标签:fit 根据 head 输入 大型 二维数组 年龄 water 机器
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。Entropy = 系统的凌乱程度,使用算法ID3, C4.5和C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念。
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
分类树(决策树)是一种十分常用的分类方法。他是一种监管学习,所谓监管学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。这样的机器学习就被称之为监督学习。(来自于百度百科)
从前有一个女人去相亲,我们用决策树来模拟他内心的相亲对象可以有机会和他见面的模型。首先这个女人第一个要求是年龄,如果比三十岁大不见,如果小于三十岁,但是又长得丑不见,如果长相通关了,又看收入如果的收入不高,对不起依旧不见,假如你是个公务员,你收入不高也可以见一下。这个模型不断的在做决策,根据条件(数据集特征)只有两个选择,不断的筛选达到分类,预测的效果。
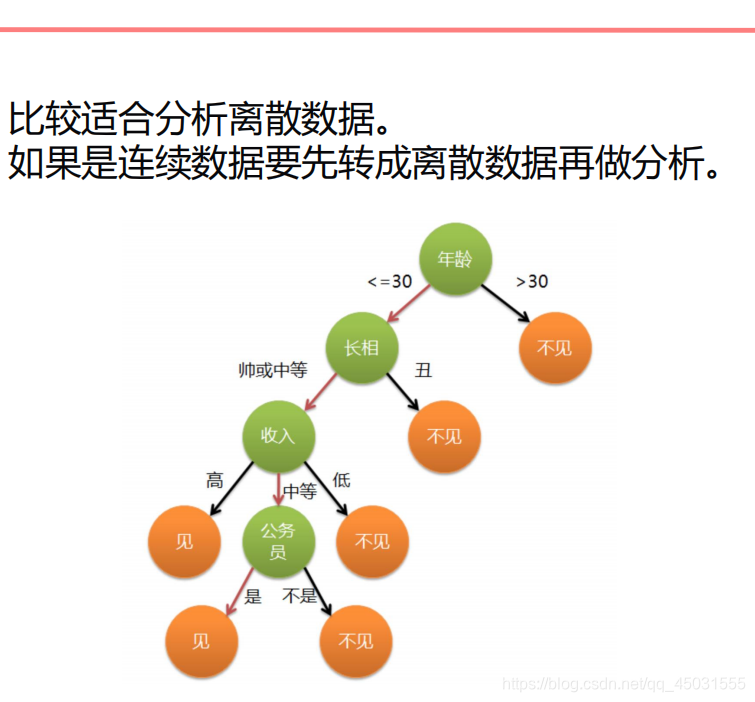
决策树易于理解和实现,人们在在学习过程中不需要使用者了解很多的背景知识,这同时是它的能够直接体现数据的特点,只要通过解释后都有能力去理解决策树所表达的意义。
对于决策树,数据的准备往往是简单或者是不必要的,而且能够同时处理数据型和常规型属性,在相对短的时间内能够对大型数据源做出可行且效果良好的结果。
易于通过静态测试来对模型进行评测,可以测定模型可信度;如果给定一个观察的模型,那么根据所产生的决策树很容易推出相应的逻辑表达式。
1)对连续性的字段比较难预测。
2)对有时间顺序的数据,需要很多预处理的工作。
3)当类别太多时,错误可能就会增加的比较快。
4)一般的算法分类的时候,只是根据一个字段来分类。
根据最近几天的学习,我意识到对于数据的处理很重要,其实好多模型在sklear库都有,我们我只要把数据切分好,把符合模型尺寸的数据放进去就可以训练,在此过程中涉及到 数据标准化,二值化,维度的改变,标签的数值化等等都是在处理数据集,数据训练模型的燃料。
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
#按照路径读入CSV文件,返回 DataFrame文件,也就是一种类似表格的数据结构
train = pd.read_csv('E:\python-ml\T.csv')
#打印这个DataFranme文件的前5行
train.head()
#反应出这个表格的大小,几行几列
train.shape
# 叶子类别数,在所有的行里面找出有多少种不同的
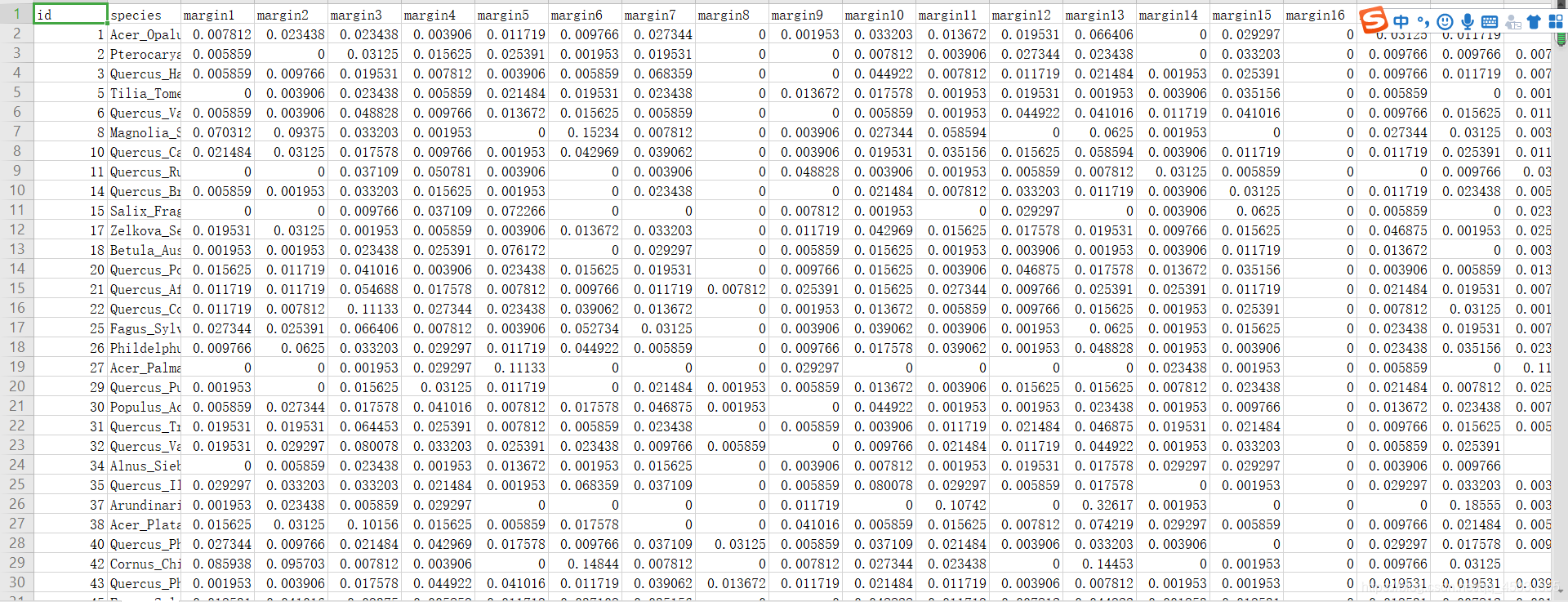
len(train.species.unique())运行截图:
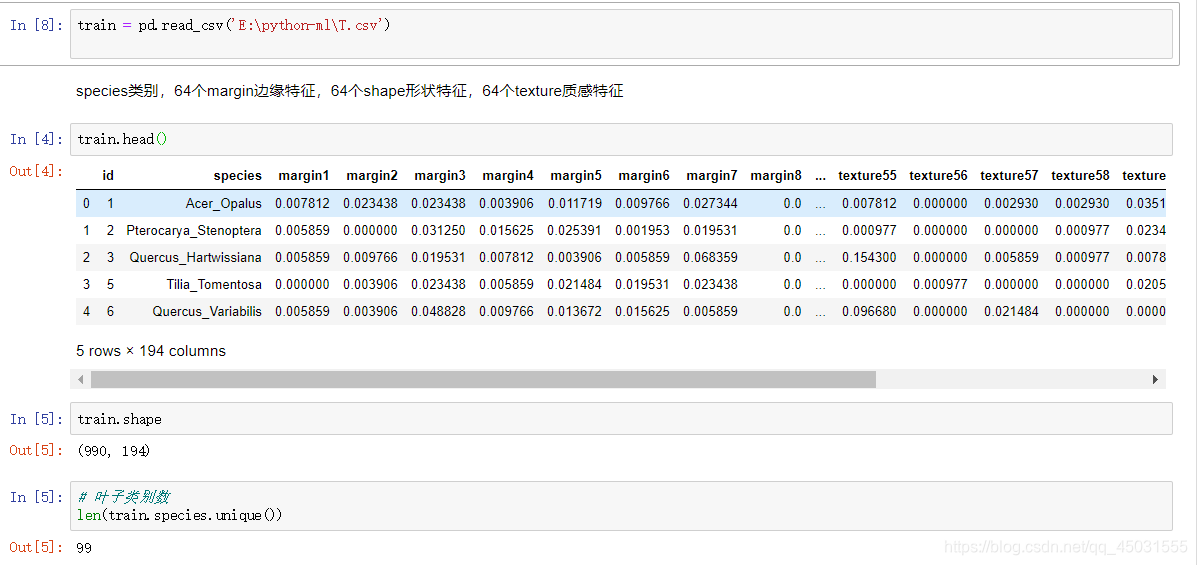
首先我们可以知道这是一个990*194的二维数组,990行里共有99种叶子,也就是每种叶子有是个样本。再看表头 有64+64+64中特征,另外两列一个是ID,一个是标签叶子种类。目前在数据集里面的叶子种类是字符串,我们得用数据标准化把他转化为数据。
# 把字符串类别转化为数字形式,这里的train.species是整个数据集的species这一列的数据
lb = LabelEncoder().fit(train.species)
labels = lb.transform(train.species)
# 去掉'species', 'id'的列
data = train.drop(['species', 'id'], axis=1)
data.head()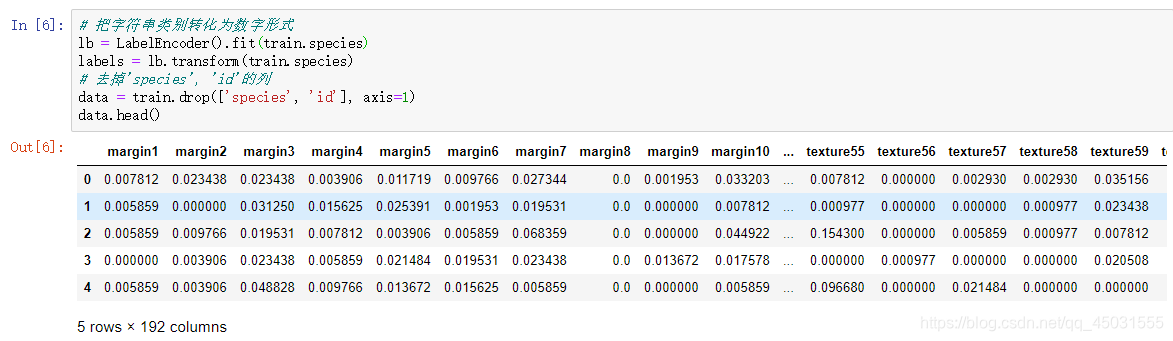
我们观察数据集里面的两列没有了。而叶子的种类也以数据的形式放在了labels里面,我们可以把labels的前五个数据打印出来看一下

#数据的切分为数据集和测试集,按照labels里面的比例
x_train,x_test,y_train,y_test = train_test_split(data, labels, test_size=0.3, stratify=labels)
#创建决策树模型
tree = DecisionTreeClassifier()
#将数据导入决策树中,训练得到模型
tree.fit(x_train, y_train)
用测试数据得到模型准确率
tree.score(x_test, y_test)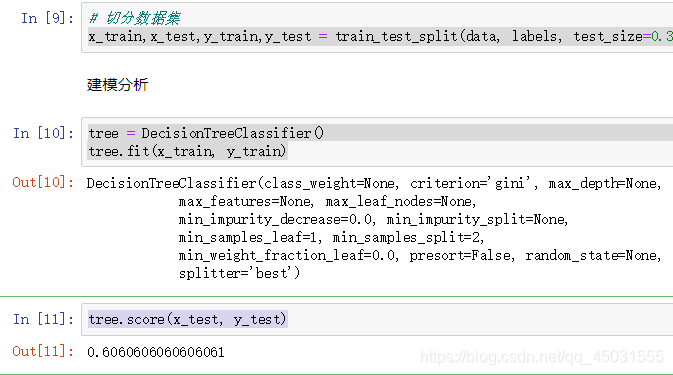
#训练集数据的情况,往往反应模型到底如何的是用test集
tree.score(x_train, y_train)
我们发现了,训练集的数据的准确度 是 1,而测试集 是 0.6
很明显出现了过拟合的情况,整个模型的结构过度拟合训练集的数据,这在决策树很常见,毕竟有192个特征。接下来我们可以尝试着把模型优化一下。
# max_depth:树的最大深度
# min_samples_split:内部节点再划分所需最小样本数
# min_samples_leaf:叶子节点最少样本数
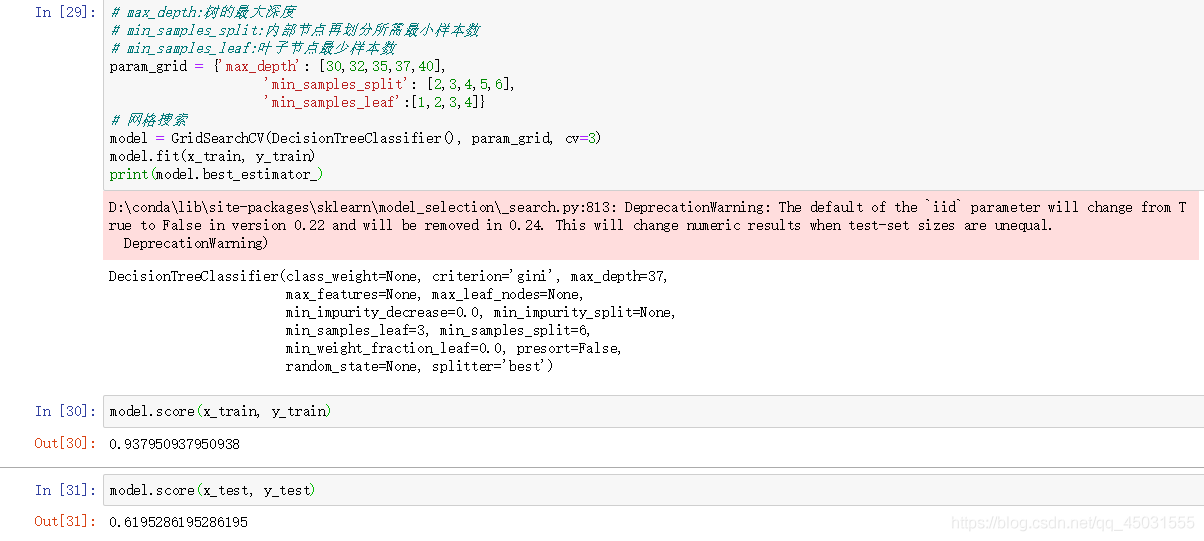
param_grid = {'max_depth': [30,40,50,60,70],
'min_samples_split': [2,3,4,5,6],
'min_samples_leaf':[1,2,3,4]}
#这些数据都设计的比较小,可以抵抗一点过拟合
# 网格搜索
model = GridSearchCV(DecisionTreeClassifier(), param_grid, cv=3)
model.fit(x_train, y_train)
print(model.best_estimator_)用通俗的话来讲呢,什么是模型预测,就像是候选人一样,再三个参数list 里面各选出一个参数,进行组合,那么就有554=100中方案,从一百个组合里面重复上面的模型训练挨个测试训练的准确性,选出准确率最高的一个。

我们可以看出来,再模型优化后,我们选出来的决策树的最大深度是 40,而最小分类徐娅哟样本数是2,叶子节点最小样本2

准确度确实提高一点,毕竟决策树来解决这样的特征很多,需要深度很深的数,准确度大概就是这样。但是我还是学到了模型优化的方法。我再自己输入一些数据尝试是否能再优化一些,不知道是我电脑卡还是这么,跑了很久。。。确实想想 每次训练一次中就有很多轮,再有一百个组合,确实需要很多时间。
决策树深度 会影响准确
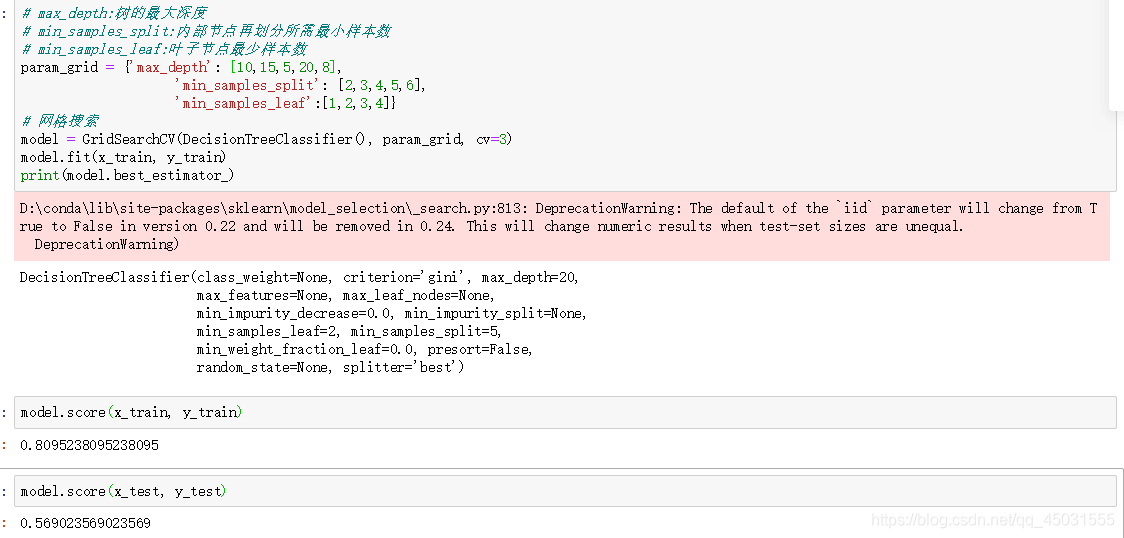
不一定越小越好,决策树本身处理特征太多就会精确度不高
标签:fit 根据 head 输入 大型 二维数组 年龄 water 机器
原文地址:https://www.cnblogs.com/Eldq/p/12335434.html