.1 高可用性
- 可用性是衡量一个系统对外提供服务质量的一个重要指标,通常用正常服务时间与总运行时间的百分比来表示,可用性计算公式如下所示:
- 影响Hadoop系统可用性的因素有两种:
- 因软硬件等各种因素导致NameNode所在的服务器宕机,使整个集群停止工作。
- 因为NameNode节点软硬需要升级,导致系统在短时间内不可用。
4.2 元数据的备份
为了保护NameNode节点上元数据的安全,可以在Hadoop配置文件中进行设置把元数据保存到多个路径下。在配置文件hdfs-site.xml中有dfs.name.dir参数指定文件系统存放的路径。
下面是dfs.name.dir参数配置示例:
<property>
<name>dfs.name.dir</name>
<value>/home/hadoop/hadoop/name,/mnt/namenode-backup</value>
<final>true</final>
</property>
4.3 使用SecondaryName进行备份
SecondaryNameNode的作用是定期为NameNode创建检查点,备份元数据(fsimage文件)和元数据操作日志(edits)。
当NameNode宕机时,可以利用SecondaryNameNode节点中的数据恢复NameNode的数据,或直接使用SecondaryNameNode代替NameNode,恢复集群的正常运行
4.4 Backup Node备份
引入了一种新的节点BackupNode,BackupNode不仅执行了检查点的功能,还在内存中保存了一份与NameNode一致的元数据。BackupNode只需要把从NameNode中复制过来的Edits文件应用到内存元数据上,即可获得最新的元数据信息。
5、HDFS中小文件存储问题
5.1 HDFS面临的问题
- 文件系统的效率低下。
- 集群内部节点内存占用率过高。
- 浪费大量的存储空间。
- 文件归档技术
- SequenceFile格式
- CombineFileInputFormat
HDFS文件系统
标签:最小 api 文件复制 XML enc 存储管理 内存缓存 ash linux
原文地址:https://www.cnblogs.com/jiajunplyh/p/12310252.html