标签:lsp default php 类设计 特性 之间 goroutine nbsp 程序
Go 1.3 的 sync 包中加入一个新特性:Pool。
官方文档可以看这里 http://golang.org/pkg/sync/#Pool
这个类设计的目的是用来保存和复用临时对象,以减少内存分配,降低CG压力。
|
1
2
3
4
|
type Pool func (p *Pool) Get() interface{} func (p *Pool) Put(x interface{}) New func() interface{} |
Get 返回 Pool 中的任意一个对象。
如果 Pool 为空,则调用 New 返回一个新创建的对象。
如果没有设置 New,则返回 nil。
还有一个重要的特性是,放进 Pool 中的对象,会在说不准什么时候被回收掉。
所以如果事先 Put 进去 100 个对象,下次 Get 的时候发现 Pool 是空也是有可能的。
不过这个特性的一个好处就在于不用担心 Pool 会一直增长,因为 Go 已经帮你在 Pool 中做了回收机制。
这个清理过程是在每次垃圾回收之前做的。垃圾回收是固定两分钟触发一次。
而且每次清理会将 Pool 中的所有对象都清理掉!
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
package mainimport( "sync" "log")func main(){ // 建立对象 var pipe = &sync.Pool{New:func()interface{}{return "Hello, BeiJing"}} // 准备放入的字符串 val := "Hello,World!" // 放入 pipe.Put(val) // 取出 log.Println(pipe.Get()) // 再取就没有了,会自动调用NEW log.Println(pipe.Get())}// 输出2014/09/30 15:43:30 Hello, World!2014/09/30 15:43:30 Hello, BeiJing |
摘自:http://www.nljb.net/default/sync.Pool/
众所周知,go 是自动垃圾回收的(garbage collector),这大大减少了程序编程负担。但 gc 是一把双刃剑,带来了编程的方便但同时也增加了运行时开销,使用不当甚至会严重影响程序的性能。因此性能要求高的场景不能任意产生太多的垃圾(有gc但又不能完全依赖它挺恶心的),如何解决呢?那就是要重用对象了,我们可以简单的使用一个 chan 把这些可重用的对象缓存起来,但如果很多 goroutine 竞争一个 chan性能肯定是问题.....由于 golang 团队认识到这个问题普遍存在,为了避免大家重造车轮,因此官方统一出了一个包 Pool。但为什么放到 sync 包里面也是有的迷惑的,先不讨论这个问题。
先来看看如何使用一个 pool:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
package main import( "fmt" "sync" ) func main() { p := &sync.Pool{ New: func() interface{} { return 0 }, } a := p.Get().(int) p.Put(1) b := p.Get().(int) fmt.Println(a, b) } |
上面创建了一个缓存 int 对象的一个 pool,先从池获取一个对象然后放进去一个对象再取出一个对象,程序的输出是 0 1。创建的时候可以指定一个 New 函数,获取对象的时候如何在池里面找不到缓存的对象将会使用指定的 new 函数创建一个返回,如果没有 new 函数则返回 nil。用法是不是很简单,我们这里就不多说,下面来说说我们关心的问题:
上面我们可以看到 pool 创建的时候是不能指定大小的,所有 sync.Pool 的缓存对象数量是没有限制的(只受限于内存),因此使用 sync.pool 是没办法做到控制缓存对象数量的个数的。另外 sync.pool 缓存对象的期限是很诡异的,先看一下 src/pkg/sync/pool.go 里面的一段实现代码:
|
1
2
3
|
func init() { runtime_registerPoolCleanup(poolCleanup) } |
可以看到 pool 包在 init 的时候注册了一个 poolCleanup 函数,它会清除所有的 pool 里面的所有缓存的对象,该函数注册进去之后会在每次 gc 之前都会调用,因此 sync.Pool 缓存的期限只是两次 gc 之间这段时间。例如我们把上面的例子改成下面这样之后,输出的结果将是 0 0。正因 gc 的时候会清掉缓存对象,也不用担心 pool 会无限增大的问题。
|
1
2
3
4
5
|
a := p.Get().(int) p.Put(1) runtime.GC() b := p.Get().(int) fmt.Println(a, b) |
这是很多人错误理解的地方,正因为这样,我们是不可以使用sync.Pool去实现一个socket连接池的。
如何在多个 goroutine 之间使用同一个 pool 做到高效呢?官方的做法就是尽量减少竞争,因为 sync.pool 为每个 P(对应 cpu,不了解的童鞋可以去看看 golang 的调度模型介绍)都分配了一个子池,如下图:
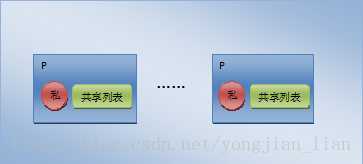
当执行一个 pool 的 get 或者 put 操作的时候都会先把当前的 goroutine 固定到某个P的子池上面,然后再对该子池进行操作。每个子池里面有一个私有对象和共享列表对象,私有对象是只有对应的 P 能够访问,因为一个 P 同一时间只能执行一个 goroutine,因此对私有对象存取操作是不需要加锁的。共享列表是和其他 P 分享的,因此操作共享列表是需要加锁的。
获取对象过程是:
1)固定到某个 P,尝试从私有对象获取,如果私有对象非空则返回该对象,并把私有对象置空;
2)如果私有对象是空的时候,就去当前子池的共享列表获取(需要加锁);
3)如果当前子池的共享列表也是空的,那么就尝试去其他P的子池的共享列表偷取一个(需要加锁);
4)如果其他子池都是空的,最后就用用户指定的 New 函数产生一个新的对象返回。
可以看到一次 get 操作最少 0 次加锁,最大 N(N 等于 MAXPROCS)次加锁。
归还对象的过程:
1)固定到某个 P,如果私有对象为空则放到私有对象;
2)否则加入到该 P 子池的共享列表中(需要加锁)。
可以看到一次 put 操作最少 0 次加锁,最多 1 次加锁。
由于 goroutine 具体会分配到那个 P 执行是 golang 的协程调度系统决定的,因此在 MAXPROCS>1 的情况下,多 goroutine 用同一个 sync.Pool 的话,各个 P 的子池之间缓存的对象是否平衡以及开销如何是没办法准确衡量的。但如果 goroutine 数目和缓存的对象数目远远大于 MAXPROCS 的话,概率上说应该是相对平衡的。
总的来说,sync.Pool 的定位不是做类似连接池的东西,它的用途仅仅是增加对象重用的几率,减少 gc 的负担,而开销方面也不是很便宜的。
摘自:http://blog.csdn.net/yongjian_lian/article/details/42058893
标签:lsp default php 类设计 特性 之间 goroutine nbsp 程序
原文地址:https://www.cnblogs.com/-wenli/p/12325248.html