标签:专项测试 方法 传统 大小 插入排序 循环引用 简单选择排序 归并 堆排
对于非运行时异常,程序中一般可不做处理,由java虚拟机自动进行处理。
A. 正确
B. 错误
解析:运行异常,可以通过java虚拟机来自行处理。非运行异常,我们应该捕获或者抛出。
答案:B
下面哪些类可以被继承? Java.lang.Thread、java.lang.Number、java.lang.Double、java.lang.Math、 java.lang.ClassLoader
A. Thread
B. Number
C. Double
D. Math
E. ClassLoader
答案:ABE
下面哪些描述是正确的:( )
public class Test {
public static class A {
private B ref;
public void setB(B b) {
ref = b;
}
}
public static Class B {
private A ref;
public void setA(A a) {
ref = a;
}
}
public static void main(String args[]) {
…
start();
….
}
public static void start() { A a = new A();
B b = new B();
a.setB(b);
b = null; //
a = null;
…
}
}A. b = null执行后b可以被垃圾回收
B. a = null执行后b可以被垃圾回收
C. a = null执行后a可以被垃圾回收
D. a,b必须在整个程序结束后才能被垃圾回收
E. 类A和类B在设计上有循环引用,会导致内存泄露
F. a, b 必须在start方法执行完毕才能被垃圾回收
解析:a引用指向一块空间,这块空间里面包含着b对象
b引用指向一块空间,这块空间是b对象
A选项,b = null执行后b可以被垃圾回收。这里"b可以被垃圾回收"中的b指的是引用b指向的内存。这块内存即使不被引用b指向,还是被引用a指向着,不会被回收。
B选项,a = null执行后b可以被垃圾回收。从代码中可以看到,a = null是在b = null后执行的,该行执行后,引用a和b都没有指向对象,对象会被回收。
C选项,同理。
答案:BC
为提高散列(Hash)表的查找效率,可以采取的正确措施是()。
Ⅰ.增大装填(载)因子
Ⅱ.设计冲突(碰撞)少的散列函数
Ⅲ.处理冲突(碰撞)时避免产生聚集(堆积)现象
A. 仅Ⅰ
B. 仅Ⅱ
C. 仅Ⅰ、Ⅱ
D. 仅Ⅱ、Ⅲ
解析:Hash表的查找效率取决于散列函数、处理冲突的方法和装填因子。显然,冲突的产生概率与装填因子(表中记录数与表长之比)的大小成正比,即装填得越满越容易发生冲突,Ⅰ错误。Ⅱ显然正确。采用合适的处理冲突的方式避免产生聚集现象,也将提高查找效率,例如用拉链法解决冲突时就不存在聚集现象,用线性探测法解决冲突时易引起聚集现象,Ⅲ正确。
答案:D
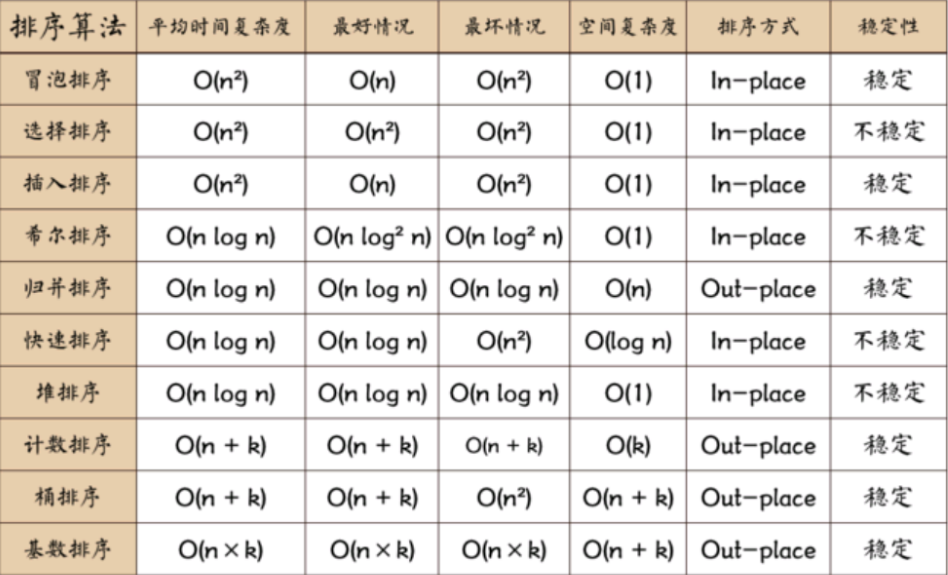
如果只想得到1000个元素组成的序列中第5个最小元素之前的部分排序的序列,用()方法最快
A. 起泡排序
B. 快速排序
C. 希尔排序
D. 堆排序
E. 简单选择排序
答案:D
用某种排序方法对关键字排序(25 、84、21、47、15、27、68、35、20)进行排序时,序列的变化情况如下:
20、15、21、25、47、27、68、35、84
15、20、21、25、35、27、47、68、84
15、20、21、25、27、35、47、68、84
则采用的排序方法是()
A. 选择排序
B. 希尔排序
C. 归并排序
D. 快速排序
解析:首先第一步以25为基础,小于25的放在25的左边,大于25的放在25的右边
得到20,15,21,25,47,27,68,35,84
第二步在25的两边分别进行快速排序,左边以20为基数,右边以47为基数
得到15,20,21,25,35,27,47,68,84
第三步将,35,27这个子序列排序,得到
15,20,21,25,27,35,47,68,84
答案:D
有些排序算法在每趟排序过程中,都会有一个元素被放置在其最终的位置上,下列算法不会出现此情况的是()
A. 希尔排序
B. 堆排序
C. 起泡排序
D. 快速排序
解析:其基本思想是先取一个小于n的整数d1作为第一个增量,把文件的全部记录分成d1个组。所有距离为dl的倍数的记录放在同一个组中。先在各组内进行直接插人排序;然后,取第二个增量d2<d1重复上述的分组和排序,直至所取的增量dt=1(dt<dt-l<…<d2<d1),即所有记录放在同一组中进行直接插入排序为止。
答案:A
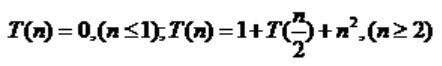
D. 以上都不正确
解析:
T(n)=1+T(n/2)+nn
=1+1+T(n/4)+nn/4+nn
=1+1+1+T(n/8)+nn/16+nn/4+nn
.....
=1+x+T(n/(2^x ))+n ^ 2(1+1/4+1/16+...+1/4^x)
=1+x+T(n/2^x)+n ^ 24/3(1+1/4^x)
令x=log2n则T(n) = 1+log2 n+T(1)+n^24/3(1+1/n^2) =1+4/3(1+n^2)+log2 n
所以答案就是A
答案:A
Hadoop 运行的模式
A. 单机版
B. 分布式
C. 中心版
D. 伪分布式
解析:Hadoop的运行模式分三种: 1, 本地运行模式 2,伪分布运行模式 3,分布式集群运行模式
答案:ABD
对10TB的数据文件进行排序,应使用的方法是 。
A. 希尔排序
B. 堆排序
C. 快速排序
D. 归并排序
解析:对于10TB的海量数据,数据不可能一次全部载入内存,传统的排序方法就不适用了,需要用到外排序的方法。外排序采用分治思想,即先对数据分块,对块内数据进行排序,然后采用归并排序的思想进行排序,得到数据的一个有序序列。
答案:D
n个数值选出最大m个数(3<m<n)的最小算法复杂度是
A. O(n)
B. O(nlogn)
C. O(logn)
D. O(mlogn)
E. O(nlogm)
F. O(mn)
解析:利用快排的patition思想,基于数组的第k个数来调整,将比第k个数小的都位于数组的左边,比第k个数大的都调整到数组的右边,这样调整后,位于数组右边的k个数最大的k个数(这k个数不一定是排好序的)
答案:A
标签:专项测试 方法 传统 大小 插入排序 循环引用 简单选择排序 归并 堆排
原文地址:https://www.cnblogs.com/l999q/p/12335567.html