标签:频繁 带来 案例 block obs 数据集 随机 信用卡 dep
当数据缺失时出现的问题:
缺失机制:
如何假设一个缺失的机制:
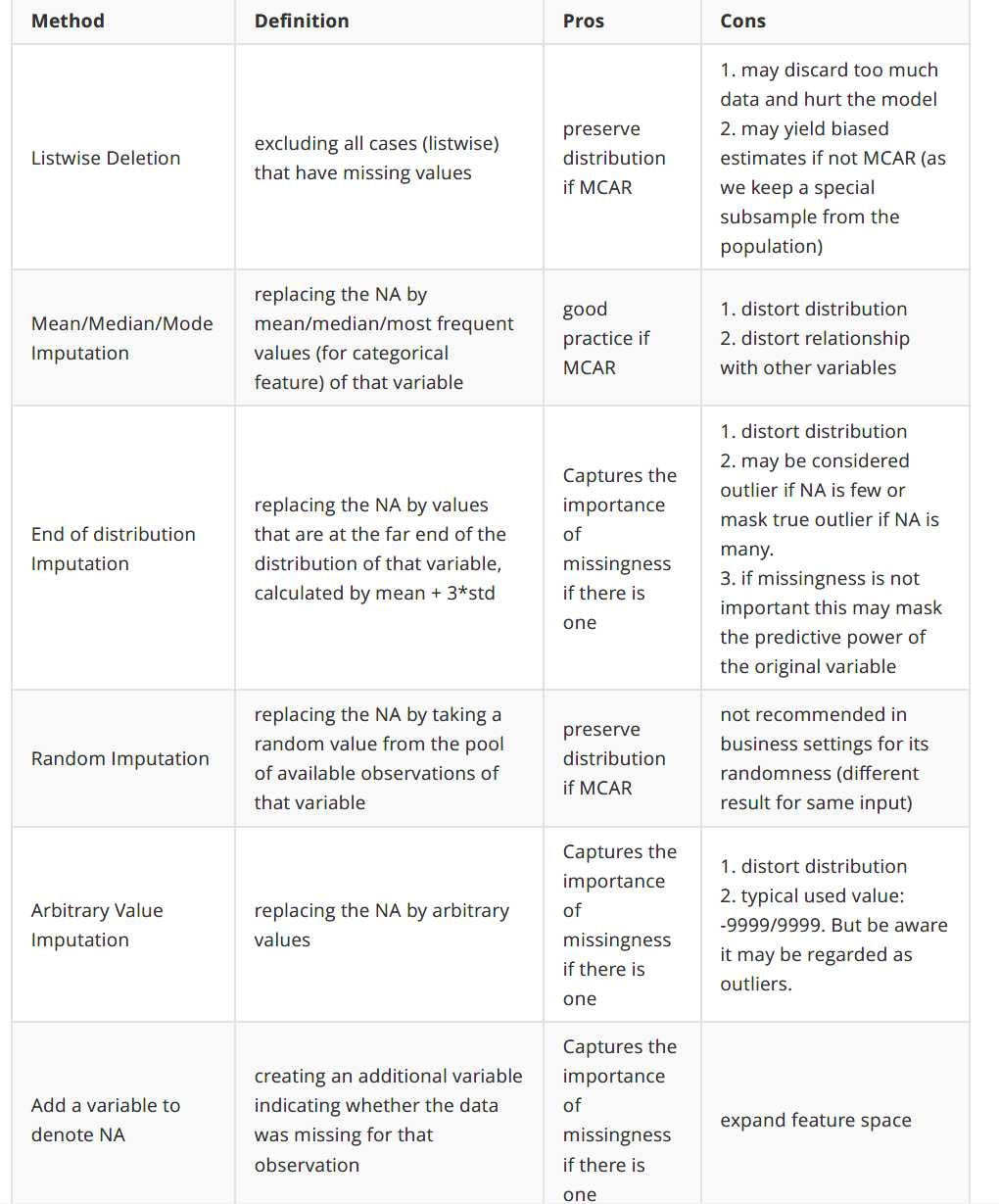
如何处理Missing Data:
在实际环境中,当很难确定缺失的机制或几乎没有时间深入研究每个缺失的变量时,最流行的方法是采用:

2.Outliers
离群值是一种观测值,它与其他观测值相差甚远,以至于使人怀疑它是由另一种机制引起的。根据上下文,异常值要么值得特别注意,要么应该完全忽略。例如,信用卡上不寻常的交易通常是欺诈活动的标志,而高度的一个人的1600厘米很可能是由于测量误差,应该被过滤掉或用其他值代替
离群值的问题:
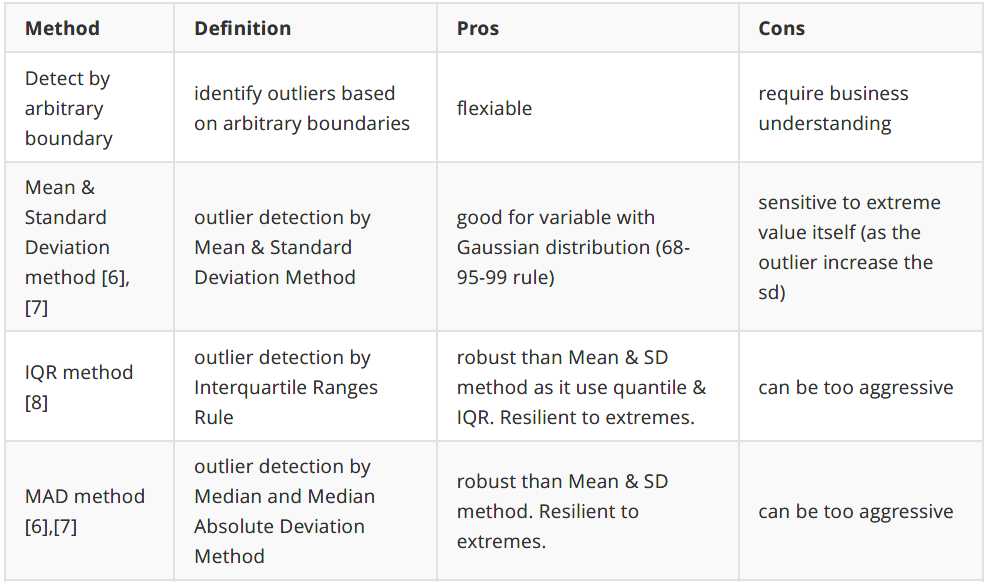
离群点检测:
应该根据上下文如何定义和对这些异常值做出反应。你的反应的意义应该由潜在的上下文决定,而不是数字本身
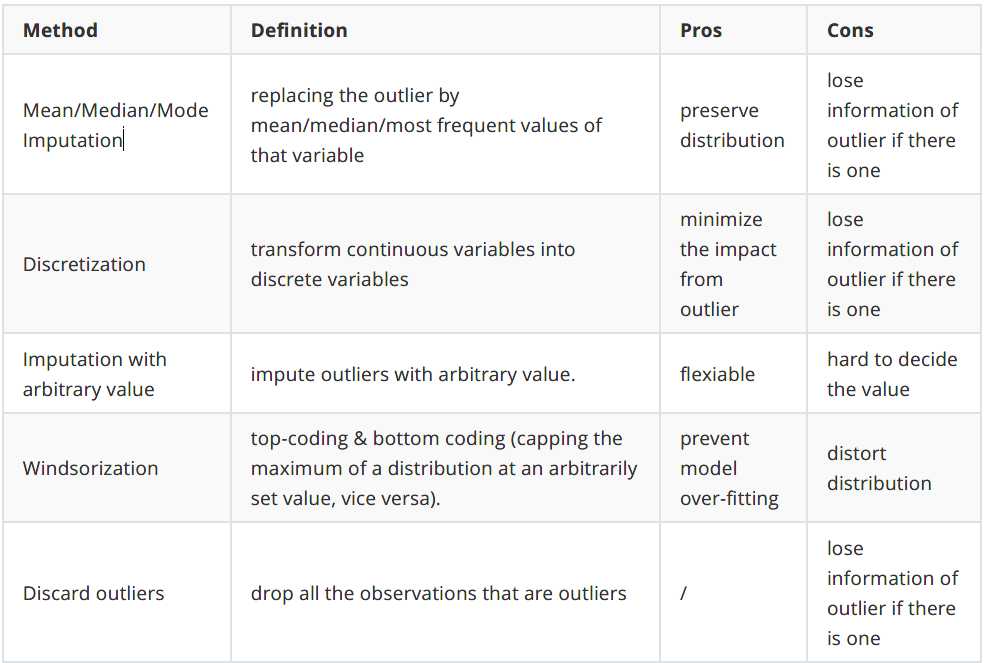
离群点处理:
很少出现的值,在某些情况下,罕见值(如离群值)可能包含有价值的数据集信息,因此需要特别注意。例如,交易中罕见的值可能表示欺诈。而其他情况下,罕见值或许应该去除或者用其他值代替。
罕见值的问题:
如何处理罕见值:

如果一个特征是用来表示类别/定性的(categorical),而且这个特征的可能值非常多,通常用0-n的离散整数来表示,那么它就是高基数类别特征
高基数的问题:
如何处理高基数:
标签:频繁 带来 案例 block obs 数据集 随机 信用卡 dep
原文地址:https://www.cnblogs.com/ziwh666/p/12325910.html