标签:source 是什么 三台 理解 must mit 根据 资源 org
下面我们来看一下spark的运行模式,根据上一篇博客我们知道spark的运行模式分为以下几种:local、standalone、hadoop yarn。我们说本地开发最好用local模式,直接搭建一个spark环境就可以跑了,因为测试的话本地是最方便的。standalone,用的比较少。hadoop yarn,这个是用的最多的,用spark的公司至少有70%是用yarn这个模式的。yarn是一个资源管理器,我们后面会说。下面我们就来讲解这几种运行模式。
这个模式应该是最熟悉的模式了,因为我们之前介绍RDD的时候用的就是这个模式,所以我们看到在编写代码的时候,进行测试使用local模式是足够的。
我们之前用的pyspark shell,这个是为了方便本地测试的,以及我们还知道了如何向spark提交一个作业,使用spark-submit,我们当时是这么提交的:
spark-submit --master local[*] --name 古明地觉 xxx.py如果你有自己写的依赖,那么把依赖打包成一个zip或者egg,spark-submit --master local[*] --name 古明地觉 --py-files xxx.egg xxx.py arg1 arg2,如果还需要从命令行传入参数,那么跟在用于启动的py文件的后面就可以了。当然我们启动pyspark shell的时候也可以指定--master和--name,我们说使用哪种运行模式其实就是通过--master来指定的,local[*]就是本地模式,默认使用全部的核。如果不指定--master,那么默认是local所以local模式是比较简单的,一般在测试的时候使用。先取出少量数据,然后先把功能跑通再说。其实不管是什么模式,我们代码是不需要变的,只是换了一种模式运行,这也是spark非常方便的地方。
standalone是spark装好之后自带的模式,怎么搭建standalone了。首先你要保证你有多台机器,对于standalone模式,肯定有一台机器是master,剩下的属于worker,下面我们就来演示如何搭建。
首先在SPARK_HOME目录的conf目录下有一个spark_env.sh,打开。
# 这里面的代码全部被注释掉了,我们需要什么直接拷贝在底下即可
# 这个是JAVA_HOME,我之前没有说spark环境怎么搭,因为这些网上都有,所以这里再提一遍
# 这个配置jdk
export JAVA_HOME=/opt/java/jdk1.8.0_221/
# 这里的是我们的关键,我们导出了SPARK_MASTER_HOST和SPARK_MASTER_PORT
# 那么spark001就是我们集群的master,或者你输入ip也可以
export SPARK_MASTER_HOST=spark001
export SPARK_MASTER_PORT=7077
# 这个是我们在使用spark-submit的时候保证执行的python解释器为python3
export PYSPARK_PYTHON=/usr/bin/python3然后再打开slaves,我们spark001是我们当前的master,假设我们还有三台机器,分别是spark002、spark003、spark004,那么就直接把主机名或者ip地址写上去即可
spark001
spark002
spark003
spark004显然对master机器就已经配置好了,然后把这个spark目录完整的拷贝到其它三台机器的相同目录下即可。是的,只要把master配置好,那么其它的机器只需要得到一份拷贝即可。那么spark集群在启动之后,读取spark-env.sh就知道master是我们的spark001,而根据slaves知道spark002、spark003、spark004是worker,那么内部就会进行通信之类的。
但是我这里只有一台机器,因此我们就用一台机器模拟standalone,配置方式是一样的,如果是一台机器的话,就这么配。
#### spark-env.sh ####
export SPARK_MASTER_HOST=localhost
export SPARK_MASTER_PORT=7077
#### slaves ####
localhost然后我们就可以启动spark集群了,在sbin目录。我们先执行start-master.sh,然后执行start-slaves.sh,不过更简单的,我们直接执行start-all.sh也是可以的。
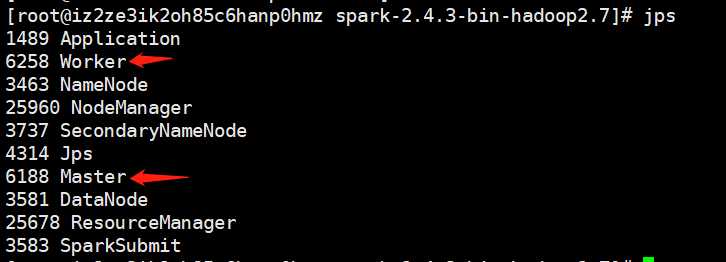
输入jps,如果出现了master和worker,说明启动成功了。
除此之外,我们还可以通过webUI查看,spark集群的端口默认是8080,如果被占用会尝试+1,变成8081,所以端口不是8080也不要觉得奇怪。
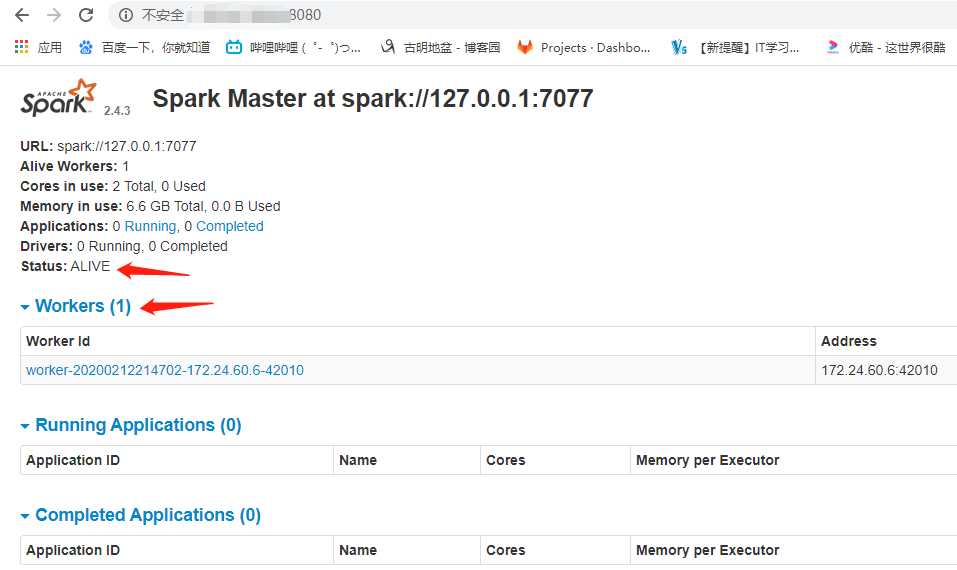
我这里已经启动了,但是由于是一台机器,所以worker只有一个,它既是worker也是master。
关于端口的问题,我们在上一篇博客中看到了4040,那么是查看pyspark任务的端口;图片上面还写了大大的7077,这个就是我们在spark-env.sh中设置的端口,这个端口指定的master和worker进行rpc通信的时候使用的端口(如果我们在spark-env.sh中不设置,那么默认也是7077)。不同机器要进行访问肯定要指定ip和端口;然后就是我们这里的8080,这个是spark集群的webUI端口。
下面我们来走一个,pyspark --master spark://127.0.0.1:7077,我们看到--master指定的不再是local了,而是我们集群的地址。
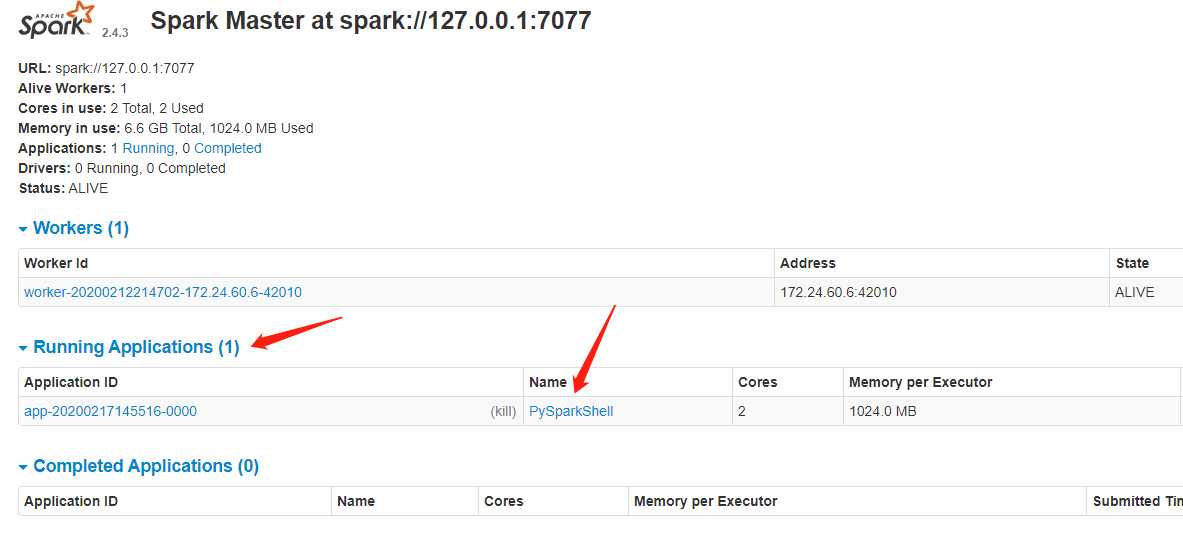
我们看到运行的应用多了一个,因为我们以standalone的模式启动了pyspark shell。
好啦,我们知道以standalone模式启动pyspark shell,那么如何使用submit提交作业呢?答案很简单,把使用local模式提交作业的命令copy下来,把local[*]改成我们的spark集群:spark://127.0.0.1:7077就完事了,非常简单吧,这里就不演示了。另外需要注意的是:如果使用standalone模式测试的时候需要读取本地文件,那么你要保证所有节点在指定目录下都存在这样的一个文件。
最后我们来看一下yarn模式,我们之前说了yarn是使用spark的公司采用的最多的一个模式。使用yarn模式的时候,spark充当一个客户端,它需要做的事情就是提交作业到yarn上去执行。那么yarn它和standalone模式之前有什么区别呢?
yarn:你只需要一个节点,然后提交作业即可,这个是不需要spark集群的(不需要启动master和worker)。standalone:你的spark集群上每个节点都需要部署spark那么如何把作业提交到yarn上运行呢?很简单,直接--master local换成--master yarn即可。
# 1.py
from pyspark import SparkContext
sc = SparkContext()
rdd = sc.parallelize([1, 2, 3, 4, 5])
print(rdd.map(lambda x: x + 1).collect())spark-submit --master yarn --name satori 1.py
[root@iz2ze3ik2oh85c6hanp0hmz ~]# spark-submit --master yarn --name satori 1.py
Exception in thread "main" org.apache.spark.SparkException: When running with master 'yarn' either HADOOP_CONF_DIR or YARN_CONF_DIR must be set in the environment.
at org.apache.spark.deploy.SparkSubmitArguments.error(SparkSubmitArguments.scala:657)
at org.apache.spark.deploy.SparkSubmitArguments.validateSubmitArguments(SparkSubmitArguments.scala:290)
at org.apache.spark.deploy.SparkSubmitArguments.validateArguments(SparkSubmitArguments.scala:251)
at org.apache.spark.deploy.SparkSubmitArguments.<init>(SparkSubmitArguments.scala:120)
at org.apache.spark.deploy.SparkSubmit$$anon$2$$anon$1.<init>(SparkSubmit.scala:911)
at org.apache.spark.deploy.SparkSubmit$$anon$2.parseArguments(SparkSubmit.scala:911)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:81)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:924)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:933)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
[root@iz2ze3ik2oh85c6hanp0hmz ~]# 但是我们看到报错了,根据报错信息我们知道,如果想提交到yarn上去执行,那么必须配置HADOOP_CONF_DIR或者YARN_CONF_DIR,意思就是hadoop配置文件所在的目录,那么我们拷贝一下呗,然后指定到spark-env.sh里面去。
export HADOOP_CONF_DIR=/opt/hadoop/hadoop-2.6.0-cdh5.8.5/etc/hadoop然后再来启动,但是注意哈,yarn必须要已经启动才可以。
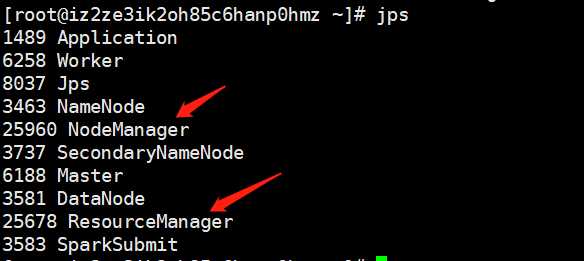
输入jps,要能看到NodeManager和ResourceManager。
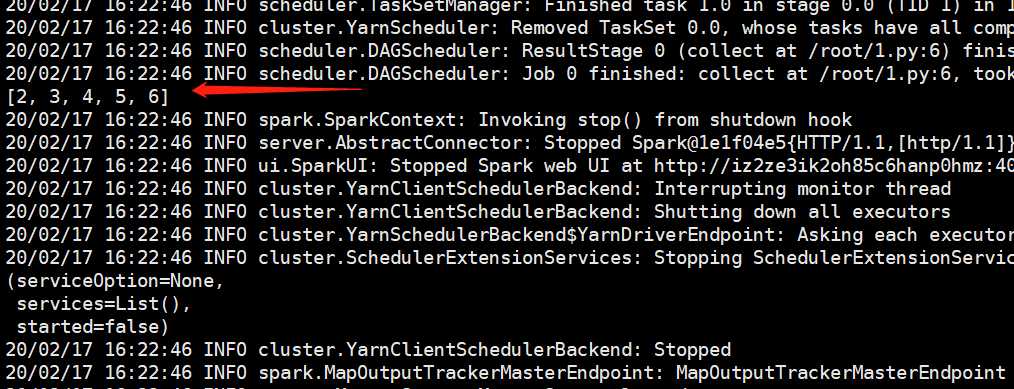
输出的内容非常非常多,但是我们已经看到了输出的结果,说明提交到yarn上是执行成功了的。会比较慢,因为需要到yarn上申请资源等一系列操作。
关于提交到yarn上执行作业,还有两种模式,--deploy-mode client,--deploy-mode cluster。它们有什么区别的?
client:提交作业的进程是不能停止的,否则作业就挂了cluster:提交完作业,进程就可以断开了,因为driver是运行在am里面的。这里面出现了一些概念,我们会在后面的博客中说,以及spark的架构等等。目前不需要理解这么多概念性的东西,学习起来会非常的累,所以我们之前介绍RDD的时候直接使用的local模式,而且还是使用的是交互式这种模式。因为RDD的语法跟你用的什么模式没有关系,我们既然学习语法就学习语法,涉及到的概念的东西越少越好。再比如这里的运行模式,我们就只需要知道有这三种运行模式、以及怎么指定即可。像yarn、driver、Manager、Application等等等等概念性的东西我们会采用图文的形式单独说。目前只需要知道,运行模式不同对代码没有影响,我们的代码只需要写一份,需要什么模式,直接--master指定即可。如果指定yarn,还可以指定--deploy-mode。
标签:source 是什么 三台 理解 must mit 根据 资源 org
原文地址:https://www.cnblogs.com/traditional/p/12322506.html