标签:rzsz 虚拟机 pac pre port 路径 软件包 ip地址 自己
1.使用hadoop是需要jdk环境的,因为hadoop里面有java程序,而运行java程序需要jdk。
2.从宿主机上传文件到虚拟机有很多方法,我选择的是在虚拟机安装lrzsz,安装lrzsz命令行:yum install -y lrzsz
3.确定好软件安装路径
/opt #工作目录
/opt/installed #安装包
/opt/software #软件包
/opt/other #其他
/opt/test #测试
4.上传软件包
cd /opt/installed
rz 从宿主机下载jdk和hadoop的tar.gz包
hadoop的下载地址:https://dist.apache.org/repos/dist/release/hadoop/common/

5.解压软件包
如果虚拟机没有安装tar 使用yum安装:yum install -y tar
tar -zxvf jdk-8u202-linux-x64.tar.gz
tar -zxvf hadoop-2.7.7.tar.gz

6.把解压的jdk和hadoop移动到/opt/software/下面
mv jdk1.8.0_202 /opt/software/
mv hadoop-2.7.7 /opt/software/
7.配置两个软件的环境变量
vi /etc/profile
i 编辑
在最下面写入

Esc 命令模式
:wq 保存
source /etc/profile
8.修改主机名(原本是localhost)
vim /etc/hostname localhost修改成hadoop101
修改主机映射
vim /etc/hosts 在最下面写入 192.168.31.54(自己的虚拟机ip地址) hadoop01(刚刚修改的主机名)
9.修改六个配置文件,全部在hadoop目录下的etc/hadoop/下面
vim hadoop-env.sh #编辑配置文件hadoop-env.sh
export JAVA_HOME=/opt/software/jdk1.8 #修改25行
export HADOOP_CONF_DIR=/opt/software/hadoop-2.7.7/etc/hadoop #修改33行
vim core-site.xml #编辑配置文件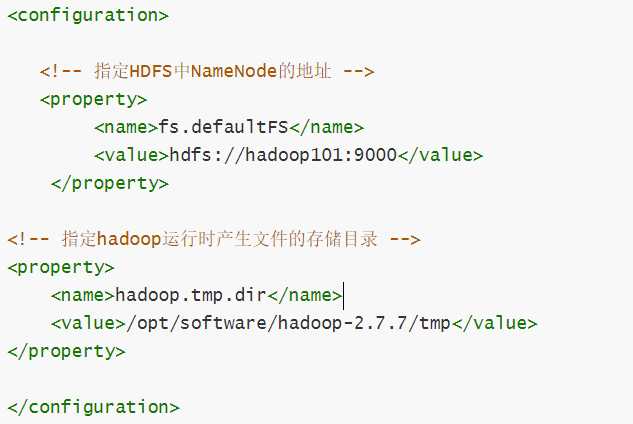
vim hdfs-site.xml #编辑配置文件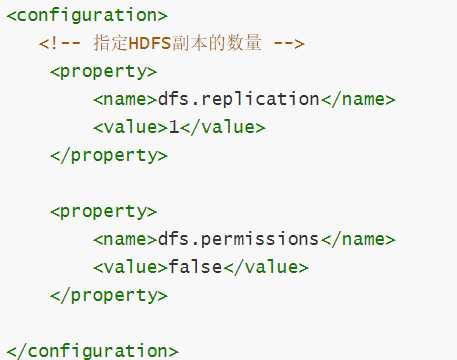
vim mapred-site.xml #编辑配置文件
vim yarn-site.xml #编辑配置文件
vim slaves #编辑配置文件
只需要写入主机名就可 hadoop10110.格式化文件系统
hadoop namenode -format
11.启动hadoop
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
13.netstat -nltp 查看hadoop启动的端口
标签:rzsz 虚拟机 pac pre port 路径 软件包 ip地址 自己
原文地址:https://www.cnblogs.com/lyx666/p/12335360.html