标签:默认 ref sha use cond alt img redis 集群
(1)备份数据
① Redis SAVE命令用于创建当前数据库的备份。
语法:redis 127.0.0.1:6379> SAVE
该命令将在Redis安装目录中创建dump.rdb文件。
② 创建Redis备份文件也可以使用命令BGSAVE,该命令在后台执行。
例:
127.0.0.1:6379> BGSAVE
Background saving started
(2)恢复数据
如果需要恢复数据,只需要将备份文件dump.rdb移动到Redis安装目录并启动服务即可。获取Redis目录可以使用CONFIG命令。
例:
redis 127.0.0.1:6379> CONFIG GET dir #输出Redis的安装目录
1) "dir"
2) "/usr/local/redis/bin"
可以通过Redis的配置文件来设置密码参数,这样客户端连接到Redis服务就需要密码验证,可以使Redis服务更安全。
例:
# 通过以下命令查看是否设置了密码验证 127.0.0.1:6379> CONFIG get requirepass 1) "requirepass" 2) "" #默认情况下requirepass参数是空的,意味着无需通过密码验证就可以连接到Redis服务。 #通过以下命令修改该参数 127.0.0.1:6379> CONFIG set requirepass "runoob" OK 127.0.0.1:6379> CONFIG get requirepass 1) "requirepass" 2) "runoob" # 设置密码后,客户端连接Redis服务就需要密码验证,否则无法执行命令。
AUTH命令: 用于检测给定的密码和配置文件中的密码是否相符。
基本语法:127.0.0.1:6379> AUTH password
例:
127.0.0.1:6379> AUTH "runoob" OK 127.0.0.1:6379> SET mykey "Test value" OK 127.0.0.1:6379> GET mykey "Test value"
Redis性能测试是通过执行多个命令实现的。
redis-benchmark [option] [option value] # 该命令是在Redis的目录下执行的,而不是Redis客户端的内部指令。
例:
# 以下示例同时执行10000个请求测试性能 $ redis-benchmark -n 10000 -q PING_INLINE: 141043.72 requests per second PING_BULK: 142857.14 requests per second SET: 141442.72 requests per second GET: 145348.83 requests per second INCR: 137362.64 requests per second LPUSH: 145348.83 requests per second LPOP: 146198.83 requests per second SADD: 146198.83 requests per second SPOP: 149253.73 requests per second LPUSH (needed to benchmark LRANGE): 148588.42 requests per second LRANGE_100 (first 100 elements): 58411.21 requests per second LRANGE_300 (first 300 elements): 21195.42 requests per second LRANGE_500 (first 450 elements): 14539.11 requests per second LRANGE_600 (first 600 elements): 10504.20 requests per second MSET (10 keys): 93283.58 requests per second
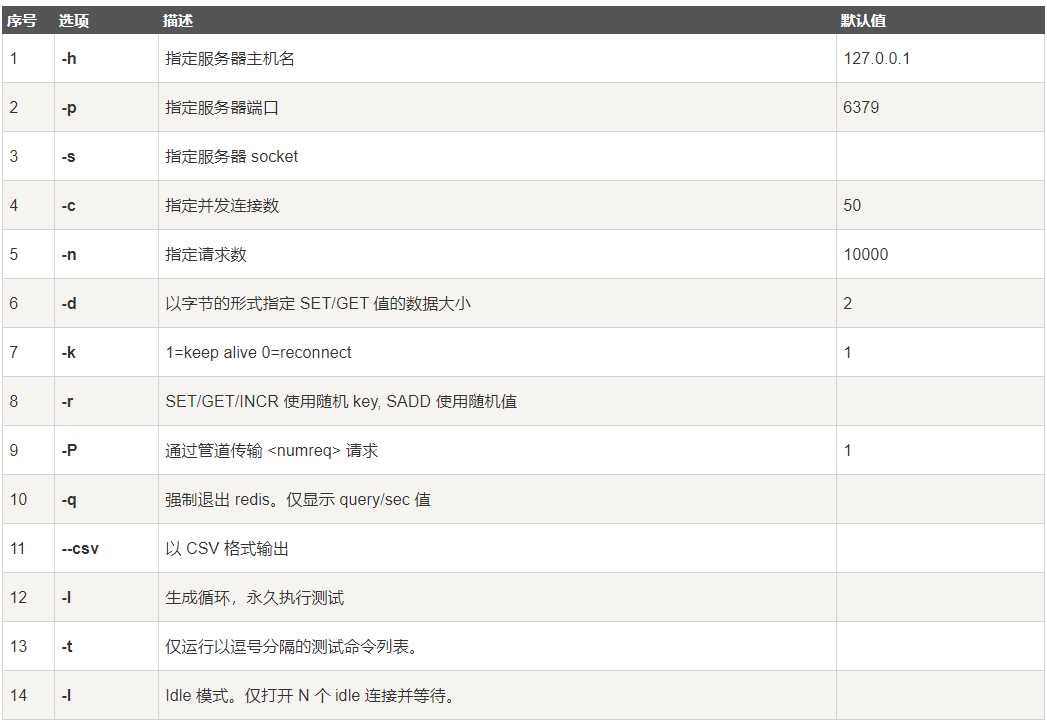
例:使用多个参数来测试Redis性能
$ redis-benchmark -h 127.0.0.1 -p 6379 -t set,lpush -n 10000 -q SET: 146198.83 requests per second LPUSH: 145560.41 requests per second # 上述例子中主机为127.0.0.1,端口号为6379,执行的命令为set,lpush,请求数为10000,通过-q参数让结果只显示每秒执行的请求数。
Redis通过监听一个TCP端口或者Unix socket的方式来接受客户端的连接,当一个连接建立后,Redis内部会进行以下一些操作:
(1)首先,客户端socket会被设置为非阻塞模式,因为Redis在网络事件处理上采用的是非阻塞多路复用模型。
(2)然后为这个socket设置TCP_NODELAY属性,禁用Nagle算法。
(3)然后创建一个可读的文件事件用于监听这个客户端socket的数据发送。
在Redis 2.4中,最大连接数是被直接硬编码在代码里的,而在2.6版本中这个值变成可配置的。maxclients的默认值是10000,你也可以在redis.conf中对这个值进行修改。
config get maxclients
1) "maxclients"
2) "10000"
例:
# 如我们在服务启动时设置最大连接数为100,000 redis-server --maxclients 100000
(1)CLIENT LIST 返回连接到redis服务的客户端列表
(2)CLIENT SETNAME 设置当前连接的名称
(3)CLIENT GETNAME 获取通过CLIENT SETNAME命令设置的服务名称
(4)CLIENT PAUSE 挂起客户端连接,指定挂起的时间以毫秒计
(5)CLIENT KILL 关闭客户端连接
Redis是一种基于客户端-服务端模型以及请求/相应协议的TCP服务。通常一个请求会遵循以下步骤:
(1)客户端向服务端发送一个查询请求,并监听socket返回,通常是以阻塞模式,等待服务端相应。
(2)服务端处理命令,并将结果返回给客户端。
Redis管道技术可以在服务端未响应时,客户端可以继续向服务端发送请求,并最终一次性读取所有服务端的响应。
例:
# 查看redis管道,只需要启动redis示例并输入以下命令 $(echo -en "PING\r\n SET runoobkey redis\r\nGET runoobkey\r\nINCR visitor\r\nINCR visitor\r\nINCR visitor\r\n"; sleep 10) | nc localhost 6379 +PONG +OK redis :1 :2 :3 # 以上我们通过使用ping命令查看redis服务是否可以使用,之后我们设置了runoobkey的值为redis,然后我们获取了runoobkey的值并使得visitor自增3次。 # 在返回的结果中我们可以看到这些命令一次性向redis服务提交,并最终一次性读取所有服务端响应
管道技术最显著的优势是提高了Redis服务的性能
例:以下实例中我们使用Redis的Ruby客户端,支持管道技术特性,测试管道技术对速度的提升效果。
require ‘rubygems‘ require ‘redis‘ def bench(descr) start = Time.now yield puts "#{descr} #{Time.now-start} seconds" end def without_pipelining r = Redis.new 10000.times { r.ping } end def with_pipelining r = Redis.new r.pipelined { 10000.times { r.ping } } end bench("without pipelining") { without_pipelining } bench("with pipelining") { with_pipelining } # 从处于局域网中的Mac OS X系统上执行上面这个简单脚本的数据表明,开启了管道操作后,往返延时已经被改善得相当低了。 without pipelining 1.185238 seconds with pipelining 0.250783 seconds # 开启管道后,我们的速度效率提升了5倍。
分区是分割数据到多个Redis实例的处理过程,因此每个实例只保存key的一个子集。
(1)通过利用多台计算机内存和值,允许我们构造更大的数据库。
(2)通过多核和多台计算机,允许我们扩展计算机能力;通过多台计算机和网络适配器,允许我们扩展网络带宽。
(1)涉及多个key的操作通常是不被支持的。如:当两个set映射到不同的redis实例上时,你就不能对这两个set执行交集操作。
(2)涉及多个key的Redis事务不能使用。
(3)当使用分区时,数据处理较为复杂,比如你需要处理多个rdb/aof文件,并且从多个实例和主机备份持久化文件。
(4)增加或删除容量也比较复杂。redis集群大多数支持在运行时增加、删除节点的透明数据平衡的能力,但是类似于客户端区分、代理等其他系统则不支持这项特性。然而,一种叫做presharding的技术对此是有帮助的。
Redis有两种类型分区。假设有4个Redis实例R0,R1,R2,R3和类似user:1,user:2这样表示用户的多个key,对既定的key有多种不同方式来选择这个key存放在哪个实例中。也就是说,有不同的系统来映射到某个key到Redis服务。
(1)范围分区
最简单的分区方式是按范围分区,就是映射一定范围的对象到特定的Redis实例。
如:ID从0到10000的用户会保存到实例R0,ID从10001到20000的用户会保存到R1,一次类推。
这种方式是可行的,并且在实际中使用,不足就是要有一个区间范围到实例的映射表。这个表要被管理,同时还需要各种对象的映射表,通常对Redis来说并非是好的办法。
(2)哈希分区
另一种分区方法是hash分区。这对任何key都适用,也无需是object_name:这种形式,
如:① 用一个hash函数将key转换为一个数字,比如使用crc32 hash函数。对key foobar 执行crc32(foobar)会输出类似93024922的整数。
② 对这个整数取模,将其转化为0-3之间的数字,就可以将这个整数映射到4个Redis实例中的一个了。93024922 % 4 = 2,就是说key foobar 应该被存在实例R2中。
详见https://www.runoob.com/redis/redis-java.html
标签:默认 ref sha use cond alt img redis 集群
原文地址:https://www.cnblogs.com/willncy/p/12317125.html