标签:idt ash one 验证 scores gdc metrics 实例 cross
ROC曲线
ROC曲线是二元分类器中常用的工具,它的全称是 Receiver Operating Characteristic,接收者操作特征曲线。它与precision/recall 曲线特别相似,但是它画出的是true positive rate(recall的另一种叫法)对应false positive rate (FPR)的图。FPR是“负实例”(negative instances) 被错误地分类成“正实例”(positive)的比率。它等同于 1 减去true negative rate(TNR,“负实例”被正确地分类成“负实例”的比率)。TNR也被称为特异性(specificity)。所以ROC曲线画出的也是 sensitivity(也就是recall)vs (1 – specificity)。
为了画出ROC 曲线,我们首先需要计算在不同阈值下的TPR与FPR值,使用roc_curve() 方法:
from sklearn.metrics import roc_curve fpr, tpr, thresholds = roc_curve(y_train_5, y_scores)
然后使用matplotlib 画出FPR对应TPR的图:
def plot_roc_curve(fpr, tpr, label=None): plt.plot(fpr, tpr, linewidth=2, label=label) plt.plot([0, 1], [0, 1], ‘k--‘) #加上虚线对角线 plot_roc_curve(fpr, tpr) plt.show()
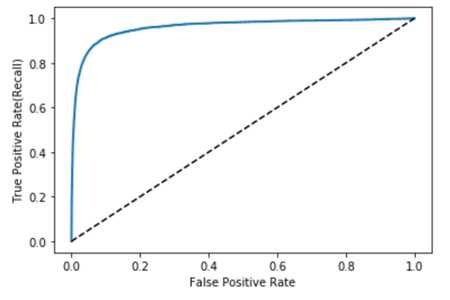
同样,这里也有一个折中,更高的recall(TPR)也就意味着分类器会产生更多的false positives(FPR)。虚线代表的是一个完全随机的分类器的ROC曲线,一个好的分类器的ROC曲线要尽可能地远离这条虚线,并要尽可能地接近左上角。
一种比较分类器的办法是评估AUC(area under the curve,曲线下方面积),一个完美的分类器的ROC AUC应等于1,而一个完全随机的分类器的ROC AUC则为0.5。sk-learn提供了一个方法用于计算ROC AUC:
from sklearn.metrics import roc_auc_score
roc_auc_score(y_train_5, y_scores) >0.9604938554008616
由于ROC曲线与precision/recall(或者PR)曲线非常相似,所以大家可能会好奇到底使用哪个。根据经验,任何时候当positive 类别很少、或是在关注false positive甚于false negative时,使用PR曲线。反之则使用ROC曲线。例如,我们看一下上一个ROC曲线(以及ROC AUC分数),我们可能认为分类器非常好。但是这主要是因为数据集中positive instances(也就是数字5)较少,相对于“非5”少很多。相反,从PR曲线来看,我们可以看到其实这个分类器还有提升的空间(PR曲线应该尽可能地靠近右上角)。
我们接下来训练一个RandomForestClassifier,并对比它的ROC 曲线以及ROC AUC分数。首先,我们需要得到训练集中每条数据的分数。但是RandomForestClassifier类并没有提供decision_function() 的方法,它提供的是一个predict_proba() 方法。一般sk-learn中的分类器中,基本都是提供的这两个方法中的其一。predict_proba() 方法返回一个数组,里面每行是一条数据,每列是一个类别,里面的数值就是这条数据属于这个类别的概率(例如,某条数据有70%的概率代表数字5)。
from sklearn.ensemble import RandomForestClassifier forest_clf = RandomForestClassifier(random_state=42) y_probas_forest = cross_val_predict(forest_clf, X_train, y_train_5, cv=3, method=‘predict_proba‘) y_probas_forest >array([[0.1, 0.9], [1. , 0. ], [0.9, 0.1], ..., [0. , 1. ], [1. , 0. ], [1. , 0. ]])
但是为了画出ROC曲线,我们需要的是分数(scores),并不是概率。一个简单的办法是使用positive类的概率作为分数:
y_scores_forest = y_probas_forest[:, 1]
fpr_forest, tpr_forest, thresholds_forest = roc_curve(y_train_5, y_scores_forest)
现在我们已经有了分数,可以画出ROC曲线(最好是也画出第一个分类器的ROC曲线作为对比):
plt.plot(fpr, tpr, ‘b:‘, label=‘SGD‘) plot_roc_curve(fpr_forest, tpr_forest, ‘Random Forest‘) plt.legend(loc=‘lower right‘) plt.show()
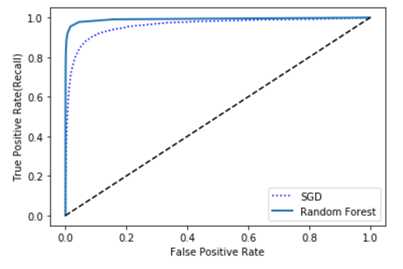
如上图所示,RandomForestClassifier的ROC曲线看起来比SGDClassifier的更好:它更接近于左上角。显而易见,它的ROC AUC分数也会更高:
roc_auc_score(y_train_5, y_scores_forest)
>0.9920527492698306
如果进一步计算它的precision与recall的话,可以分别得到98% 的precision,以及82%的recall:
y_train_forest_pred = cross_val_predict(forest_clf, X_train, y_train_5, cv=3) precision_score(y_train_5, y_train_forest_pred) >0.986046511627907 recall_score(y_train_5, y_train_forest_pred) >0.8212506917542889
相较上一个分类器,有了很大的提升。
至此,希望大家已经了解了:
在二元分类器完成之后,我们之后接下来继续看一下多类别分类,让分类器不仅仅是只区分数字5。
标签:idt ash one 验证 scores gdc metrics 实例 cross
原文地址:https://www.cnblogs.com/zackstang/p/12327517.html