标签:cli link enc mpi xpath ade name mic csv
这篇博客介绍怎么爬取猫眼top100的排名,网址,评分等。使用的是爬虫技术最基础的requests请求加re(正则)提取。
有时候我们看电影会不知道看什么电影比较好,一般打开电影排名,还得一下下的点击到电影排行页面。所以就有了这个爬虫,直接就能得到猫眼的电影排名和他的网址,岂不乐哉。
我们先打开到猫眼的top100页面:https://maoyan.com/board/4?
然后点击到第二页:https://maoyan.com/board/4?offset=10
点击第三页:https://maoyan.com/board/4?offset=20
然后我们就发现只需改变网址后面的offset值就能达到翻页效果,因为编程语言第一个数字是从0开始的,所以直接i*10写个循环就饿能翻页了。
代码:
import requests, re, json from requests.exceptions import RequestException from my_fake_useragent import UserAgent def get_one_page(url): headers = { ‘User-Agent‘: UserAgent().random() } try: reponse = requests.get(url, headers=headers) if reponse.status_code == 200: print("ok!") return None except RequestException: return None def main(offset): url = ‘https://maoyan.com/board/4?offset=‘ + str(offset) get_one_page(url) if __name__ == ‘__main__‘: for i in range(10): main(i * 10)
运行结果:
C:\Users\User\AppData\Local\Programs\Python\Python37\python.exe G:/Python/code/requeats/try.py ok! ok! ok! ok! ok! ok! ok! ok! ok! ok!
看来十个网址都能请求到,然后进行下一步。
一般使用正则时,我喜欢查看源码来写re,因为源码是网页请求时真正的代码,F12开发者模式下看到的井井有序的代码是进过CSS渲染等后期处理好了的格式,所以两者有些不同。
我们右键点查看源码。然后CTRL+F查找排行第一的“霸王别姬”。我们能看到这一串代码:
<i class="board-index board-index-1">1</i> <a href="/films/1203" title="霸王别姬" class="image-link" data-act="boarditem-click" data-val="{movieId:1203}">
然后我们代开霸王别姬的页面,他的URL是:https://maoyan.com/films/1203,我们发现他的后半部分/films/1203也在所截取的代码中。
这样我们就可以构造一个re:“>(.*?)</i>\s*<a href="(.*?)" title="(.*?)" class="image-link”,把我们需要的部分改为(,*?),因为代码有换行的地方,所以要在回车部位加上\s*。
PS:正则的具体用法我们不例举。
最后在写入一个TXT文件。
import requests, re, json from requests.exceptions import RequestException from my_fake_useragent import UserAgent def get_one_page(url): headers = { ‘User-Agent‘: UserAgent().random() } try: reponse = requests.get(url, headers=headers) if reponse.status_code == 200: return reponse.text return None except RequestException: return None def parse_one_page(html): pattern = re.compile(‘>(.*?)</i>\s*<a href="(.*?)" title="(.*?)" class="image-link‘) items = re.findall(pattern, html) for item in items: yield { ‘index‘: item[0], ‘image‘: ‘http://maoyan.com‘ + item[1], ‘title‘: item[2] } def write_to_file(content): with open(‘maoyan.txt‘, ‘a‘, encoding=‘UTF-8‘) as f: f.write(json.dumps(content, ensure_ascii=False) + ‘\n‘) def main(offset): url = ‘https://maoyan.com/board/4?offset=‘ + str(offset) html = get_one_page(url) for item in parse_one_page(html): print(item) write_to_file(item) if __name__ == ‘__main__‘: for i in range(10): main(i * 10)
一般我的规律是能用xpath用xpath,其次用re,再其次用bs4。他们的写法都按照xpath的写法一样,一层一层的找下去。但是一般的爬虫,我们使用正则完全没必要那么麻烦,直接找到要爬取地方,复制,把要提取部位改为(,*?)就完全能满足普通爬虫的需要,而且这样做也很快捷。
上面我只是写入了TXT文件,如有需要可以改为CSV格式等。
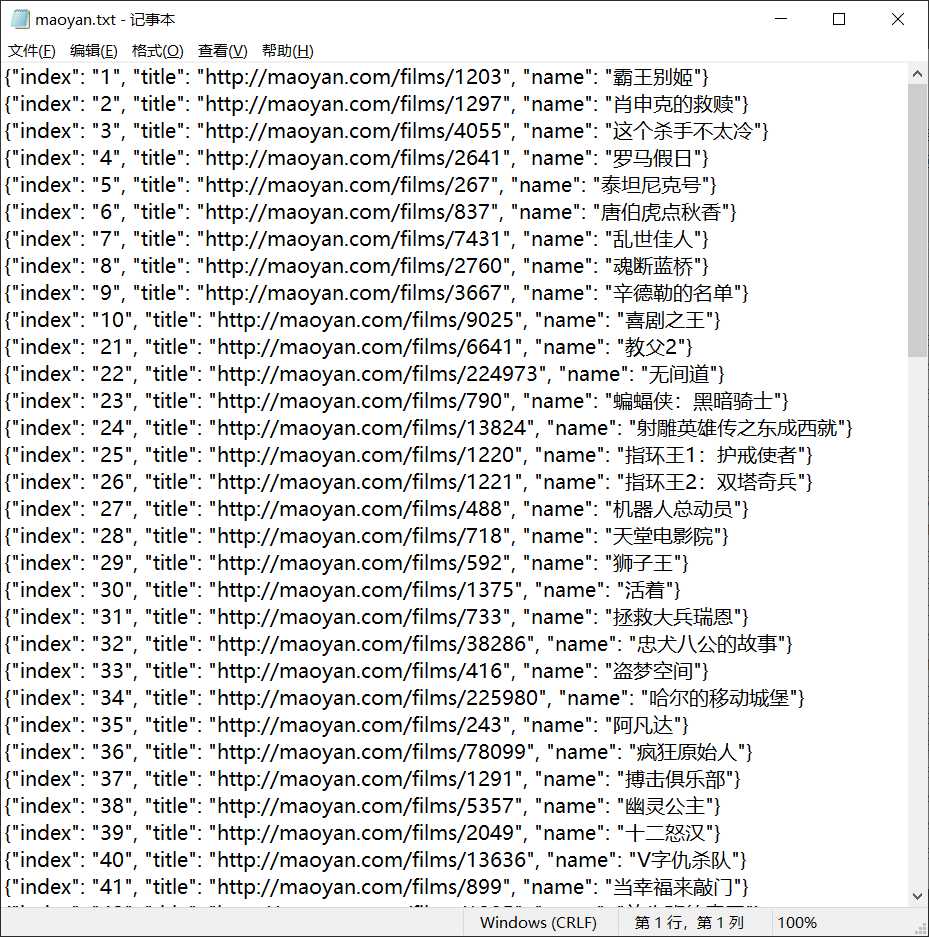
这里我只提取了排名,网址和电影名。如果有其他爬取类容,请自行添加。
requests+re(正则)之猫眼top100排名信息爬取
标签:cli link enc mpi xpath ade name mic csv
原文地址:https://www.cnblogs.com/zj666666/p/12330820.html