标签:硬件 接收 依赖 mapred http 空间 hadoop 情况 检查
HDFS(Hadoop Distributed File System)是hadoop生态系统的一个重要组成部分,是hadoop中的的存储组件,在整个Hadoop中的地位非同一般,是最基础的一部分,因为它涉及到数据存储,MapReduce等计算模型都要依赖于存储在HDFS中的数据。HDFS是一个分布式文件系统,以流式数据访问模式存储超大文件,将数据分块存储到一个商业硬件集群内的不同机器上。
这里重点介绍其中涉及到的几个概念:(1)超大文件。目前的hadoop集群能够存储几百TB甚至PB级的数据。(2)流式数据访问。HDFS的访问模式是:一次写入,多次读取,更加关注的是读取整个数据集的整体时间。(3)商用硬件。HDFS集群的设备不需要多么昂 贵和特殊,只要是一些日常使用的普通硬件即可,正因为如此,hdfs节点故障的可能性还是很高的,所以必须要有机制来处理这种单点故障,保证数据的可靠。(4)不支持低时间延迟的数据访问。hdfs关心的是高数据吞吐量,不适合那些要求低时间延迟数据访问的应用。(5)单用户写入,不支持任意修改。hdfs的数据以读为主,只支持单个写入者,并且写操作总是以添加的形式在文末追加,不支持在任意位置进行修改。
每个磁盘都有默认的数据块大小,这是文件系统进行数据读写的最小单位。这涉及到磁盘的相应知识,这里我们不多讲,后面整理一篇博客来记录一下磁盘的相应知识。
HDFS同样也有数据块的概念,默认一个块(block)的大小为128MB(HDFS的块这么大主要是为了最小化寻址开销),要在HDFS中存储的文件可以划分为多个分块,每个分块可以成为一个独立的存储单元。与本地磁盘不同的是,HDFS中小于一个块大小的文件并不会占据整个HDFS数据块。
对HDFS存储进行分块有很多好处:
HDFS集群的节点分为两类:namenode和datanode,以管理节点-工作节点的模式运行,即一个namenode和多个datanode,理解这两类节点对理解HDFS工作机制非常重要。
namenode作为管理节点,它负责整个文件系统的命名空间,并且维护着文件系统树和整棵树内所有的文件和目录,这些信息以两个文件的形式(命名空间镜像文件和编辑日志文件)永久存储在namenode 的本地磁盘上。除此之外,同时,namenode也记录每个文件中各个块所在的数据节点信息,但是不永久存储块的位置信息,因为块的信息可以在系统启动时重新构建。
datanode作为文件系统的工作节点,根据需要存储并检索数据块,定期向namenode发送他们所存储的块的列表。
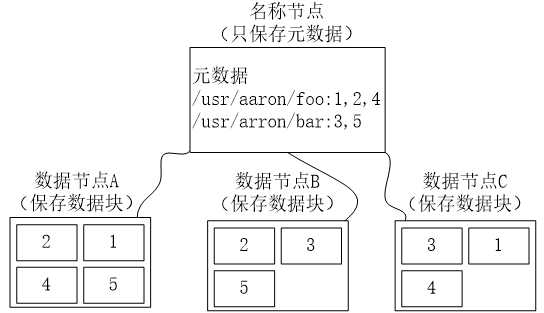
由此可见,namenode作为管理节点,它的地位是非同寻常的,一旦namenode宕机,那么所有文件都会丢失,因为namenode是唯一存储了元数据、文件与数据块之间对应关系的节点,所有文件信息都保存在这里,namenode毁坏后无法重建文件。因此,必须高度重视namenode的容错性。
为了使得namenode更加可靠,hadoop提供了两种机制:
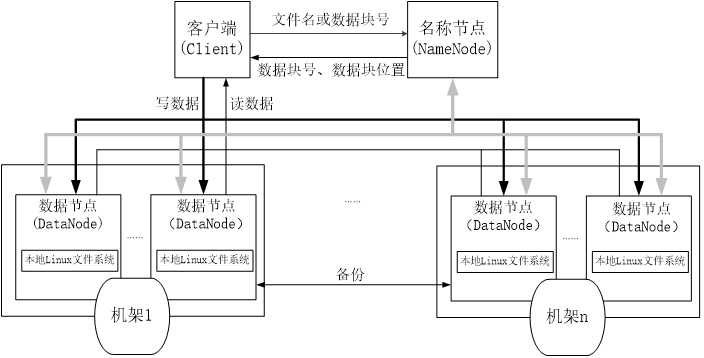
数据通常情况下都保存在磁盘,但是对于访问频繁的文件,其对应的数据块可能被显式的缓存到datanode的内存中,以堆外缓存的方式存在,一些计算任务(比如mapreduce)可以在缓存了数据的datanode上运行,利用块的缓存优势提高读操作的性能。
namenode在内存中保存了文件系统中每个文件和每个数据块的引用关系,这意味着,当文件足够多时,namenode的内存将成为限制系统横向扩展的瓶颈。hadoop2.0引入了联邦HDFS允许系统通过添加namenode的方式实现扩展,每个namenode管理文件系统命名空间中的一部分,比如:一个namenode管理/usr下的文件,另外一个namenode管理/share目录下的文件。
通过备份namenode存储的文件信息或者运行辅助namenode可以防止数据丢失,但是依旧没有保证了系统的高可用性。一旦namenode发生了单点失效,那么必须能够快速的启动一个拥有文件系统信息副本的新namenode,而这个过程需要以下几步:(1)将命名空间的副本映像导入内存 (2)重新编辑日志 (3)接收足够多来自datanode的数据块报告,从而重建起数据块与位置的对应关系。
上述实际上就是一个namenode的冷启动过程,但是在数据量足够大的情况下,这个冷启动可能需要30分钟以上的时间,这是无法忍受的。
Hadoop2.0开始,增加了对高可用性的支持。采用了双机热备份的方式。同时使用一对活动-备用namenode,当活动namenode失效后,备用namenode可以迅速接管它的任务,这中间不会有任何的中断,以至于使得用户根本无法察觉。
为了实现这种双机热备份,HDFS架构需要作出以下几个改变:
HDFS系统中运行着一个故障转移控制器,管理着将活动namenode转移为备用namenode的转换过程。同时,每一个namenode也运行着一个轻量级的故障转移控制器,主要目的就是监视宿主namenode是否失效,并在失效时实现迅速切换。
标签:硬件 接收 依赖 mapred http 空间 hadoop 情况 检查
原文地址:https://www.cnblogs.com/deityjian/p/12312826.html