标签:编程 读取字符串 ima 字符串 取字符串 内存 display orm ice
1.和数据结构相关的序列:
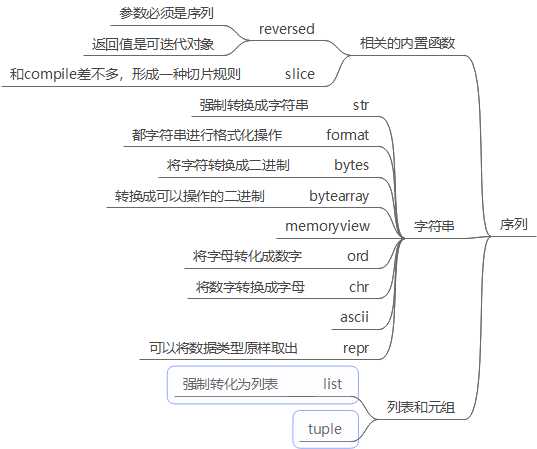
1.1reversed对列表进行反转(次操作不会该改变原列表,而且生成一个新的迭代器)

l=[1,4,6,8,9] l1=l.reverse() #列表里的反转没有返回值 print(l1,l) #列表里的反转会改变原来的数据 结果为 None [9, 8, 6, 4, 1]
l=[1,4,6,8,9] l1=reversed(l) #反转有返回值返回一个迭代器 如果返回为一个内存地址则为迭代器 print(l1,l) #列表里的反转会不会改变原来的数据 print(list(l1)) 结果为 <list_reverseiterator object at 0x000001DEBE75B080> [1, 4, 6, 8, 9] [9, 8, 6, 4, 1]
1.2slice对可迭代对象进行切片得到是切片的范围
l=[1,4,6,8,9] li=slice(1,3) print(l[li]) print(l[1:3]) 结果为 [4, 6] [4, 6]
1.3format前面学习了3种format格式化的方式,现在补充一种:
print(format(‘test‘, ‘>20‘))#开辟20个内存空间字符串再最右边 print(format(‘test‘, ‘<20‘))#开辟20个内存空间字符串再最左边 print(format(‘test‘, ‘^20‘))#开辟20个内存空间字符串再最中间边 结果为 test test test
· 1.4bytes 将内容的类型转换成bytes类型
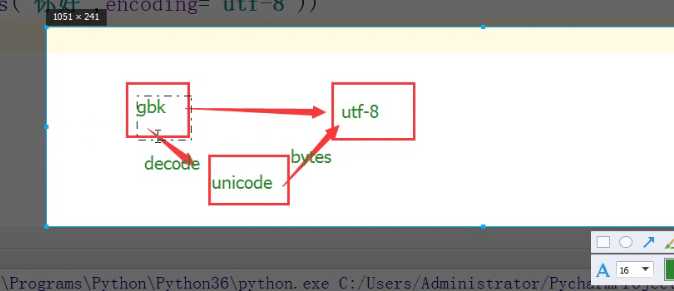
列:我拿到的是gbk编码的,我想转成utf-8编码:
print(bytes(‘你好‘,encoding=‘utf-8‘)) #因为内存种默认编码方式是unicode次操作是将unicode转为utf-8的bytes print(bytes(‘你好‘,encoding=‘gbk‘)) #因为内存种默认编码方式是unicode次操作是将unicode转为gbk的bytes 结果为 b‘\xe4\xbd\xa0\xe5\xa5\xbd‘ b‘\xc4\xe3\xba\xc3‘
1,我拿到的是gbk类型的数据,像转换成utf-8类型的进行的操作为
1.5bytearray(得到的二进制放入类表中,并且可以操作:)注:网络编程中只能传二进制,照片和视频也是只能以二进制来进行存储,html网页爬取是也是要编码方式的:
b_array=bytearray(‘你好‘,encoding=‘utf-8‘) print(b_array) print(b_array.decode(‘utf-8‘)) #进行解码操作 print(b_array[1]) print(b_array[0:3].decode(‘utf-8‘)) #可以读取字符串中想要读取的字符 print(b_array[1]+1) 结果为 bytearray(b‘\xe4\xbd\xa0\xe5\xa5\xbd‘) 你好 189 你 190
标签:编程 读取字符串 ima 字符串 取字符串 内存 display orm ice
原文地址:https://www.cnblogs.com/ab461087603/p/12322572.html
