标签:类型 发布 article dia compute 斯坦福 var ted 补充
https://adeshpande3.github.io/adeshpande3.github.io/
https://blog.csdn.net/weiwei9363/article/details/79112872
https://blog.csdn.net/and_w/article/details/70336506
https://hackernoon.com/visualizing-parts-of-convolutional-neural-networks-using-keras-and-cats-5cc01b214e59
https://keras-cn.readthedocs.io/en/latest/other/visualization/
https://blog.keras.io/category/demo.html
https://stackoverflow.com/questions/39280813/visualization-of-convolutional-layer-in-keras-model
http://nbviewer.jupyter.org/github/BVLC/caffe/blob/master/examples/00-classification.ipynb
https://blog.csdn.net/thystar/article/details/50662972
原始网页:Visualizing parts of Convolutional Neural Networks using Keras and Cats
翻译:卷积神经网络实战(可视化部分)——使用keras识别猫咪
It is well known that convolutional neural networks (CNNs or ConvNets) have been the source of many major breakthroughs in the field of Deep learning in the last few years, but they are rather unintuitive to reason about for most people. I’ve always wanted to break down the parts of a ConvNet and see what an image looks like after each stage, and in this post I do just that!
在近些年,深度学习领域的卷积神经网络(CNNs或ConvNets)在各行各业为我们解决了大量的实际问题。但是对于大多数人来说,CNN仿佛戴上了神秘的面纱。我经常会想,要是能将神经网络的过程分解,看一看每一个步骤是什么样的结果该有多好!这也就是这篇博客存在的意义。
First off, what are ConvNets good at? ConvNets are used primarily to look for patterns in an image. You did that by convoluting over an image and looking for patterns. In the first few layers of CNNs the network can identify lines and corners, but we can then pass these patterns down through our neural net and start recognizing more complex features as we get deeper. This property makes CNNs really good at identifying objects in images.
首先,我们要了解一下卷积神经网络擅长什么。CNN主要被用来找寻图片中的模式。这个过程主要有两个步骤,首先要对图片做卷积,然后找寻模式。在神经网络中,前几层是用来寻找边界和角,随着层数的增加,我们就能识别更加复杂的特征。这个性质让CNN非常擅长识别图片中的物体。
A CNN is a neural network that typically contains several types of layers, one of which is a convolutional layer, as well as pooling, and activation layers.
CNN是一种特殊的神经网络,它包含卷积层、池化层和激活层。
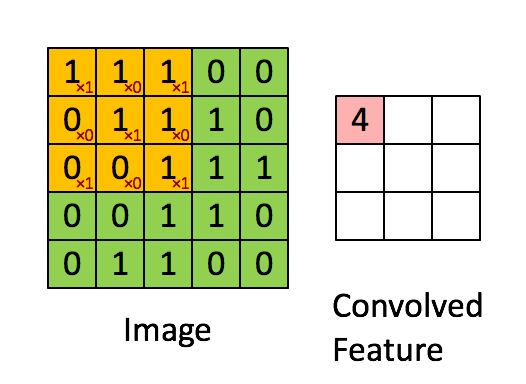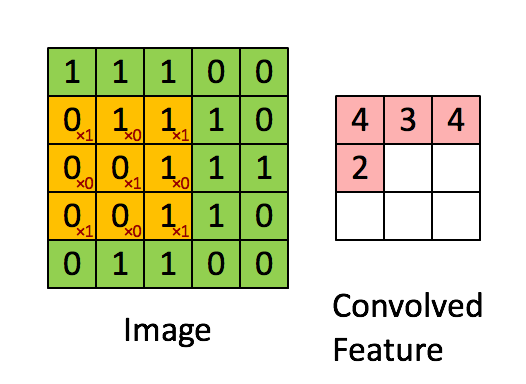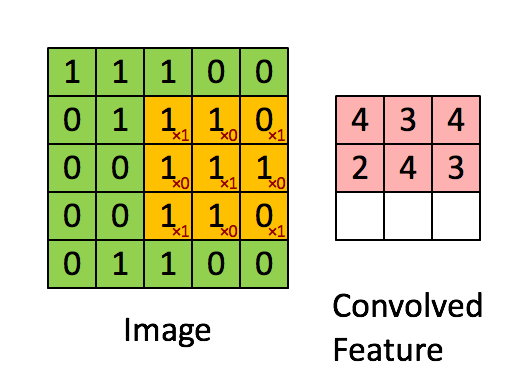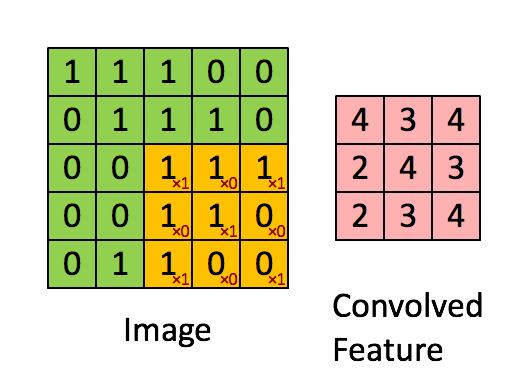
To understand what a CNN is, you need to understand how convolutions work. Imagine you have an image represented as a 5x5 matrix of values, and you take a 3x3 matrix and slide that 3x3 window around the image. At each position the 3x3 visits, you matrix multiply the values of your 3x3 window by the values in the image that are currently being covered by the window. This results in a single number the represents all the values in that window of the image. Here’s a pretty gif for clarity:
要想了解什么是卷积神经网络,你首先要知道卷积是怎么工作的。想象你有一个5*5矩阵表示的图片,然后你用一个3*3的矩阵在图片中滑动。每当3*3矩阵经过的点就用原矩阵中被覆盖的矩阵和这个矩阵相乘。这样一来,我们可以使用一个值来表示当前窗口中的所有点。下面是一个过程的动图:
As you can see, each item in the feature matrix corresponds to a section of the image. Note that the value of the kernel matrix is the red number in the corner of the gif.
正如你所见的那样,特征矩阵中的每一个项都和原图中的一个区域相关。
The “window” that moves over the image is called a kernel. Kernels are typically square and 3x3 is a fairly common kernel size for small-ish images. The distance the window moves each time is called the stride. Additionally of note, images are sometimes padded with zeros around the perimeter when performing convolutions, which dampens the value of the convolutions around the edges of the image (the idea being typically the center of photos matter more).
在图中像窗口一样移动的叫做核。核一般都是方阵,对于小图片来说,一般选用3*3的矩阵就可以了。每次窗口移动的距离叫做步长。值得注意的是,一些图片在边界会被填充零,如果直接进行卷积运算的话会导致边界处的数据变小(当然图片中间的数据更重要)。
The goal of a convolutional layer is filtering. As we move over an image we effective check for patterns in that section of the image. This works because of filters, stacks of weights represented as a vector, which are multiplied by the values outputed by the convolution.When training an image, these weights change, and so when it is time to evaluate an image, these weights return high values if it thinks it is seeing a pattern it has seen before. The combinations of high weights from various filters let the network predict the content of an image. This is why in CNN architecture diagrams, the convolution step is represented by a box, not by a rectangle; the third dimension represents the filters.
卷积层的主要目的是滤波。当我们在图片上操作时,我们可以很容易得检查出那部分的模式,这是由于我们使用了滤波,我们用权重向量乘以卷积之后的输出。当训练一张图片时,这些权重会不断改变,而且当遇到之前见过的模式时,相应的权值会提高。来自各种滤波器的高权重的组合让网络预测图像的内容的能力。 这就是为什么在CNN架构图中,卷积步骤由一个框而不是一个矩形表示; 第三维代表滤波器。
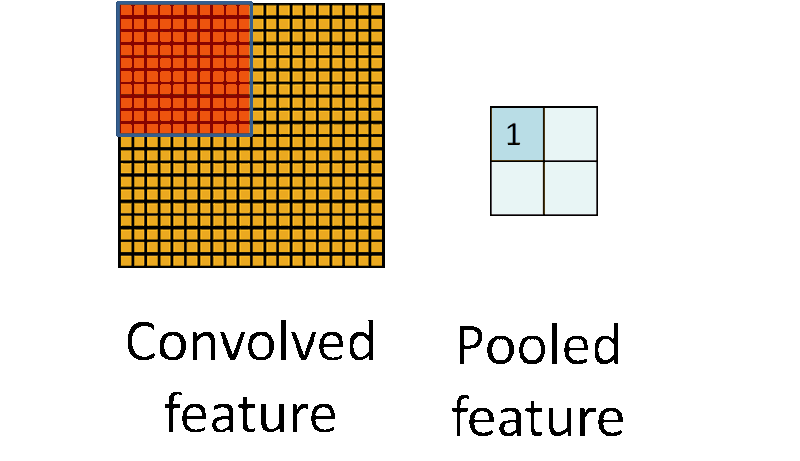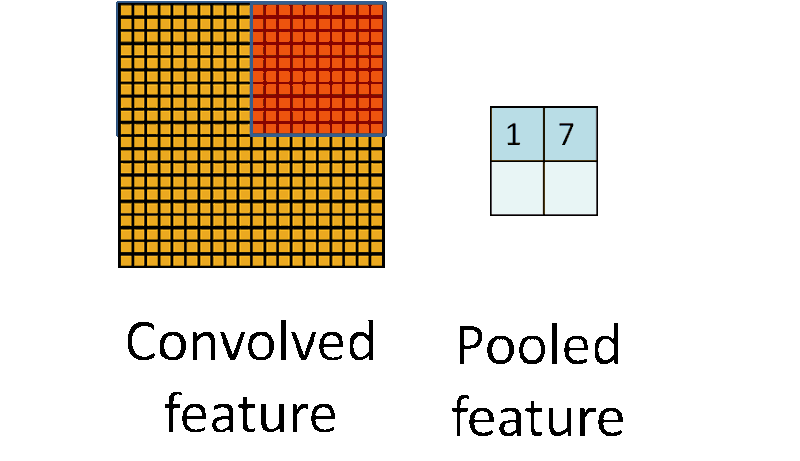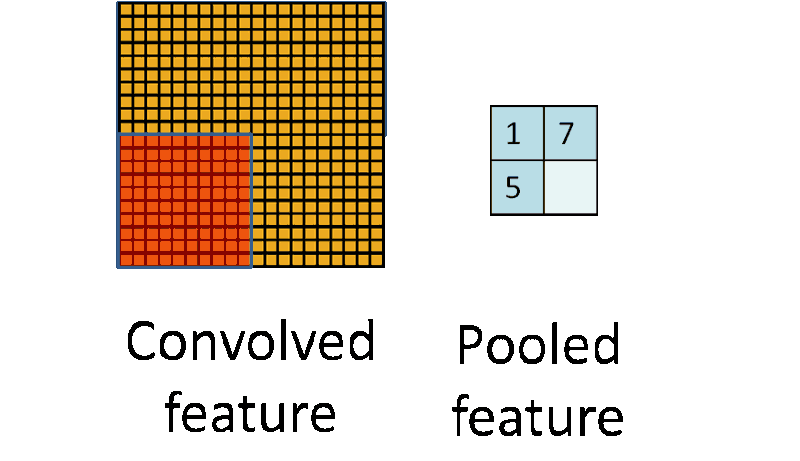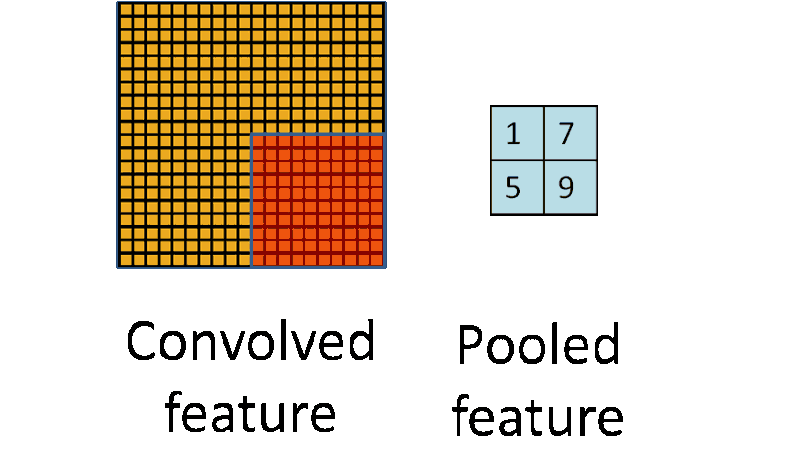
Pooling works very much like convoluting, where we take a kernel and move the kernel over the image, the only difference is the function that is applied to the kernel and the image window isn’t linear.
池化层和卷积层很类似,也是用一个卷积核在图上移动。唯一的不同就是池化层中核和图片窗口的操作不再是线性的。
Max pooling and Average pooling are the most common pooling functions. Max pooling takes the largest value from the window of the image currently covered by the kernel, while average pooling takes the average of all values in the window.
最大池化和平均池化是最常见的池化函数。最大池化选取当前核覆盖的图片窗口中最大的数,而平均池化则是选择图片窗口的均值。
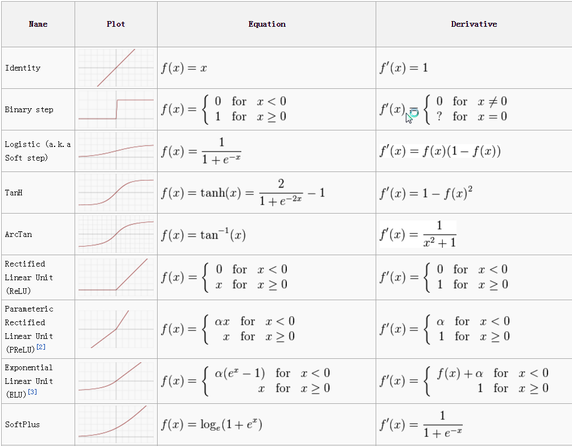
Activation layers work exactly as in other neural networks, a value is passed through a function that squashes the value into a range. Here’s a bunch of common ones:
在CNN中,激活函数和其他网络一样,函数将数值压缩在一个范围内。下面列出了一些常见的函数:
The most used activation function in CNNs is the relu (Rectified Linear Unit). There are a bunch of reason that people like relus, but a big one is because they are really cheap to perform, if the number is negative: zero, else: the number. Being cheap makes it faster to train networks.
在CNN中最常用的是relu(修正线性单元)。人们有许多喜欢relu的理由,但是最重要的一点就是它非常的易于实现,如果数值是负数则输出0,否则输出本身。这种函数运算简单,所以训练网络也非常快。
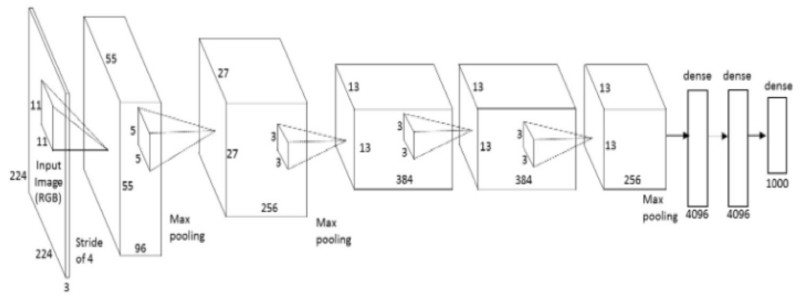
Before we get into what a CNN looks like, a little bit of background. The first successful applications of ConvNets was by Yann LeCun in the 90’s, he created something called LeNet, that could be used to read hand written numbers. Since then, computing advancements and powerful GPUs have allowed researchers to be more ambitious. In 2010 the Stanford Vision Lab released ImageNet. Image net is data set of 14 million images with labels detailing the contents of the images. It has become one of the research world’s standards for comparing CNN models, with current best models will successfully detect the objects in 94+% of the images. Every so often someone comes in and beats the all time high score on imagenet and its a pretty big deal. In 2014 it was GoogLeNet and VGGNet, before that it was ZF Net. The first viable example of a CNN applied to imagenet was AlexNet in 2012, before that researches attempted to use traditional computer vision techiques, but AlexNet outperformed everything else up to that point by ~15%.
在我们深入了解CNN之前,让我们先补充一些背景知识。早在上世纪90年代,Yann LeCun就使用CNN做了一个手写数字识别的程序。而随着时代的发展,尤其是计算机性能和GPU的改进,研究人员有了更加丰富的想象空间。 2010年斯坦福的机器视觉实验室发布了ImageNet项目。该项目包含1400万带有描述标签的图片。这个几乎已经成为了比较CNN模型的标准。目前,最好的模型在这个数据集上能达到94%的准确率。人们不断的改善模型来提高准确率。在2014年GoogLeNet 和VGGNet成为了最好的模型,而在此之前是ZFNet。CNN应用于ImageNet的第一个可行例子是AlexNet,在此之前,研究人员试图使用传统的计算机视觉技术,但AlexNet的表现要比其他一切都高出15%。
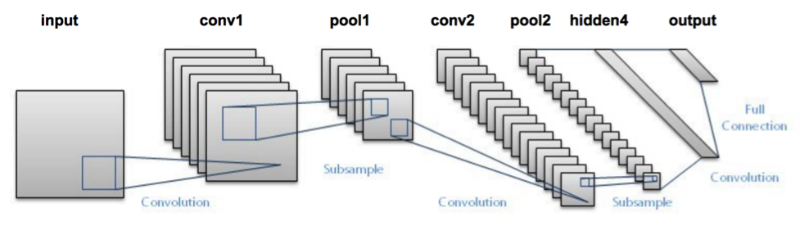
Anyway, lets look at LeNet:
让我们一起看一下LeNet:
This diagram doesn’t show the activation functions, but the architecture is:
这个图中并没有显示激活层,整个的流程是:
Input image →ConvLayer →Relu → MaxPooling →ConvLayer →Relu→ MaxPooling →Hidden Layer →Softmax (activation)→output layer
输入图片 →卷积层 →Relu → 最大池化→卷积层 →Relu→ 最大池化→隐藏层 →Softmax (activation)→输出层。
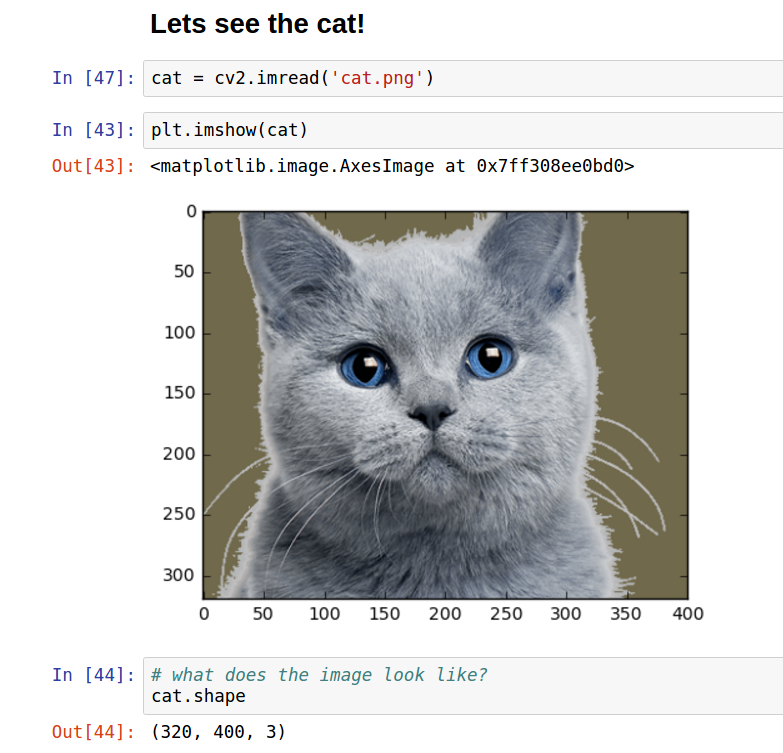
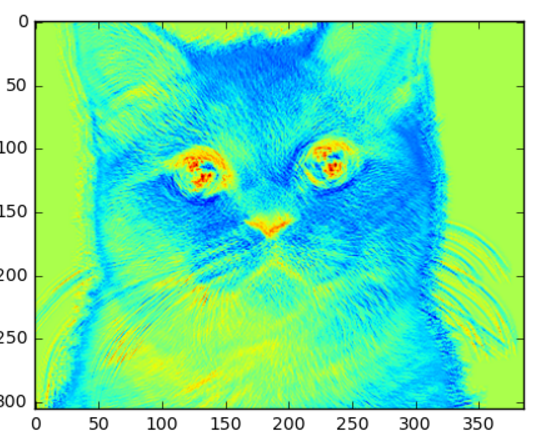
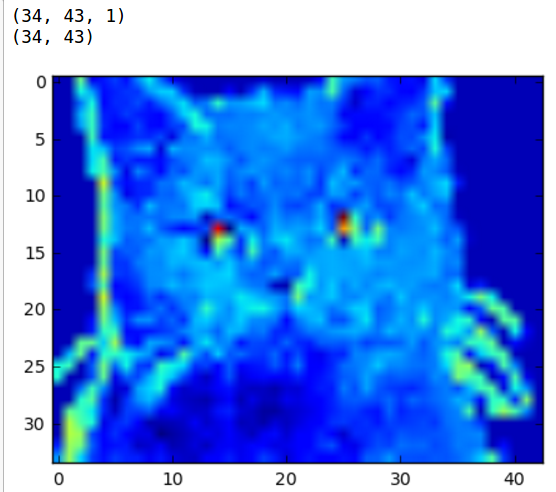
Here is an image of a cat:
下图是一个猫的图片:
Our picture of the cat has a height 320px, a width of 400px, and 3 channels of color (RGB).
这张图长400像素宽320像素,有三个通道(rgb)的颜色。
So what does he look like after one layer of convolution?
那么经过一层卷积运算之后会变成什么样子呢?
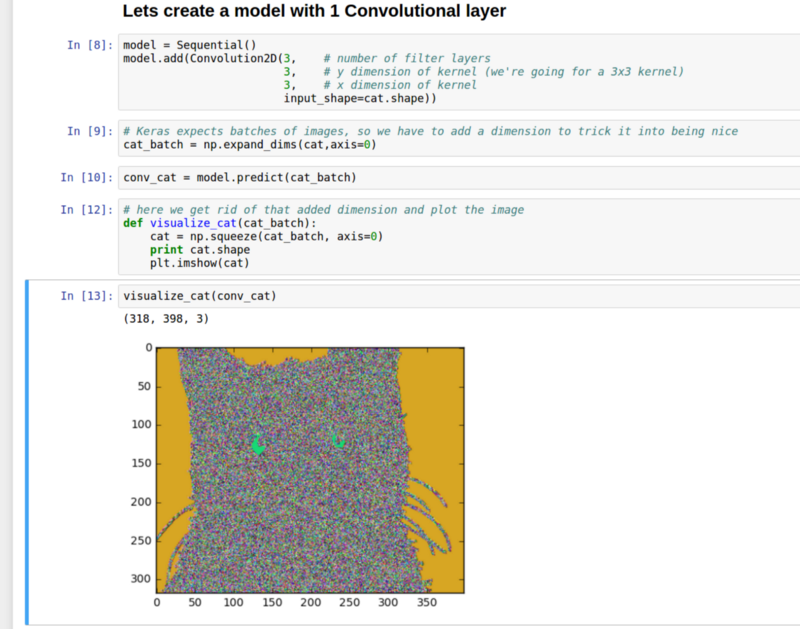
Here is the cat with a kernel size of 3x3 and 3 filters (if we have more than 3 filter layers we cant plot a 2d image of the cat. Higher dimensional cats are notoriously tricky to deal with.).
这是用一个3*3的卷积核和三个滤波器处理的效果(如果我们有超过3个的滤波器,那么我可以画出猫的2d图像。更高维的话就很难处理)
As you can see the cat is really noisy because all of our weights are randomly initialized and we haven’t trained the network. Oh and they’re all on top of each other so even if there was detail on each layer we wouldn’t be able to see it. But we can make out areas of the cat that were the same color like the eyes and the background. What happens if we increase the kernel size to 10x10?
我们可以看到,图中的猫非常的模糊,因为我们使用了一个随机的初始值,而且我们还没有训练网络。他们都在彼此的顶端,即使每层都有细节,我们将无法看到它。但我们可以制作出与眼睛和背景相同颜色的猫的区域。如果我们将内核大小增加到10x10,会发生什么呢?
As we can see, we lost some of the detail because the kernel was too big. Also note the shape of the image is slightly smaller because of the larger kernel, and because math governs stuff.
我们可以看到,由于内核太大,我们失去了一些细节。还要注意,从数学角度来看,卷积核越大,图像的形状会变得越小。
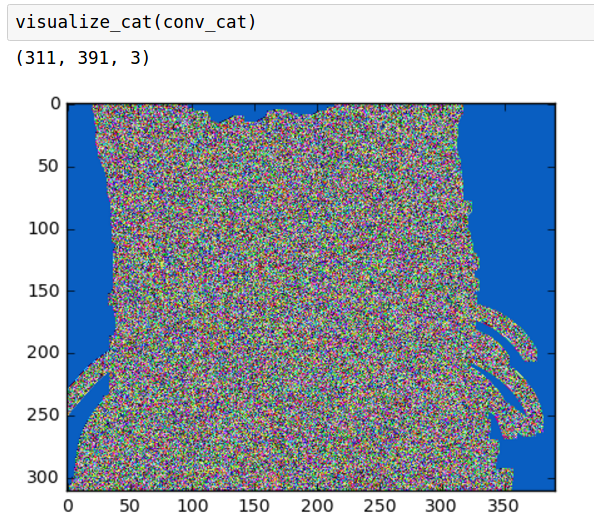
What happens if we squish it down a bit so we can see the color channels better?
如果我们把它压扁一点,我们可以更好的看到色彩通道会发生什么?
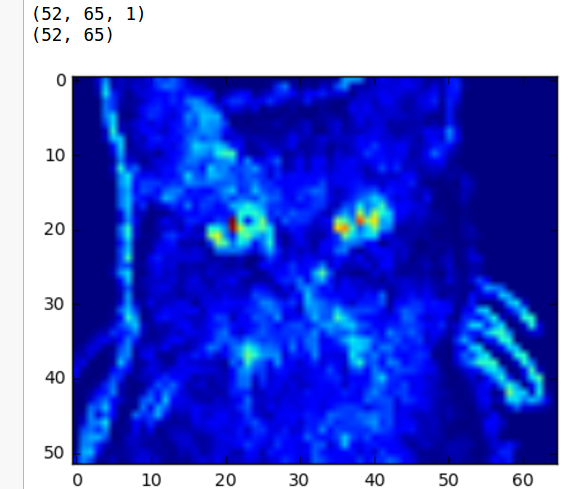
Much better! Now we can see some of the things our filter is seeing. It looks like red is really liking the black bits of the nose an eyes, and blue is digging the light grey that outlines the cat. We can start to see how the layer captures some of the more important details in the photo.
这张看起来好多了!现在我们可以看到我们的过滤器看到的一些事情。看起来红色替换掉了黑色的鼻子和黑色眼睛,蓝色替换掉了猫边界的浅灰色。我们可以开始看到图层如何捕获照片中的一些更重要的细节。
If we increase the kernel size its far more obvious now that we get less detail, but the image is also smaller than the other two.
如果我们增加内核大小,我们得到的细节就会越来越明显,当然图像也比其他两个都小。
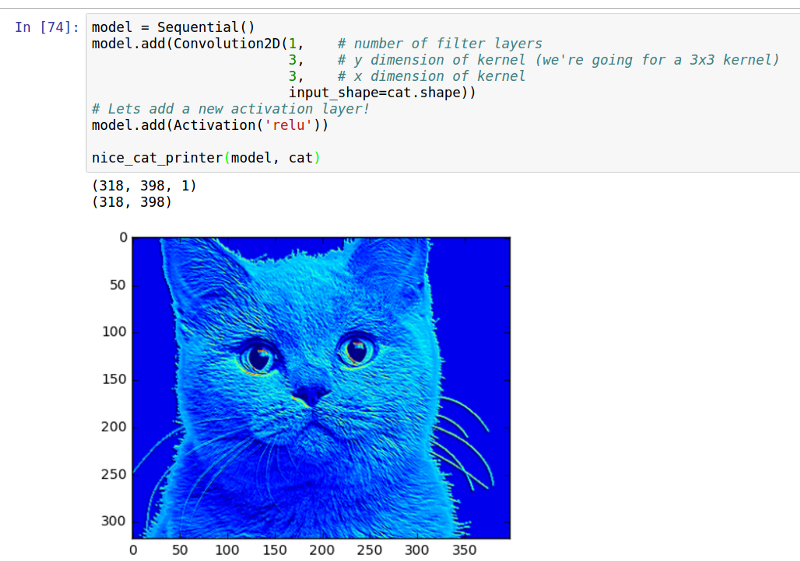
We get rid of of a lot of the not blue-ness by adding a relu.
我们通过添加一个relu,去掉了很多不是蓝色的部分。
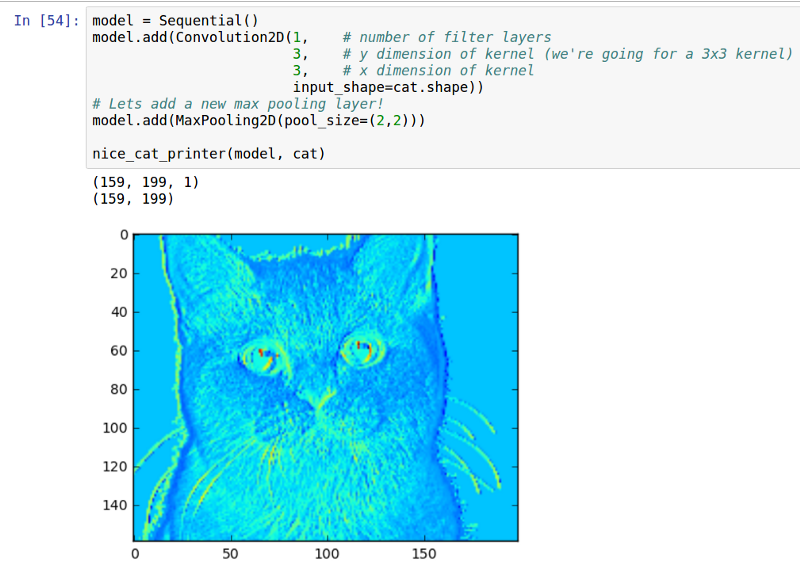
We add a pooling layer (getting rid of the activation just max it a bit easier to show)
我们添加一个池化层(摆脱激活层最大限度地让图片更加更容易显示)。
As expected, the cat is blockier, but we can go even blockyier!
正如预期的那样,猫咪变成了斑驳的,而我们可以让它更加斑驳。
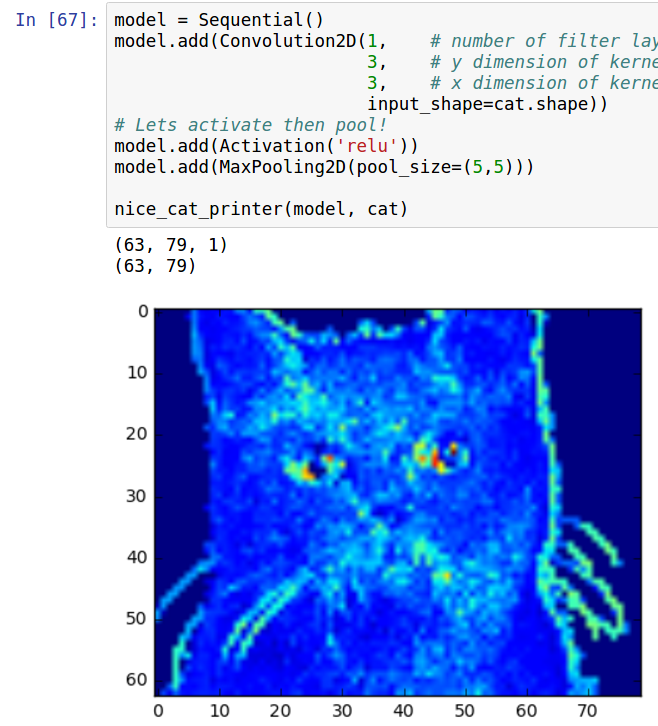
Notice how the image is now about a third the size of the original.
现在图片大约成了原来的三分之一。
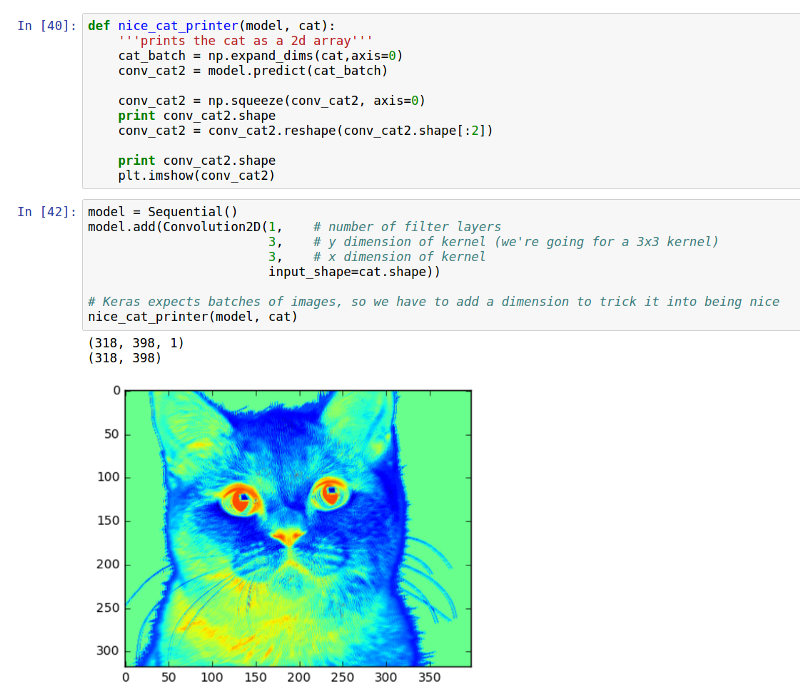
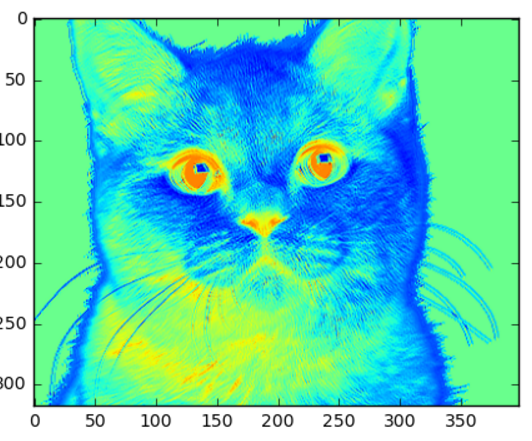
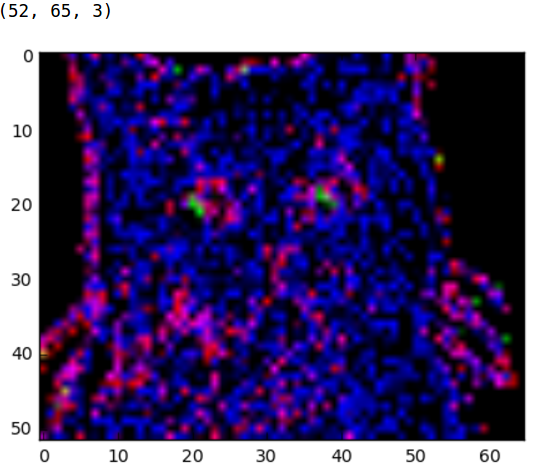
What do the cats look like if we put them through the convolutional and pools sections of LeNet?
如果我们将猫咪的图片放到LeNet模型中做卷积和池化,那么效果会怎么样呢?
ConvNets are powerful due to their ability to extract the core features of an image and use these features to identify images that contain features like them. Even with our two layer CNN we can start to see the network is paying a lot of attention to regions like the whiskers, nose, and eyes of the cat. These are the types of features that would allow the CNN to differentiate a cat from a bird for example.
ConvNets功能强大,因为它们能够提取图像的核心特征,并使用这些特征来识别包含其中的特征的图像。即使我们的两层CNN,我们也可以开始看到网络正在对猫的晶须,鼻子和眼睛这样的地区给予很多的关注。这些是让CNN将猫与鸟区分开的特征的类型。
CNNs are remarkably powerful, and while these visualizations aren’t perfect, I hope they can help people like myself who are still learning to reason about ConvNets a little better.
CNN是非常强大的,虽然这些可视化并不完美,但我希望他们能够帮助像我这样正在尝试更好地理解ConvNets的人。
All code is on Github: https://github.com/erikreppel/visualizing_cnns
Follow me on Twitter, I’m @programmer (yes, seriously).
A guide to convolution arithmetic for deep learning by Vincent Dumoulin and Francesco Visin



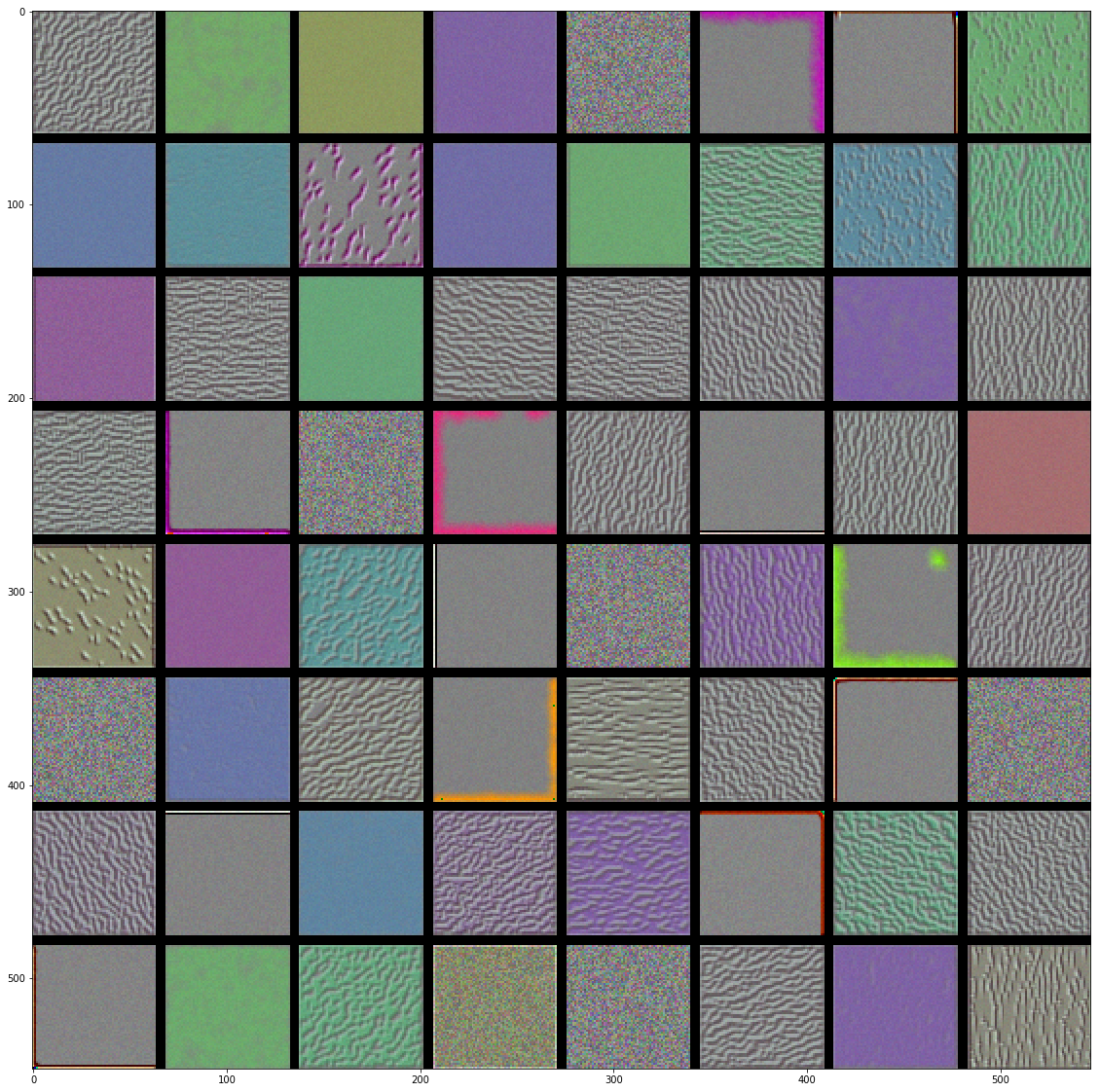
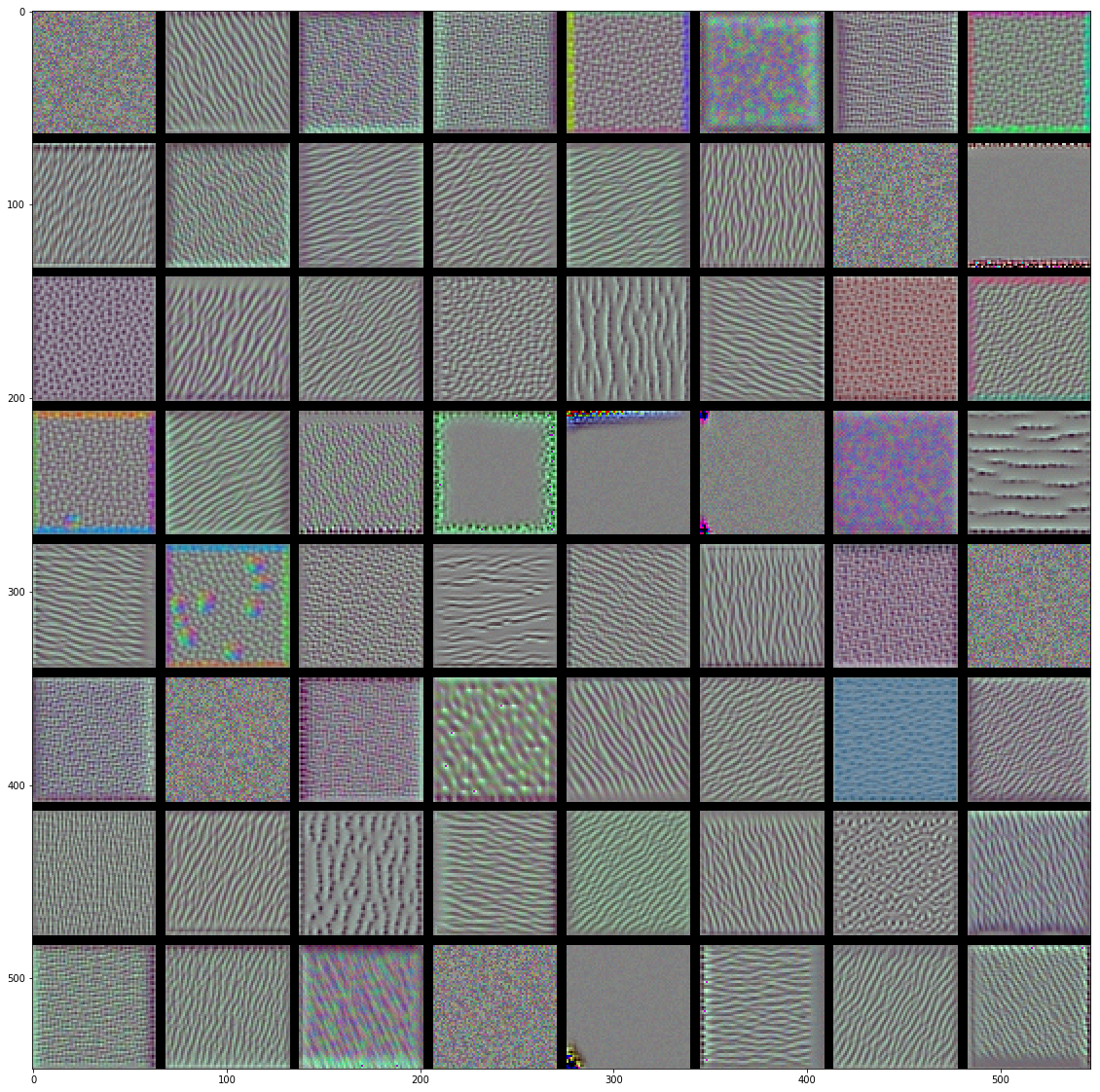
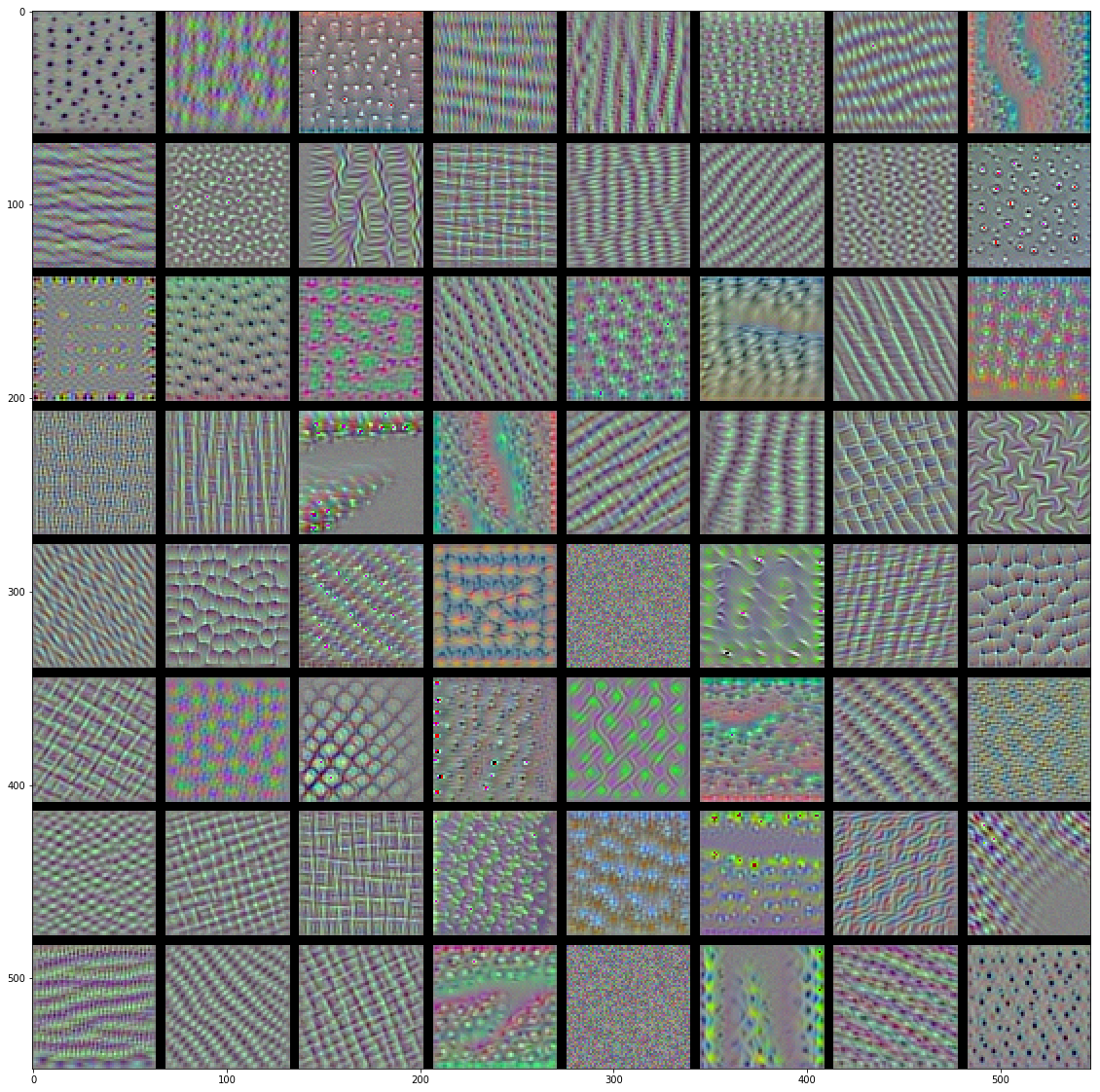
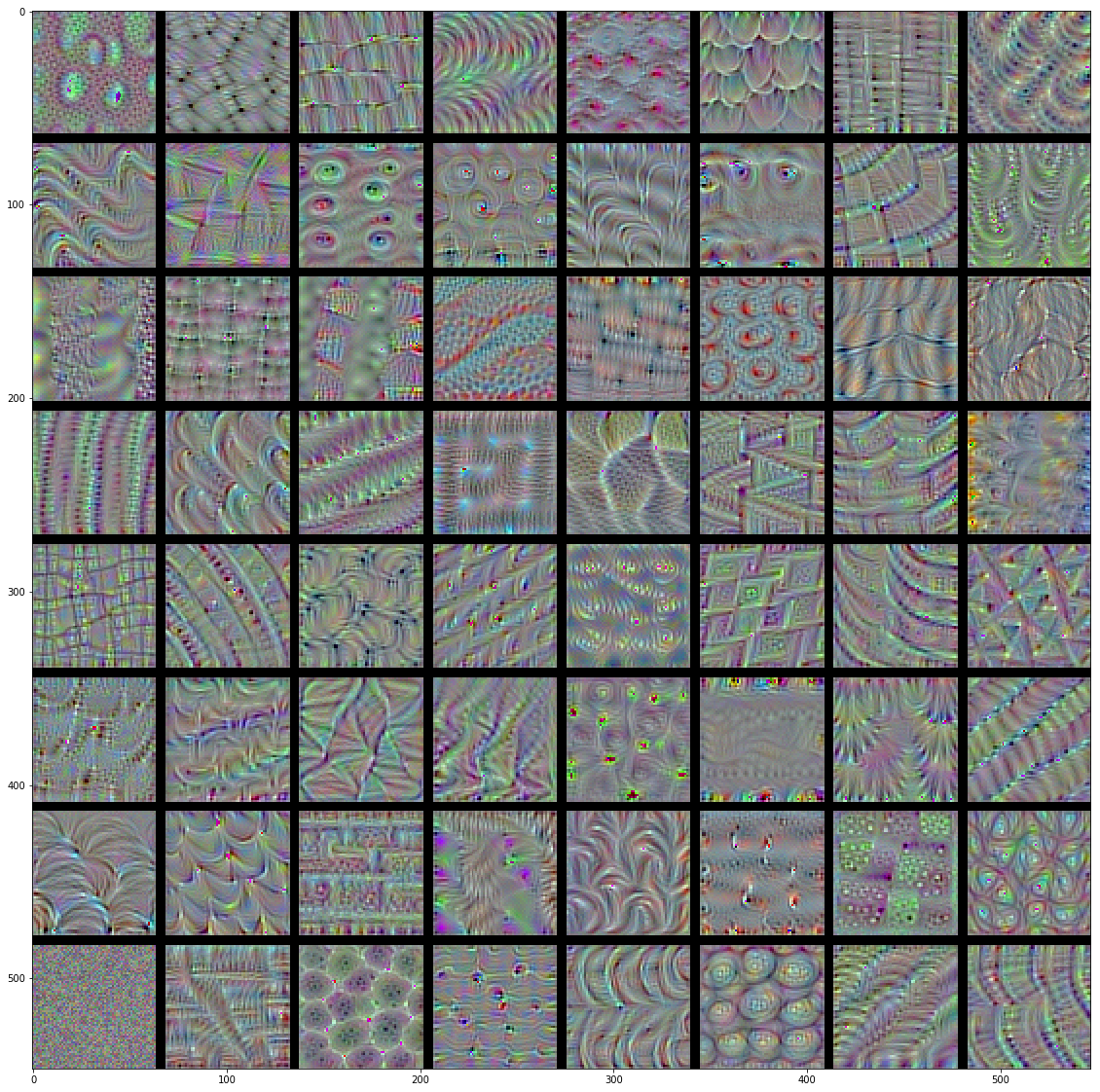

visualization of filters keras 基于Keras的卷积神经网络(CNN)可视化
标签:类型 发布 article dia compute 斯坦福 var ted 补充
原文地址:https://www.cnblogs.com/klausage/p/12312738.html