标签:保存 mamicode 选择 lib 划分数 提高效率 参数 引入 机器学习算法
Scikit-learn(sklearn)是机器学习中的第三方模块,封装了常用的机器学习算法,涉及回归、降维、分类以及聚类等,提供python接口。
虽然sklearn容纳的算法众多,但使用其中大多数算法的模式(套路)都是一样的,一般流程如下:
1 引入相关数据(包括训练集与测试集),其实Sklearn也自带一些小型数据集,可以用来测试检验各种算法,方便快捷;
2 选择算法进行训练,若模型带有超参数,可以运用交叉验证方法调参;
3 训练完成后进行新数据预测,并可以通过引入MatPlotLib等库展示数据;
4 将已训练好的模型保存,避免往后用到时再重复训练。
sklearn附带了一些小型常用数据集,调取方法如下:
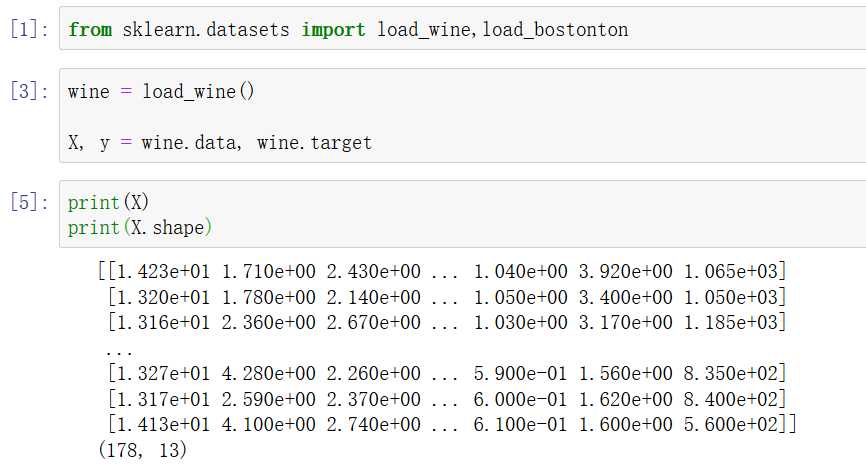
调取其它数据集的方法和上图中的例子类似。
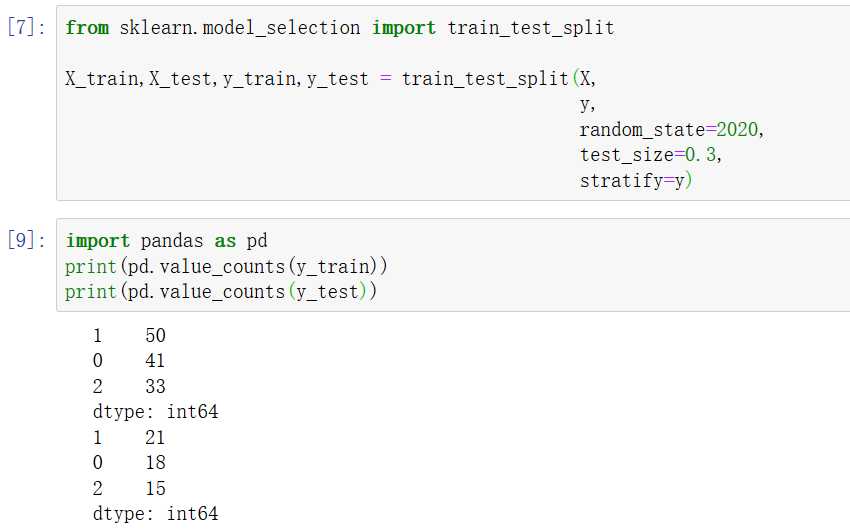
注意:为了使实验具有可重复性,在划分数据集时要设定随机数种子,以确保重复多次运行代码时得到的训练集与测试集是一样的;此外,为了平衡训练集与测试集中各类别的比例(特别是在分类任务中),常常需要分层划分数据集,这与统计学中分层抽样的原理一样。
常见的标准化方式有:离差标准化,高斯标准化。
离差标准化将所有数据变换到区间[0,1]中,高斯标准化将数据转成高斯分布(正态分布)形态:

为了避免重复训练模型,同时方便后续直接调取已有模型,可以将训练好的模型保存:
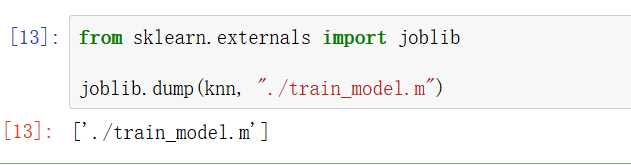
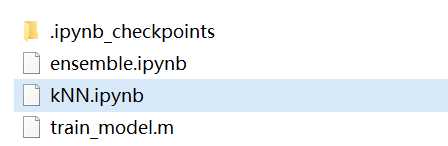
上图中,将knn训练完成的模型保存到代码文件的同目录下,如下图(代码文件名为:kNN.ipynb,模型名为:train_model.m):
若要加载已有模型,操作如下:

标签:保存 mamicode 选择 lib 划分数 提高效率 参数 引入 机器学习算法
原文地址:https://www.cnblogs.com/pythonfl/p/12332898.html