标签:des style blog class code c
遇到的问题:
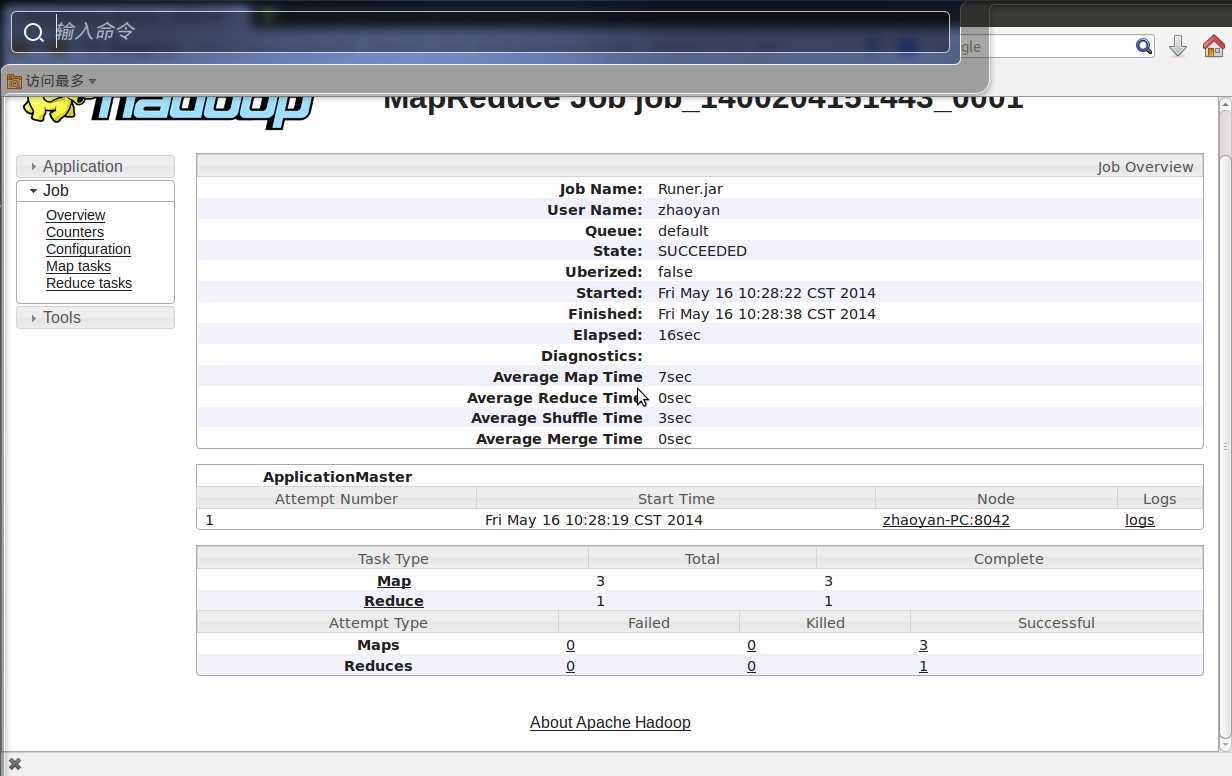
当点击上面的logs时,会出现下面问题:
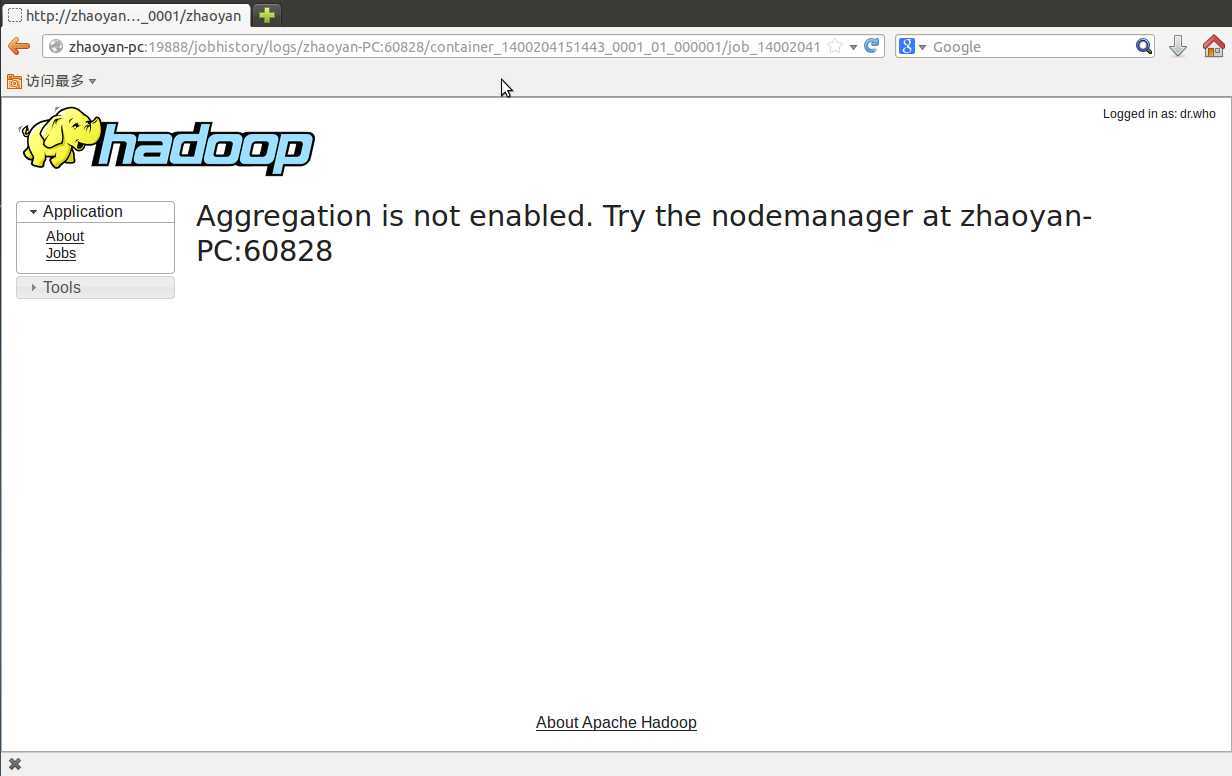
这个解决方案为:
By default, Hadoop stores the logs of each container in the node where that container was hosted. While this is irrelevant if you‘re just testing some Hadoop executions in a single-node environment (as all the logs will be in your machine anyway), with a cluster of nodes, keeping track of the logs can become quite a bother. In addition, since logs are kept on the normal filesystem, you may run into storage problems if you keep logs for a long time or have heterogeneous storage capabilities.
Log aggregation is a new feature that allows Hadoop to store the logs of each
application in a central directory in HDFS. To activate it, just add the
following to yarn-site.xmland restart the Hadoop services:

<property>
<description>Whether to enable log aggregation</description>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
By adding this option, you‘re telling Hadoop to move the application logs
to hdfs:///logs/userlogs/<your user>/<app id>. You
can change this path and other options related to log aggregation by specifying
some other properties mentioned in the default
yarn-site.xml (just do a search
for log.aggregation).
However, these aggregated logs are not
stored in a human readable format so you can‘t
just cat their contents. Fortunately, Hadoop developers
have included several handy command line tools for reading them:
# Read logs from any YARN application $HADOOP_HOME/bin/yarn logs -applicationId <applicationId> # Read logs from MapReduce jobs $HADOOP_HOME/bin/mapred job -logs <jobId> # Read it in a scrollable window with search (type ‘/‘ followed by your query). $HADOOP_HOME/bin/yarn logs -applicationId <applicationId> | less # Or just save it to a file and use your favourite editor $HADOOP_HOME/bin/yarn logs -applicationId <applicationId> > log.txt
You can also access these logs via a web app for MapReduce jobs by using the JobHistory daemon. This daemon can be started/stopped by running the following:
# Start JobHistory daemon $HADOOP_PREFIX/sbin/mr-jobhistory-daemon.sh start historyserver # Stop JobHistory daemon $HADOOP_PREFIX/sbin/mr-jobhistory-daemon.sh stop historyserver
My Fabric script includes an optional variable for setting the node where to
launch this daemon so it is automatically started/stopped when you
run fab start or fab stop.
Unfortunately, a generic history daemon for universal web access to aggregated logs does not exist yet. However, as you can see by checking YARN-321, there‘s considerable work being done in this area. When this gets introduced I‘ll update this section.
标签:des style blog class code c
原文地址:http://www.cnblogs.com/rolly-yan/p/3731734.html