标签:oci asc 程序 specified ref 限制 -- size 描述
PASCAL VOC为图像识别和分类提供了一整套标准化的优秀的数据集,从2005年到2012年每年都会举行一场图像识别challenge
默认为20类物体


①JPEGImages
JPEGImages文件夹中包含了PASCAL VOC所提供的所有的图片信息,包括了训练图片和测试图片。
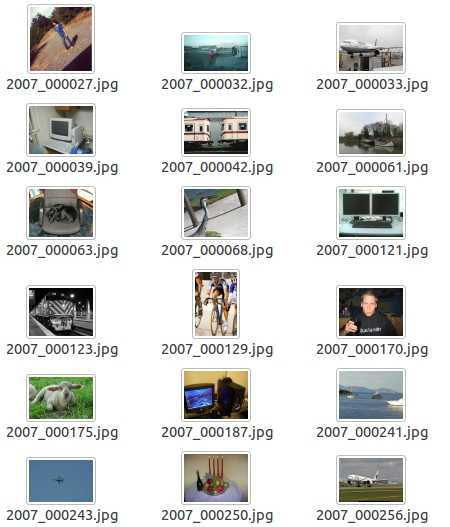
②Annotations
Annotations文件夹中存放的是xml格式的标签文件,每一个xml文件都对应于JPEGImages文件夹中的一张图片。
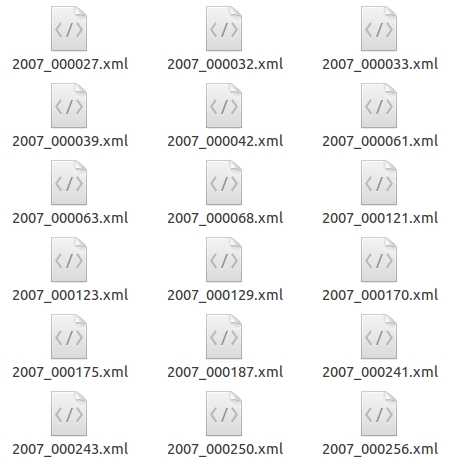
xml文件的具体格式如下:(对于2007_000392.jpg)
<annotation>
<folder>VOC2012</folder>
<filename>2007_000392.jpg</filename> //文件名
<source> //图像来源(不重要)
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
</source>
<size> //图像尺寸(长宽以及通道数)
<width>500</width>
<height>332</height>
<depth>3</depth>
</size>
<segmented>1</segmented> //是否用于分割(在图像物体识别中01无所谓)
<object> //检测到的物体
<name>horse</name> //物体类别
<pose>Right</pose> //拍摄角度
<truncated>0</truncated> //是否被截断(0表示完整)
<difficult>0</difficult> //目标是否难以识别(0表示容易识别)
<bndbox> //bounding-box(包含左下角和右上角xy坐标)
<xmin>100</xmin>
<ymin>96</ymin>
<xmax>355</xmax>
<ymax>324</ymax>
</bndbox>
</object>
<object> //检测到多个物体
<name>person</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox> //检测矩形框坐标
<xmin>198</xmin>
<ymin>58</ymin>
<xmax>286</xmax>
<ymax>197</ymax>
</bndbox>
</object>
</annotation>
对应的图片为:

③ImageSets
ImageSets存放的是每一种类型的challenge对应的图像数据。
在ImageSets下有四个文件夹:

其中Action下存放的是人的动作(例如running、jumping等等,这也是VOC challenge的一部分)
Layout下存放的是具有人体部位的数据(人的head、hand、feet等等,这也是VOC challenge的一部分)
Main下存放的是图像物体识别的数据,总共分为20类。
Segmentation下存放的是可用于分割的数据。
在这里主要考察Main文件夹。

Main文件夹下包含了20个分类的***_train.txt、***_val.txt和***_trainval.txt。
这些txt中的内容都差不多如下:
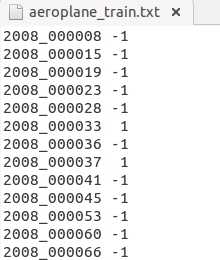
前面的表示图像的name,后面的1代表正样本,-1代表负样本。
_train中存放的是训练使用的数据,每一个class的train数据都有5717个。
_val中存放的是验证结果使用的数据,每一个class的val数据都有5823个。
_trainval将上面两个进行了合并,每一个class有11540个。
需要保证的是train和val两者没有交集,也就是训练数据和验证数据不能有重复,在选取训练数据的时候 ,也应该是随机产生的。
900万张标注图像,谷歌发布Open Images最新V3版
该数据集包含一个训练集(9011219张图像)、一个验证集(41620张图像)和一个测试集(125436张图像)。V1 版本里的验证集在 V2 版本中被划分为验证集和测试集,这样做是为了更好地进行评估。Open Images 中的所有图像都标注有图像级标签和边界框
600余物体类别在线浏览
分类标签示例:

到官网下载的时候要一次性下载所有的部分,不仅文件很大,而且下载的也不大快,更重要的是自己训练要用到的类别并不多。
我采用的是工具箱的方法(https://github.com/EscVM/OIDv4_ToolKit),实际操作起来也挺顺利的。
Open Images V4 下载自己需要的特定类别
Step1:Install the required packages
pip install -r requirements.txt
Step2:
python main.py downloader --classes ./classes.txt --type_csv all --limit 3000
用法:main.py [-h] [--Dataset/path/to/OID/csv/] [-y]
[ - 类列表[类列表...]]
[--type_csv'train'或'validation'或'test'或'all']
[--sub 子人验证图像的子集或机器生成的h或m)]
[--image_IsOccluded 1或0] [ - image_IsTruncated 1或0]
[--image_IsGroupOf 1或0] [ - image_IsDepiction 1或0]
[--image_IsInside 1或0] [--multiclasses 0(默认值或1)
[--n_threads [默认20]] [--noLabels]
[--limit integer number]
<command>'downloader','visualizer'或'ill_downloader'。
Open Image Dataset Downloader
打开图像数据集下载程序
位置参数:
<command>'downloader','visualizer'或'ill_downloader'。
'downloader','visualizer'或'ill_downloader'。
可选参数:
-h, --help 显示此帮助消息并退出
--Dataset /path/to/OID/csv/
OID数据集文件夹的目录
-y, --yes 是和是可以下载丢失的文件
- 类列表[类列表...]
所需类的“字符串”序列
--type_csv'train'或'validation'或'test'或'all'
从什么csv搜索图像
--sub 人工验证图像或机器生成的子集(h或m)
从人类验证的数据集或从
机器生成一个。
--image_IsOccluded 1或0
图像的可选特征。表示
对象被图像中的另一个对象遮挡。
--image_IsTruncated 1或0
图像的可选特征。表示
对象超出图像的边界。
--image_IsGroupOf 1或0
图像的可选特征。表示
盒子跨越一组物体(分钟5)。
--image_IsDepiction 1或0
图像的可选特征。表示
对象是一个描述。
--image_IsInside 1或0
图像的可选特征。表示a
从对象内部拍摄的照片。
--multiclasses 0(默认值)或1
分别(0)或一起下载不同的类
(1)
--n_threads [默认20]
要使用的线程数
--noLabels 没有标签创作
--limit integer number
要下载的图像数量的可选限制下载完成后得到 OID Folder
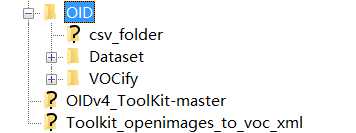
Step1:Get VOC.xml - csv2voc.py
Openimage.csv to Anotation/XXX.xml
Input : OPEN_IMAGES_DIR = folder of csv file
eg. where the validation-annotations-bbox.csv is.
Output = Anotation/XXX.xml +
test.txt、train.txt、val.txt、trainval.txt
生成后得到VOCify Folder
Note: 此时无需直接操作图片
test.txt、train.txt、val.txt、trainval.txt 后期训练时可再次生成,代码如下
# -*- coding:utf-8 -*-
# -*- python3.5
import os
import random
trainval_percent = 0.7 #可以自己设置
train_percent = 0.8 #可以自己设置
xmlfilepath = 'Annotations' #地址填自己的
txtsavepath = 'ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num*trainval_percent)
tr = int(tv*train_percent)
trainval = random.sample(list,tv)
train = random.sample(trainval,tr)
ftrainval = open(txtsavepath+'/trainval.txt', 'w')
ftest = open(txtsavepath+'/test.txt', 'w')
ftrain = open(txtsavepath+'/train.txt', 'w')
fval = open(txtsavepath+'/val.txt', 'w')
for i in list:
name = total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else: fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
print('Well finshed')
Step2:Save images to JPEGImages folder - By hand
cp -r Dataset/images_file* VOCify/JPEGImages
Source : Dataset/images_file
Destination : VOCify/JPEGImages
Step3:Set same name - my_same_name.py
Set Anotation/XXX.xml as JPEGImages/XXX.jpg
Make XXX the same
推荐:使用labelImg工具给图片上标签,并生成.xml文件
【Detection】物体识别-制作PASCAL VOC数据集
标签:oci asc 程序 specified ref 限制 -- size 描述
原文地址:https://www.cnblogs.com/Neo007/p/12316584.html